Jointly Learning Cost and Constraints from Demonstrations for Safe Trajectory Generation
2405.03491
0
0
🛸
Abstract
Learning from Demonstration allows robots to mimic human actions. However, these methods do not model constraints crucial to ensure safety of the learned skill. Moreover, even when explicitly modelling constraints, they rely on the assumption of a known cost function, which limits their practical usability for task with unknown cost. In this work we propose a two-step optimization process that allow to estimate cost and constraints by decoupling the learning of cost functions from the identification of unknown constraints within the demonstrated trajectories. Initially, we identify the cost function by isolating the effect of constraints on parts of the demonstrations. Subsequently, a constraint leaning method is used to identify the unknown constraints. Our approach is validated both on simulated trajectories and a real robotic manipulation task. Our experiments show the impact that incorrect cost estimation has on the learned constraints and illustrate how the proposed method is able to infer unknown constraints, such as obstacles, from demonstrated trajectories without any initial knowledge of the cost.
Create account to get full access
Overview
- Learning from Demonstration allows robots to mimic human actions, but these methods do not model crucial safety constraints.
- Even when explicitly modeling constraints, they rely on the assumption of a known cost function, which limits their practical usability for tasks with unknown cost.
- This paper proposes a two-step optimization process to estimate cost and constraints by decoupling the learning of cost functions from the identification of unknown constraints within the demonstrated trajectories.
Plain English Explanation
The paper discusses a technique called Learning from Demonstration that allows robots to learn new skills by observing and imitating human actions. While this approach can be effective, it often fails to account for important safety constraints that are crucial for the robot to operate correctly and avoid harmful behaviors.
Even when the constraints are explicitly modeled, these methods typically assume the cost function (a way of measuring the performance of the robot) is known ahead of time. This assumption can limit their usefulness for tasks where the cost function is not well-defined or understood.
To address these limitations, the researchers propose a two-step process. First, they isolate the effect of constraints on the demonstrated trajectories to learn the cost function. Then, they use a constraint learning method to identify any unknown constraints, such as obstacles, within the demonstrated trajectories without any initial knowledge of the cost.
By decoupling the learning of cost functions from the identification of constraints, this approach can more effectively learn skills from human demonstrations while ensuring the safety and reliability of the robot's behavior, even in situations where the underlying cost function is not well-understood.
Technical Explanation
The paper presents a two-step optimization process to estimate cost functions and constraints from human demonstrations of a task.
In the first step, the researchers isolate the effect of constraints on parts of the demonstrated trajectories to learn the underlying cost function. This allows them to decouple the learning of the cost function from the identification of unknown constraints.
In the second step, the researchers use a constraint learning method to identify any unknown constraints, such as obstacles, within the demonstrated trajectories. This is done without any initial knowledge of the cost function, which is a key advantage over previous approaches that relied on a known cost function.
The researchers validate their approach on both simulated trajectories and a real robotic manipulation task. Their experiments show the impact that incorrect cost estimation can have on the learned constraints, and demonstrate how their method can effectively infer unknown constraints from the demonstrated trajectories.
Critical Analysis
The paper presents a novel approach to learning from human demonstrations that addresses important limitations of previous methods. By decoupling the learning of cost functions from the identification of constraints, the researchers have developed a more flexible and practical technique for robots to acquire new skills while ensuring safety.
One potential limitation is that the method still relies on the assumption that the demonstrated trajectories contain sufficient information to infer the unknown constraints. In real-world scenarios, the demonstrations may not always capture all the relevant constraints, which could limit the effectiveness of the approach.
Additionally, the paper does not discuss how the learned cost function and constraints could be used to plan and execute new tasks. Further research may be needed to integrate this technique with safe reinforcement learning and non-Markovian safety approaches to provide comprehensive safety assurances for systems with unknown dynamics.
Overall, the paper presents a promising step towards improving learning from demonstration algorithms and ensuring the safe and reliable deployment of robotic systems.
Conclusion
This paper introduces a novel two-step optimization process that allows robots to learn cost functions and identify unknown constraints from human demonstrations of a task. By decoupling these two learning objectives, the approach can more effectively acquire new skills while ensuring the safety and reliability of the robot's behavior, even in situations where the underlying cost function is not well-understood.
The researchers have validated their method on both simulated and real-world tasks, demonstrating its ability to infer unknown constraints such as obstacles from the demonstrated trajectories. While the approach has some limitations, it represents an important step forward in the field of learning from demonstration and could have significant implications for the development of safer and more capable robotic systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Safe Reinforcement Learning on the Constraint Manifold: Theory and Applications
Puze Liu, Haitham Bou-Ammar, Jan Peters, Davide Tateo
0
0
Integrating learning-based techniques, especially reinforcement learning, into robotics is promising for solving complex problems in unstructured environments. However, most existing approaches are trained in well-tuned simulators and subsequently deployed on real robots without online fine-tuning. In this setting, the simulation's realism seriously impacts the deployment's success rate. Instead, learning with real-world interaction data offers a promising alternative: not only eliminates the need for a fine-tuned simulator but also applies to a broader range of tasks where accurate modeling is unfeasible. One major problem for on-robot reinforcement learning is ensuring safety, as uncontrolled exploration can cause catastrophic damage to the robot or the environment. Indeed, safety specifications, often represented as constraints, can be complex and non-linear, making safety challenging to guarantee in learning systems. In this paper, we show how we can impose complex safety constraints on learning-based robotics systems in a principled manner, both from theoretical and practical points of view. Our approach is based on the concept of the Constraint Manifold, representing the set of safe robot configurations. Exploiting differential geometry techniques, i.e., the tangent space, we can construct a safe action space, allowing learning agents to sample arbitrary actions while ensuring safety. We demonstrate the method's effectiveness in a real-world Robot Air Hockey task, showing that our method can handle high-dimensional tasks with complex constraints. Videos of the real robot experiments are available on the project website (https://puzeliu.github.io/TRO-ATACOM).
