Safe Reinforcement Learning with Free-form Natural Language Constraints and Pre-Trained Language Models
2401.07553
0
0
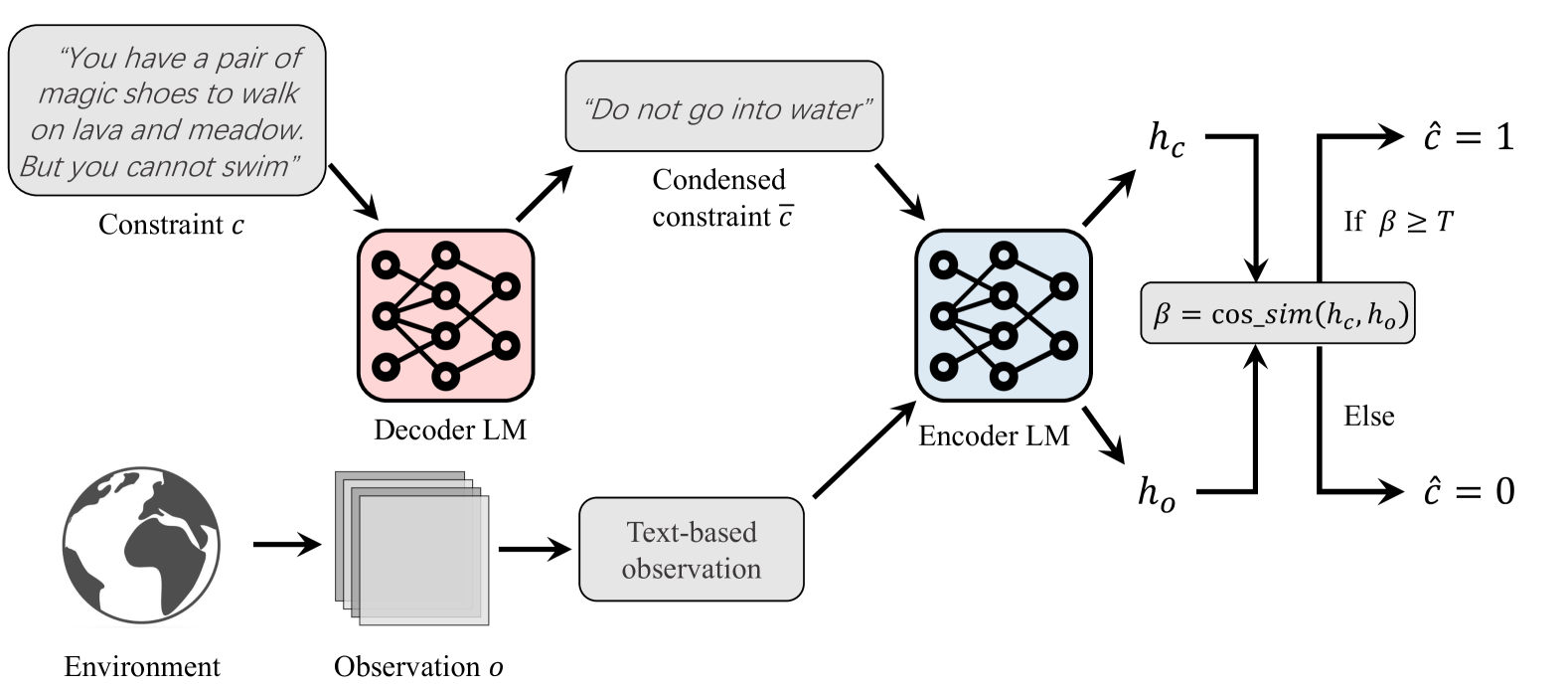
Abstract
Safe reinforcement learning (RL) agents accomplish given tasks while adhering to specific constraints. Employing constraints expressed via easily-understandable human language offers considerable potential for real-world applications due to its accessibility and non-reliance on domain expertise. Previous safe RL methods with natural language constraints typically adopt a recurrent neural network, which leads to limited capabilities when dealing with various forms of human language input. Furthermore, these methods often require a ground-truth cost function, necessitating domain expertise for the conversion of language constraints into a well-defined cost function that determines constraint violation. To address these issues, we proposes to use pre-trained language models (LM) to facilitate RL agents' comprehension of natural language constraints and allow them to infer costs for safe policy learning. Through the use of pre-trained LMs and the elimination of the need for a ground-truth cost, our method enhances safe policy learning under a diverse set of human-derived free-form natural language constraints. Experiments on grid-world navigation and robot control show that the proposed method can achieve strong performance while adhering to given constraints. The usage of pre-trained LMs allows our method to comprehend complicated constraints and learn safe policies without the need for ground-truth cost at any stage of training or evaluation. Extensive ablation studies are conducted to demonstrate the efficacy of each part of our method.
