Safe Reinforcement Learning on the Constraint Manifold: Theory and Applications
2404.09080
0
0

Abstract
Integrating learning-based techniques, especially reinforcement learning, into robotics is promising for solving complex problems in unstructured environments. However, most existing approaches are trained in well-tuned simulators and subsequently deployed on real robots without online fine-tuning. In this setting, the simulation's realism seriously impacts the deployment's success rate. Instead, learning with real-world interaction data offers a promising alternative: not only eliminates the need for a fine-tuned simulator but also applies to a broader range of tasks where accurate modeling is unfeasible. One major problem for on-robot reinforcement learning is ensuring safety, as uncontrolled exploration can cause catastrophic damage to the robot or the environment. Indeed, safety specifications, often represented as constraints, can be complex and non-linear, making safety challenging to guarantee in learning systems. In this paper, we show how we can impose complex safety constraints on learning-based robotics systems in a principled manner, both from theoretical and practical points of view. Our approach is based on the concept of the Constraint Manifold, representing the set of safe robot configurations. Exploiting differential geometry techniques, i.e., the tangent space, we can construct a safe action space, allowing learning agents to sample arbitrary actions while ensuring safety. We demonstrate the method's effectiveness in a real-world Robot Air Hockey task, showing that our method can handle high-dimensional tasks with complex constraints. Videos of the real robot experiments are available on the project website (https://puzeliu.github.io/TRO-ATACOM).
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a novel approach to safe reinforcement learning on the constraint manifold, which aims to learn optimal policies while respecting safety constraints.
- The authors propose a theoretical framework for analyzing safe exploration and develop practical algorithms for deploying safe reinforcement learning in real-world applications.
- The proposed methods are evaluated on several benchmark tasks, including environments from the AI safety gym and a simulated bipedal robot learning soccer skills, demonstrating their effectiveness in balancing performance and safety.
Plain English Explanation
The paper discusses a new way to train reinforcement learning agents to learn optimal behaviors while ensuring they stay within certain safety boundaries. Reinforcement learning is a technique where an agent interacts with an environment, takes actions, and receives rewards or penalties. The goal is to learn a policy, or decision-making strategy, that maximizes the cumulative rewards. However, in many real-world applications, there are important safety constraints that the agent must respect, such as not damaging equipment or harming humans.
The authors propose a "safe reinforcement learning on the constraint manifold" approach, where the agent learns to navigate a "constraint manifold" - a set of states and actions that satisfy the safety requirements. This allows the agent to explore the environment and find high-performing policies, but only within the bounds of what is considered safe. The authors develop a theoretical framework to analyze this approach and design practical algorithms to implement it.
The researchers test their methods on several benchmark tasks, including simulated environments where the agent needs to learn agile soccer skills on a bipedal robot and navigate a complex multi-agent setting while respecting safety constraints. The results show that their safe reinforcement learning approach can effectively balance performance and safety, outperforming standard reinforcement learning methods that do not consider safety.
Technical Explanation
The key innovation in this paper is the concept of "safe reinforcement learning on the constraint manifold". The authors start by formalizing the problem of reinforcement learning with safety constraints, defining a constraint manifold as the set of states and actions that satisfy the safety requirements.
They then develop a theoretical framework for analyzing safe exploration on the constraint manifold. This involves deriving optimality conditions and safety certificates that characterize when an agent's behavior is both optimal and safe. The authors prove several theoretical results, including conditions for global convergence to the optimal policy while respecting safety.
Building on this theory, the authors propose practical safe reinforcement learning algorithms. These algorithms employ techniques like barrier functions and model predictive control to guide the agent's exploration and maintain safety throughout the learning process. The authors also describe how these methods can be applied to specific benchmark tasks, such as the AI safety gym environments and a simulated bipedal robot learning soccer skills.
The experimental results demonstrate that the proposed safe reinforcement learning approach can achieve high performance while respecting safety constraints, outperforming standard reinforcement learning methods that do not consider safety. The authors also discuss potential limitations and areas for future research, such as extending the methods to more complex safety constraints and real-world deployment scenarios.
Critical Analysis
The authors present a compelling approach to safe reinforcement learning that aims to balance performance and safety. The theoretical framework for analyzing safe exploration on the constraint manifold is a significant contribution, providing a principled way to reason about optimality and safety. The proposed algorithms also seem promising, leveraging techniques like barrier functions and model predictive control to guide the agent's behavior.
However, the paper does not address some potential limitations and challenges. For example, the methods rely on the ability to accurately model the safety constraints, which may be difficult in complex real-world scenarios. There are also open questions about how to handle situations where the safety constraints may be uncertain or change over time, as discussed in related work on active exploration and Bayesian model-based reinforcement learning.
Additionally, the paper focuses on safety constraints defined by the environment, but in many applications, the safety requirements may be more nuanced and involve considerations of human values and preferences. Approaches like GenChip that aim to generate policies aligned with human oversight could be a valuable complement to the techniques presented in this paper.
