Balance Reward and Safety Optimization for Safe Reinforcement Learning: A Perspective of Gradient Manipulation
2405.01677
0
0

Abstract
Ensuring the safety of Reinforcement Learning (RL) is crucial for its deployment in real-world applications. Nevertheless, managing the trade-off between reward and safety during exploration presents a significant challenge. Improving reward performance through policy adjustments may adversely affect safety performance. In this study, we aim to address this conflicting relation by leveraging the theory of gradient manipulation. Initially, we analyze the conflict between reward and safety gradients. Subsequently, we tackle the balance between reward and safety optimization by proposing a soft switching policy optimization method, for which we provide convergence analysis. Based on our theoretical examination, we provide a safe RL framework to overcome the aforementioned challenge, and we develop a Safety-MuJoCo Benchmark to assess the performance of safe RL algorithms. Finally, we evaluate the effectiveness of our method on the Safety-MuJoCo Benchmark and a popular safe RL benchmark, Omnisafe. Experimental results demonstrate that our algorithms outperform several state-of-the-art baselines in terms of balancing reward and safety optimization.
Create account to get full access
Overview
- This paper proposes a new approach to balance reward and safety optimization for safe reinforcement learning (RL).
- The key idea is to manipulate the gradients of the reward and safety objectives to find an optimal trade-off between them.
- The authors provide theoretical analysis and experimental results to demonstrate the effectiveness of their method.
Plain English Explanation
The paper discusses the challenge of balancing reward and safety in reinforcement learning (RL) systems. RL is a type of machine learning where an agent tries to learn the best actions to take in an environment in order to maximize some reward. However, in many real-world applications, it's important not just to maximize the reward, but also to ensure the agent behaves safely and avoids harmful actions.
The authors' approach aims to find the right balance between these two competing objectives. Rather than trying to optimize the reward and safety separately, they propose manipulating the gradients - the slopes of the reward and safety functions. By carefully adjusting these gradients, they can steer the agent towards actions that are both rewarding and safe.
The paper provides a detailed mathematical analysis of this gradient manipulation technique, as well as experimental results showing it outperforms other methods for safe RL. The key insight is that by directly accounting for the trade-off between reward and safety in the optimization process, the agent can learn more effective and reliable policies.
This work builds on previous research in safe reinforcement learning, multi-agent RL control, and off-policy safe RL, helping to advance the state-of-the-art in this important area of AI safety.
Technical Explanation
The paper proposes a new approach called "Balance Reward and Safety Optimization" (BRSO) for safe reinforcement learning. The key idea is to manipulate the gradients of the reward and safety objectives to find an optimal trade-off between them.
Formally, the authors consider a constrained optimization problem where the goal is to maximize the reward function subject to safety constraints. They show that this can be reformulated as a bi-level optimization problem, where the inner level optimizes the reward while the outer level optimizes the safety.
To solve this problem, the authors introduce a gradient manipulation technique. They derive expressions for the gradients of the reward and safety objectives, and then propose a way to adjust these gradients to find the right balance. This involves introducing a set of Lagrange multipliers that control the relative importance of the two objectives.
The authors provide a theoretical analysis of their BRSO method, proving its convergence properties and analyzing the trade-offs involved. They also present experimental results on several benchmark RL tasks, showing that BRSO outperforms prior approaches like multi-constraint safe RL and constraint-conditioned policy optimization.
Critical Analysis
The authors do a commendable job of providing a rigorous theoretical foundation for their BRSO method. The gradient manipulation technique is a clever way to directly optimize the trade-off between reward and safety, rather than treating them as separate objectives.
That said, the paper does not address some important practical considerations. For example, it's not clear how sensitive the method is to the choice of hyperparameters like the Lagrange multipliers. There may also be challenges in scaling the approach to more complex, high-dimensional RL problems.
Additionally, the paper focuses solely on the single-agent setting. Extending the ideas to multi-agent scenarios, as in prior work, could be an important next step.