4/16/2024

Safety through feedback in Constrained RL
Shashank Reddy Chirra, Pradeep Varakantham, Praveen Paruchuri
0
0
In safety-critical RL settings, the inclusion of an additional cost function is often favoured over the arduous task of modifying the reward function to ensure the agent's safe behaviour. However, designing or evaluating such a cost function can be prohibitively expensive. For instance, in the domain of self-driving, designing a cost function that encompasses all unsafe behaviours (e.g. aggressive lane changes) is inherently complex. In such scenarios, the cost function can be learned from feedback collected offline in between training rounds. This feedback can be system generated or elicited from a human observing the training process. Previous approaches have not been able to scale to complex environments and are constrained to receiving feedback at the state level which can be expensive to collect. To this end, we introduce an approach that scales to more complex domains and extends to beyond state-level feedback, thus, reducing the burden on the evaluator. Inferring the cost function in such settings poses challenges, particularly in assigning credit to individual states based on trajectory-level feedback. To address this, we propose a surrogate objective that transforms the problem into a state-level supervised classification task with noisy labels, which can be solved efficiently. Additionally, it is often infeasible to collect feedback on every trajectory generated by the agent, hence, two fundamental questions arise: (1) Which trajectories should be presented to the human? and (2) How many trajectories are necessary for effective learning? To address these questions, we introduce textit{novelty-based sampling} that selectively involves the evaluator only when the the agent encounters a textit{novel} trajectory. We showcase the efficiency of our method through experimentation on several benchmark Safety Gymnasium environments and realistic self-driving scenarios.
7/1/2024
Imitating Cost-Constrained Behaviors in Reinforcement Learning
Qian Shao, Pradeep Varakantham, Shih-Fen Cheng
0
0
Complex planning and scheduling problems have long been solved using various optimization or heuristic approaches. In recent years, imitation learning that aims to learn from expert demonstrations has been proposed as a viable alternative to solving these problems. Generally speaking, imitation learning is designed to learn either the reward (or preference) model or directly the behavioral policy by observing the behavior of an expert. Existing work in imitation learning and inverse reinforcement learning has focused on imitation primarily in unconstrained settings (e.g., no limit on fuel consumed by the vehicle). However, in many real-world domains, the behavior of an expert is governed not only by reward (or preference) but also by constraints. For instance, decisions on self-driving delivery vehicles are dependent not only on the route preferences/rewards (depending on past demand data) but also on the fuel in the vehicle and the time available. In such problems, imitation learning is challenging as decisions are not only dictated by the reward model but are also dependent on a cost-constrained model. In this paper, we provide multiple methods that match expert distributions in the presence of trajectory cost constraints through (a) Lagrangian-based method; (b) Meta-gradients to find a good trade-off between expected return and minimizing constraint violation; and (c) Cost-violation-based alternating gradient. We empirically show that leading imitation learning approaches imitate cost-constrained behaviors poorly and our meta-gradient-based approach achieves the best performance.
5/24/2024
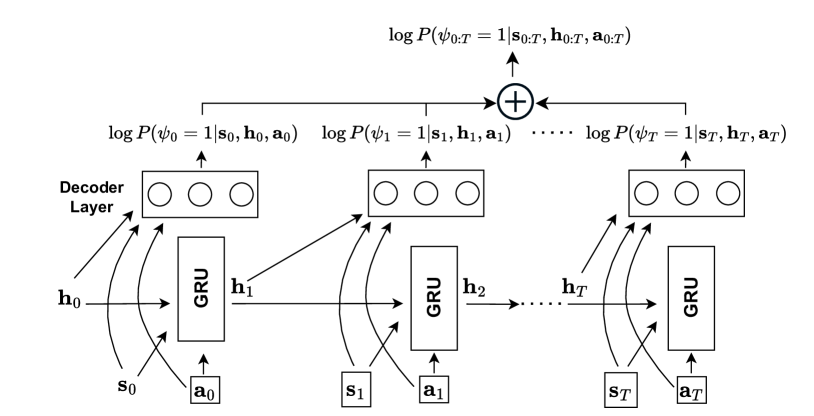
Safe Reinforcement Learning with Learned Non-Markovian Safety Constraints
Siow Meng Low, Akshat Kumar
0
0
In safe Reinforcement Learning (RL), safety cost is typically defined as a function dependent on the immediate state and actions. In practice, safety constraints can often be non-Markovian due to the insufficient fidelity of state representation, and safety cost may not be known. We therefore address a general setting where safety labels (e.g., safe or unsafe) are associated with state-action trajectories. Our key contributions are: first, we design a safety model that specifically performs credit assignment to assess contributions of partial state-action trajectories on safety. This safety model is trained using a labeled safety dataset. Second, using RL-as-inference strategy we derive an effective algorithm for optimizing a safe policy using the learned safety model. Finally, we devise a method to dynamically adapt the tradeoff coefficient between reward maximization and safety compliance. We rewrite the constrained optimization problem into its dual problem and derive a gradient-based method to dynamically adjust the tradeoff coefficient during training. Our empirical results demonstrate that this approach is highly scalable and able to satisfy sophisticated non-Markovian safety constraints.
5/7/2024