Overall, the safe reinforcement learning framework proposed in this work is a promising step forward, but further research is needed to address the challenges of real-world deployment and value alignment. Readers are encouraged to think critically about the strengths, limitations, and potential future directions of this line of research.
Conclusion
This paper presents a novel approach to safe reinforcement learning that aims to learn optimal policies while respecting safety constraints. The authors develop a theoretical framework for analyzing safe exploration on the constraint manifold and propose practical algorithms to implement this approach. Experimental results on benchmark tasks demonstrate the effectiveness of the proposed methods in balancing performance and safety.
The safe reinforcement learning framework introduced in this work is a significant contribution to the field, as it provides a principled way to reason about optimality and safety in reinforcement learning. The techniques presented here could have important implications for deploying reinforcement learning in safety-critical applications, such as robotics, autonomous systems, and healthcare. However, further research is needed to address the limitations and challenges discussed, particularly in the context of real-world deployment and value alignment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
A Survey of Constraint Formulations in Safe Reinforcement Learning
Akifumi Wachi, Xun Shen, Yanan Sui
0
0
Safety is critical when applying reinforcement learning (RL) to real-world problems. As a result, safe RL has emerged as a fundamental and powerful paradigm for optimizing an agent's policy while incorporating notions of safety. A prevalent safe RL approach is based on a constrained criterion, which seeks to maximize the expected cumulative reward subject to specific safety constraints. Despite recent effort to enhance safety in RL, a systematic understanding of the field remains difficult. This challenge stems from the diversity of constraint representations and little exploration of their interrelations. To bridge this knowledge gap, we present a comprehensive review of representative constraint formulations, along with a curated selection of algorithms designed specifically for each formulation. In addition, we elucidate the theoretical underpinnings that reveal the mathematical mutual relations among common problem formulations. We conclude with a discussion of the current state and future directions of safe reinforcement learning research.
5/9/2024
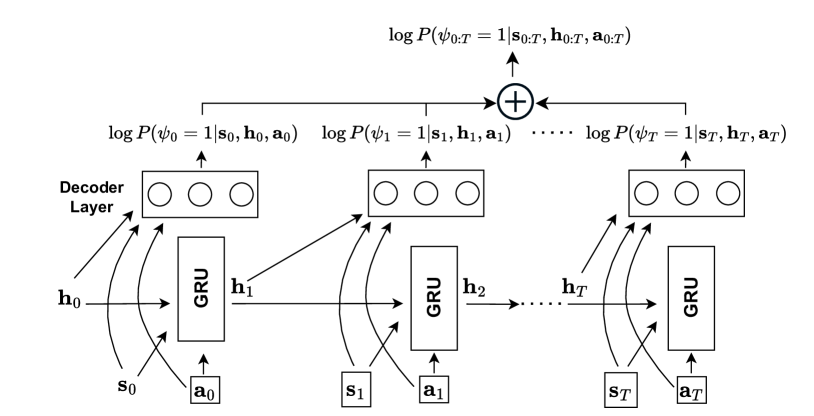
Safe Reinforcement Learning with Learned Non-Markovian Safety Constraints
Siow Meng Low, Akshat Kumar
0
0
In safe Reinforcement Learning (RL), safety cost is typically defined as a function dependent on the immediate state and actions. In practice, safety constraints can often be non-Markovian due to the insufficient fidelity of state representation, and safety cost may not be known. We therefore address a general setting where safety labels (e.g., safe or unsafe) are associated with state-action trajectories. Our key contributions are: first, we design a safety model that specifically performs credit assignment to assess contributions of partial state-action trajectories on safety. This safety model is trained using a labeled safety dataset. Second, using RL-as-inference strategy we derive an effective algorithm for optimizing a safe policy using the learned safety model. Finally, we devise a method to dynamically adapt the tradeoff coefficient between reward maximization and safety compliance. We rewrite the constrained optimization problem into its dual problem and derive a gradient-based method to dynamically adjust the tradeoff coefficient during training. Our empirical results demonstrate that this approach is highly scalable and able to satisfy sophisticated non-Markovian safety constraints.
5/7/2024
🛸
Jointly Learning Cost and Constraints from Demonstrations for Safe Trajectory Generation
Shivam Chaubey, Francesco Verdoja, Ville Kyrki
0
0
Learning from Demonstration allows robots to mimic human actions. However, these methods do not model constraints crucial to ensure safety of the learned skill. Moreover, even when explicitly modelling constraints, they rely on the assumption of a known cost function, which limits their practical usability for task with unknown cost. In this work we propose a two-step optimization process that allow to estimate cost and constraints by decoupling the learning of cost functions from the identification of unknown constraints within the demonstrated trajectories. Initially, we identify the cost function by isolating the effect of constraints on parts of the demonstrations. Subsequently, a constraint leaning method is used to identify the unknown constraints. Our approach is validated both on simulated trajectories and a real robotic manipulation task. Our experiments show the impact that incorrect cost estimation has on the learned constraints and illustrate how the proposed method is able to infer unknown constraints, such as obstacles, from demonstrated trajectories without any initial knowledge of the cost.