Overall, this is a promising contribution to the field of safe reinforcement learning. The authors have developed a theoretically-grounded approach that demonstrates improved performance on standard benchmarks. Further research is needed to address the practical limitations and scale the method to more realistic applications.
Conclusion
This paper presents a new method called "Balance Reward and Safety Optimization" (BRSO) for safe reinforcement learning. By manipulating the gradients of the reward and safety objectives, BRSO can find an optimal trade-off between these two competing goals.
The authors provide a strong theoretical analysis of their approach, as well as experimental results showing its effectiveness compared to prior safe RL methods. This work builds on and extends previous research in this important area of AI safety and control.
While the BRSO method has some practical limitations that require further investigation, it represents a valuable contribution to the field of safe reinforcement learning. As AI systems become more capable and deployed in the real world, techniques like this will be crucial for ensuring they behave in a safe and reliable manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
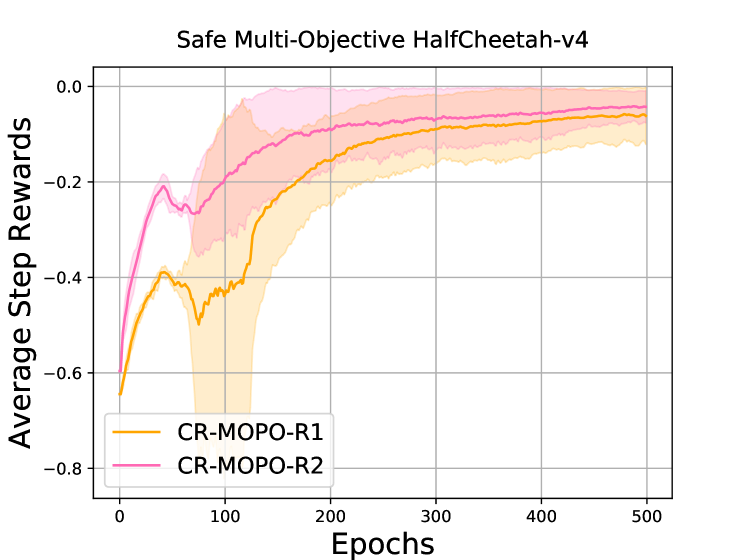
Safe and Balanced: A Framework for Constrained Multi-Objective Reinforcement Learning
Shangding Gu, Bilgehan Sel, Yuhao Ding, Lu Wang, Qingwei Lin, Alois Knoll, Ming Jin
0
0
In numerous reinforcement learning (RL) problems involving safety-critical systems, a key challenge lies in balancing multiple objectives while simultaneously meeting all stringent safety constraints. To tackle this issue, we propose a primal-based framework that orchestrates policy optimization between multi-objective learning and constraint adherence. Our method employs a novel natural policy gradient manipulation method to optimize multiple RL objectives and overcome conflicting gradients between different tasks, since the simple weighted average gradient direction may not be beneficial for specific tasks' performance due to misaligned gradients of different task objectives. When there is a violation of a hard constraint, our algorithm steps in to rectify the policy to minimize this violation. We establish theoretical convergence and constraint violation guarantees in a tabular setting. Empirically, our proposed method also outperforms prior state-of-the-art methods on challenging safe multi-objective reinforcement learning tasks.
5/28/2024

Enhancing Efficiency of Safe Reinforcement Learning via Sample Manipulation
Shangding Gu, Laixi Shi, Yuhao Ding, Alois Knoll, Costas Spanos, Adam Wierman, Ming Jin
0
0
Safe reinforcement learning (RL) is crucial for deploying RL agents in real-world applications, as it aims to maximize long-term rewards while satisfying safety constraints. However, safe RL often suffers from sample inefficiency, requiring extensive interactions with the environment to learn a safe policy. We propose Efficient Safe Policy Optimization (ESPO), a novel approach that enhances the efficiency of safe RL through sample manipulation. ESPO employs an optimization framework with three modes: maximizing rewards, minimizing costs, and balancing the trade-off between the two. By dynamically adjusting the sampling process based on the observed conflict between reward and safety gradients, ESPO theoretically guarantees convergence, optimization stability, and improved sample complexity bounds. Experiments on the Safety-MuJoCo and Omnisafe benchmarks demonstrate that ESPO significantly outperforms existing primal-based and primal-dual-based baselines in terms of reward maximization and constraint satisfaction. Moreover, ESPO achieves substantial gains in sample efficiency, requiring 25--29% fewer samples than baselines, and reduces training time by 21--38%.