Create account to get full access
Introduction
The paper "Safe Reinforcement Learning with Free-form Natural Language Constraints and Pre-Trained Language Models" explores a novel approach to reinforcement learning (RL) that incorporates natural language constraints to ensure safer and more controlled agent behavior. The key ideas involve using pre-trained language models to interpret and enforce free-form natural language rules provided by users.
Related Work
Safe Reinforcement Learning
The paper builds on prior work in safe reinforcement learning, which aims to develop RL agents that can operate reliably and avoid undesirable or unsafe actions. By incorporating natural language constraints, this research seeks to make RL systems more interpretable and aligned with human values.
Language Models as Generalizable Policies
The use of large pre-trained language models to interpret and enforce natural language constraints is an innovative approach. These powerful language models can potentially serve as a flexible interface between humans and RL agents.
Instructable Reward Models
The natural language constraints can be seen as a form of instructable reward model, where humans can directly convey their preferences to the agent rather than relying solely on reward functions.
Natural Language as Policies
The paper also builds on research into using natural language as a way to represent and reason about policies, further blurring the line between human-understandable instructions and machine-executable behaviors.
Technical Explanation
The paper presents a framework for incorporating free-form natural language constraints into RL agents using pre-trained language models. The key components include:
- Constraint Encoder: A pre-trained language model that can interpret and encode natural language constraints into a latent representation.
- Constraint Projection: A mechanism to project the agent's current state and action into the space of satisfiable constraints, ensuring the agent's behavior aligns with the provided rules.
- Constrained Policy Optimization: An RL algorithm that optimizes the agent's policy while respecting the natural language constraints.
The authors demonstrate the effectiveness of their approach on a range of simulated environments, showing that the agents can learn to follow complex natural language rules while still achieving high rewards.
Critical Analysis
The paper presents an intriguing approach to making RL systems more interpretable and aligned with human values. By leveraging pre-trained language models, the framework allows users to specify constraints in natural language, rather than relying on rigid, predefined rules.
However, the paper also acknowledges several limitations and areas for further research. For example, the current approach assumes the natural language constraints are unambiguous and consistent, which may not always be the case in real-world scenarios. Extending the framework to handle ambiguity or conflicting constraints could be an important direction for future work.
Additionally, the paper focuses on simulated environments, and it remains to be seen how well the approach would scale to more complex, real-world tasks. Evaluating the robustness and generalization of the natural language constraints in diverse, high-stakes domains would be a valuable next step.
Conclusion
This paper offers a promising step towards integrating natural language constraints into reinforcement learning, potentially making these systems more interpretable, controllable, and aligned with human values. By leveraging the expressive power of pre-trained language models, the framework provides a flexible way for users to specify their preferences and ensure agents behave accordingly.
