A safety realignment framework via subspace-oriented model fusion for large language models

0
Sign in to get full access
Overview
- This paper proposes a safety realignment framework for large language models (LLMs) using subspace-oriented model fusion.
- The framework aims to improve the safety and controllability of LLMs by aligning them with desired behaviors and capabilities.
- It involves fusing an LLM with a smaller model trained on safety-critical objectives to create a hybrid model with enhanced safety properties.
Plain English Explanation
The paper introduces a new approach to making large language models (LLMs) safer and more controllable. LLMs are powerful AI systems that can generate human-like text, but they can also produce harmful or biased content if not properly controlled.
The key idea is to "fuse" the LLM with a smaller, specialized model that has been trained to prioritize safety and responsible behavior. This creates a hybrid model that retains the capabilities of the original LLM, but with enhanced safety features and a stronger alignment with desired goals and values.
The process works by identifying important "subspaces" or regions within the LLM's internal representation, and then selectively adjusting those subspaces to better match the safety-focused model. This allows the system to maintain much of the LLM's original knowledge and capabilities, while significantly improving its safety and controllability.
This approach builds on previous work in the field of AI safety alignment, which aims to ensure that powerful AI systems behave in ways that are beneficial to humans. By fusing the LLM with a safety-oriented model, the researchers hope to create LLMs that are more reliable, trustworthy, and aligned with human values.
Technical Explanation
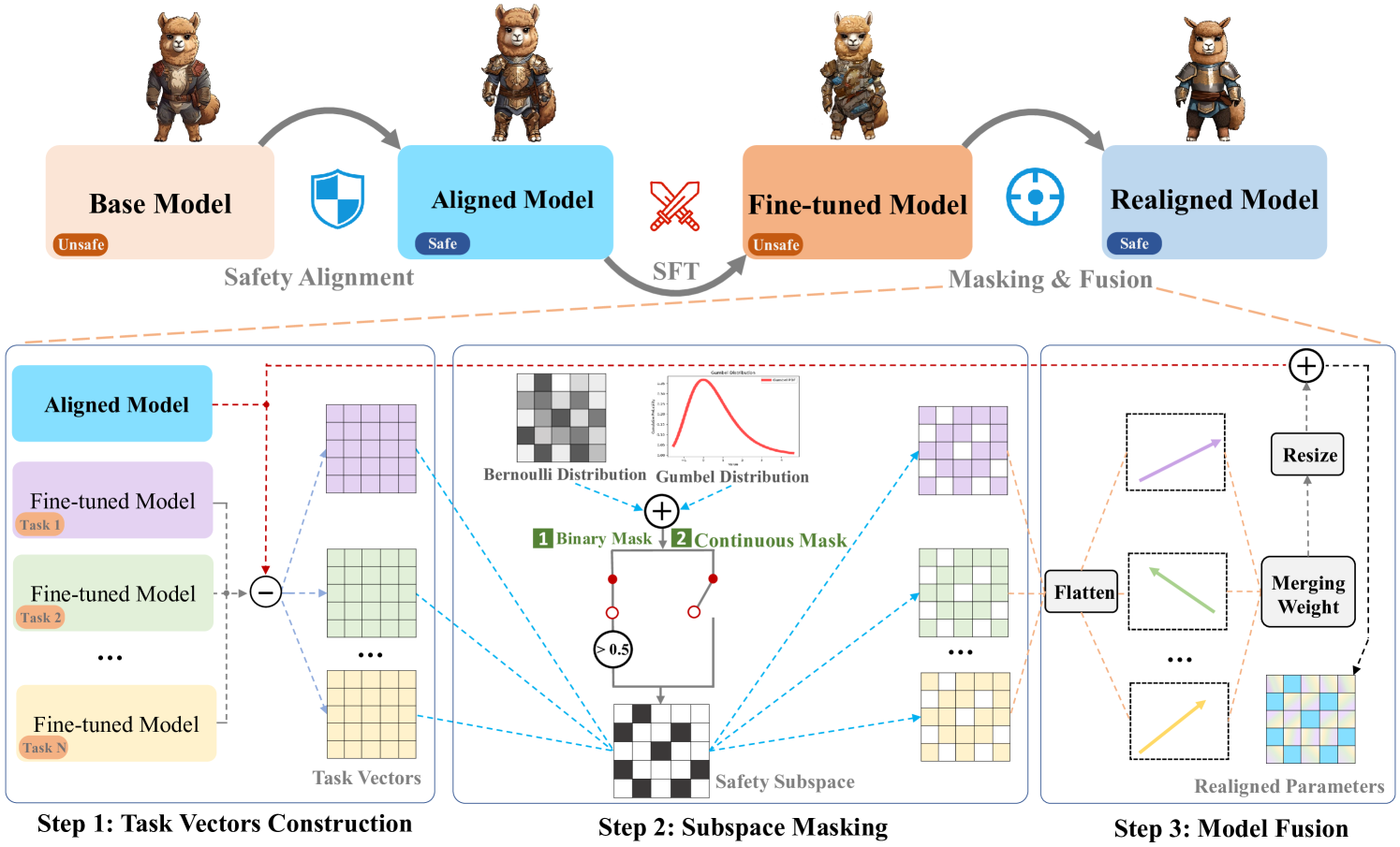
The paper proposes a framework for real-time safeguarding of text generation in large language models, which involves a process called "subspace-oriented model fusion." This approach aims to improve the safety and controllability of LLMs by selectively aligning their internal representations with those of a smaller, safety-focused model.