6/3/2024
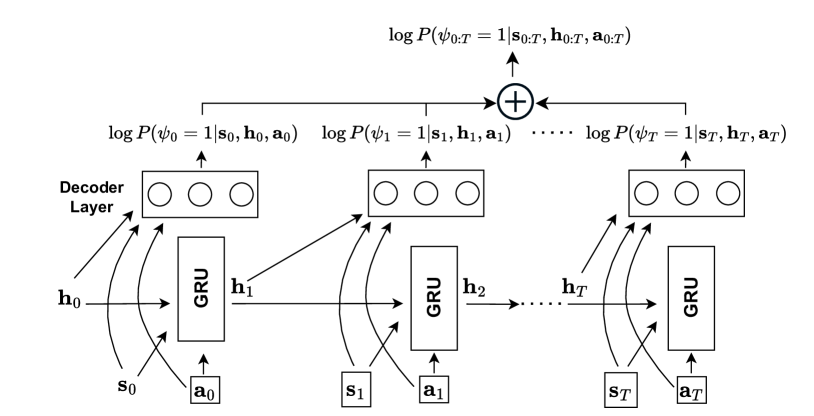
Safe Reinforcement Learning with Learned Non-Markovian Safety Constraints
Siow Meng Low, Akshat Kumar
0
0
In safe Reinforcement Learning (RL), safety cost is typically defined as a function dependent on the immediate state and actions. In practice, safety constraints can often be non-Markovian due to the insufficient fidelity of state representation, and safety cost may not be known. We therefore address a general setting where safety labels (e.g., safe or unsafe) are associated with state-action trajectories. Our key contributions are: first, we design a safety model that specifically performs credit assignment to assess contributions of partial state-action trajectories on safety. This safety model is trained using a labeled safety dataset. Second, using RL-as-inference strategy we derive an effective algorithm for optimizing a safe policy using the learned safety model. Finally, we devise a method to dynamically adapt the tradeoff coefficient between reward maximization and safety compliance. We rewrite the constrained optimization problem into its dual problem and derive a gradient-based method to dynamically adjust the tradeoff coefficient during training. Our empirical results demonstrate that this approach is highly scalable and able to satisfy sophisticated non-Markovian safety constraints.
5/7/2024
🏅
A Review of Safe Reinforcement Learning: Methods, Theory and Applications
Shangding Gu, Long Yang, Yali Du, Guang Chen, Florian Walter, Jun Wang, Alois Knoll
0
0
Reinforcement Learning (RL) has achieved tremendous success in many complex decision-making tasks. However, safety concerns are raised during deploying RL in real-world applications, leading to a growing demand for safe RL algorithms, such as in autonomous driving and robotics scenarios. While safe control has a long history, the study of safe RL algorithms is still in the early stages. To establish a good foundation for future safe RL research, in this paper, we provide a review of safe RL from the perspectives of methods, theories, and applications. Firstly, we review the progress of safe RL from five dimensions and come up with five crucial problems for safe RL being deployed in real-world applications, coined as 2H3W. Secondly, we analyze the algorithm and theory progress from the perspectives of answering the 2H3W problems. Particularly, the sample complexity of safe RL algorithms is reviewed and discussed, followed by an introduction to the applications and benchmarks of safe RL algorithms. Finally, we open the discussion of the challenging problems in safe RL, hoping to inspire future research on this thread. To advance the study of safe RL algorithms, we release an open-sourced repository containing the implementations of major safe RL algorithms at the link: https://github.com/chauncygu/Safe-Reinforcement-Learning-Baselines.git.
5/28/2024