As the field of AI continues to advance, incorporating human-understandable instructions and constraints will be crucial for building safe and trustworthy autonomous systems. This research contributes to that important goal and opens up exciting avenues for further exploration in the intersection of language, reasoning, and reinforcement learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
Safe Multi-agent Reinforcement Learning with Natural Language Constraints
Ziyan Wang, Meng Fang, Tristan Tomilin, Fei Fang, Yali Du
0
0
The role of natural language constraints in Safe Multi-agent Reinforcement Learning (MARL) is crucial, yet often overlooked. While Safe MARL has vast potential, especially in fields like robotics and autonomous vehicles, its full potential is limited by the need to define constraints in pre-designed mathematical terms, which requires extensive domain expertise and reinforcement learning knowledge, hindering its broader adoption. To address this limitation and make Safe MARL more accessible and adaptable, we propose a novel approach named Safe Multi-agent Reinforcement Learning with Natural Language constraints (SMALL). Our method leverages fine-tuned language models to interpret and process free-form textual constraints, converting them into semantic embeddings that capture the essence of prohibited states and behaviours. These embeddings are then integrated into the multi-agent policy learning process, enabling agents to learn policies that minimize constraint violations while optimizing rewards. To evaluate the effectiveness of SMALL, we introduce the LaMaSafe, a multi-task benchmark designed to assess the performance of multiple agents in adhering to natural language constraints. Empirical evaluations across various environments demonstrate that SMALL achieves comparable rewards and significantly fewer constraint violations, highlighting its effectiveness in understanding and enforcing natural language constraints.
5/31/2024
Safe Reinforcement Learning with Learned Non-Markovian Safety Constraints
Siow Meng Low, Akshat Kumar
0
0
In safe Reinforcement Learning (RL), safety cost is typically defined as a function dependent on the immediate state and actions. In practice, safety constraints can often be non-Markovian due to the insufficient fidelity of state representation, and safety cost may not be known. We therefore address a general setting where safety labels (e.g., safe or unsafe) are associated with state-action trajectories. Our key contributions are: first, we design a safety model that specifically performs credit assignment to assess contributions of partial state-action trajectories on safety. This safety model is trained using a labeled safety dataset. Second, using RL-as-inference strategy we derive an effective algorithm for optimizing a safe policy using the learned safety model. Finally, we devise a method to dynamically adapt the tradeoff coefficient between reward maximization and safety compliance. We rewrite the constrained optimization problem into its dual problem and derive a gradient-based method to dynamically adjust the tradeoff coefficient during training. Our empirical results demonstrate that this approach is highly scalable and able to satisfy sophisticated non-Markovian safety constraints.
5/7/2024
🏅
A Survey of Constraint Formulations in Safe Reinforcement Learning
Akifumi Wachi, Xun Shen, Yanan Sui
0
0
Safety is critical when applying reinforcement learning (RL) to real-world problems. As a result, safe RL has emerged as a fundamental and powerful paradigm for optimizing an agent's policy while incorporating notions of safety. A prevalent safe RL approach is based on a constrained criterion, which seeks to maximize the expected cumulative reward subject to specific safety constraints. Despite recent effort to enhance safety in RL, a systematic understanding of the field remains difficult. This challenge stems from the diversity of constraint representations and little exploration of their interrelations. To bridge this knowledge gap, we present a comprehensive review of representative constraint formulations, along with a curated selection of algorithms designed specifically for each formulation. In addition, we elucidate the theoretical underpinnings that reveal the mathematical mutual relations among common problem formulations. We conclude with a discussion of the current state and future directions of safe reinforcement learning research.
5/9/2024

Enhancing Reinforcement Learning with Label-Sensitive Reward for Natural Language Understanding
Kuo Liao, Shuang Li, Meng Zhao, Liqun Liu, Mengge Xue, Zhenyu Hu, Honglin Han, Chengguo Yin
0
0
Recent strides in large language models (LLMs) have yielded remarkable performance, leveraging reinforcement learning from human feedback (RLHF) to significantly enhance generation and alignment capabilities. However, RLHF encounters numerous challenges, including the objective mismatch issue, leading to suboptimal performance in Natural Language Understanding (NLU) tasks. To address this limitation, we propose a novel Reinforcement Learning framework enhanced with Label-sensitive Reward (RLLR) to amplify the performance of LLMs in NLU tasks. By incorporating label-sensitive pairs into reinforcement learning, our method aims to adeptly capture nuanced label-sensitive semantic features during RL, thereby enhancing natural language understanding. Experiments conducted on five diverse foundation models across eight tasks showcase promising results. In comparison to Supervised Fine-tuning models (SFT), RLLR demonstrates an average performance improvement of 1.54%. Compared with RLHF models, the improvement averages at 0.69%. These results reveal the effectiveness of our method for LLMs in NLU tasks. Code and data available at: https://github.com/MagiaSN/ACL2024_RLLR.
5/31/2024