5/7/2024
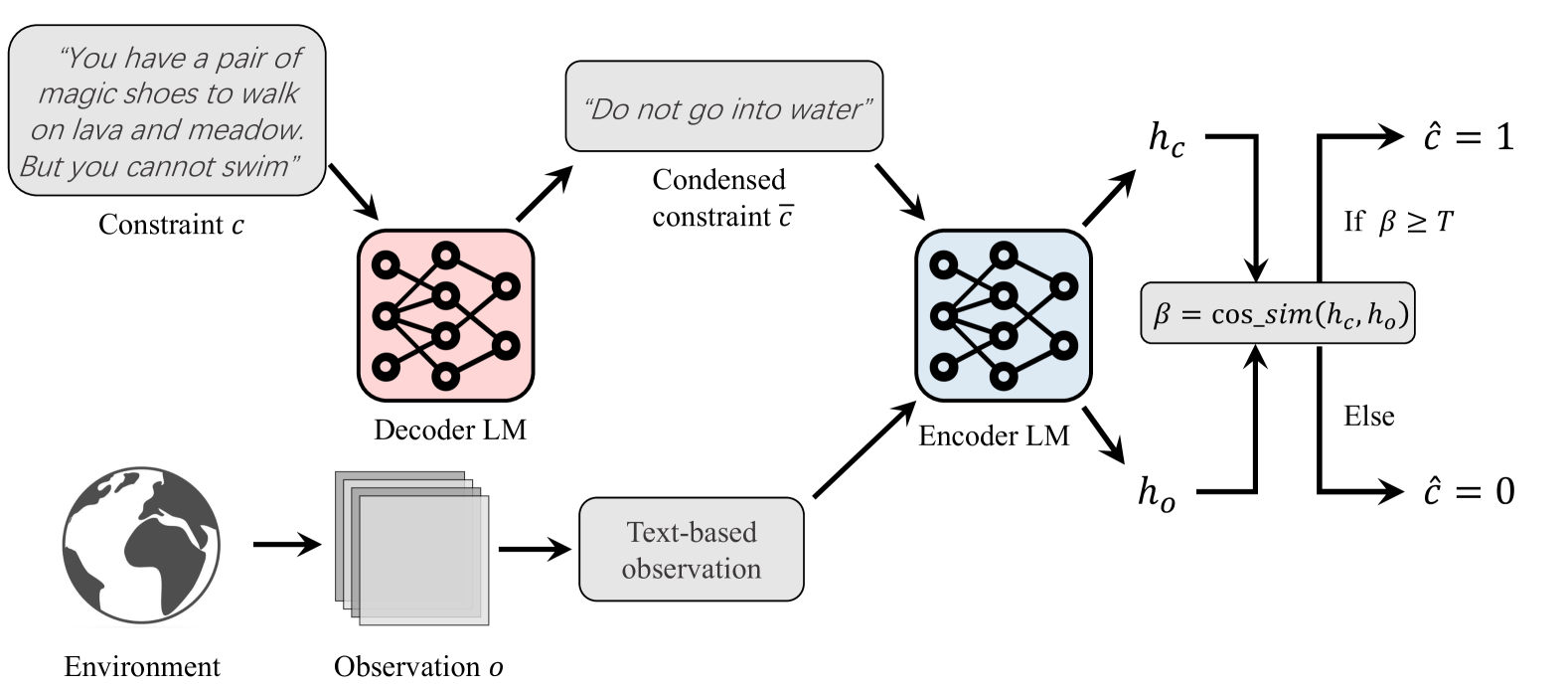
Safe Reinforcement Learning with Free-form Natural Language Constraints and Pre-Trained Language Models
Xingzhou Lou, Junge Zhang, Ziyan Wang, Kaiqi Huang, Yali Du
0
0
Safe reinforcement learning (RL) agents accomplish given tasks while adhering to specific constraints. Employing constraints expressed via easily-understandable human language offers considerable potential for real-world applications due to its accessibility and non-reliance on domain expertise. Previous safe RL methods with natural language constraints typically adopt a recurrent neural network, which leads to limited capabilities when dealing with various forms of human language input. Furthermore, these methods often require a ground-truth cost function, necessitating domain expertise for the conversion of language constraints into a well-defined cost function that determines constraint violation. To address these issues, we proposes to use pre-trained language models (LM) to facilitate RL agents' comprehension of natural language constraints and allow them to infer costs for safe policy learning. Through the use of pre-trained LMs and the elimination of the need for a ground-truth cost, our method enhances safe policy learning under a diverse set of human-derived free-form natural language constraints. Experiments on grid-world navigation and robot control show that the proposed method can achieve strong performance while adhering to given constraints. The usage of pre-trained LMs allows our method to comprehend complicated constraints and learn safe policies without the need for ground-truth cost at any stage of training or evaluation. Extensive ablation studies are conducted to demonstrate the efficacy of each part of our method.
5/16/2024