The key steps of the framework are:
- Subspace Identification: The researchers identify important "subspaces" within the LLM's internal representations that are relevant to safety-critical behaviors.
- Safety Model Training: A smaller, specialized model is trained on safety-critical objectives, such as avoiding the generation of harmful or biased content.
- Model Fusion: The LLM and the safety model are fused together, with the safety model's representations selectively overriding those of the LLM in the identified subspaces.
This fusion process allows the hybrid model to retain much of the original LLM's knowledge and capabilities, while incorporating the safety-focused behavior of the smaller model. The researchers demonstrate the effectiveness of this approach through experiments on benchmark tasks and real-world safety evaluations.
Critical Analysis
The paper presents a promising approach to developing safe and responsible large language models, and the authors have carefully addressed several potential limitations and areas for further research.
One potential concern is the scalability of the framework, as the fusion process may become computationally intensive as the size of the LLM and the safety model increase. The authors acknowledge this challenge and suggest that further research is needed to optimize the fusion process for larger-scale models.
Additionally, the paper does not provide a comprehensive benchmark assessment of the safety and capabilities of the resulting hybrid model. While the experiments demonstrate improvements in certain safety-critical metrics, a more thorough online safety analysis would be valuable to fully understand the model's capabilities and limitations.
Overall, the proposed framework represents an important step forward in the quest for developing safe and responsible large language models, and the authors have presented a well-designed and thoughtful approach to the problem. Further research and evaluation will be crucial to refine and scale this approach for real-world deployment.
Conclusion
This paper introduces a novel safety realignment framework that uses subspace-oriented model fusion to enhance the safety and controllability of large language models. By selectively aligning the LLM's internal representations with those of a smaller, safety-focused model, the researchers have developed a promising approach to creating more reliable and trustworthy AI systems.
The framework's ability to maintain the original LLM's capabilities while improving its safety properties is a significant advancement in the field of AI safety alignment. As large language models continue to grow in power and influence, frameworks like this will be crucial for ensuring that these systems are deployed in a responsible and beneficial manner.
While the paper identifies some areas for further research and optimization, the proposed approach represents an important step forward in the development of safe and responsible large language models that can be deployed with confidence in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A safety realignment framework via subspace-oriented model fusion for large language models
Xin Yi, Shunfan Zheng, Linlin Wang, Xiaoling Wang, Liang He
The current safeguard mechanisms for large language models (LLMs) are indeed susceptible to jailbreak attacks, making them inherently fragile. Even the process of fine-tuning on apparently benign data for downstream tasks can jeopardize safety. One potential solution is to conduct safety fine-tuning subsequent to downstream fine-tuning. However, there's a risk of catastrophic forgetting during safety fine-tuning, where LLMs may regain safety measures but lose the task-specific knowledge acquired during downstream fine-tuning. In this paper, we introduce a safety realignment framework through subspace-oriented model fusion (SOMF), aiming to combine the safeguard capabilities of initially aligned model and the current fine-tuned model into a realigned model. Our approach begins by disentangling all task vectors from the weights of each fine-tuned model. We then identify safety-related regions within these vectors by subspace masking techniques. Finally, we explore the fusion of the initial safely aligned LLM with all task vectors based on the identified safety subspace. We validate that our safety realignment framework satisfies the safety requirements of a single fine-tuned model as well as multiple models during their fusion. Our findings confirm that SOMF preserves safety without notably compromising performance on downstream tasks, including instruction following in Chinese, English, and Hindi, as well as problem-solving capabilities in Code and Math.
Read more5/16/2024
0
Safety Layers of Aligned Large Language Models: The Key to LLM Security
Shen Li, Liuyi Yao, Lan Zhang, Yaliang Li
Aligned LLMs are highly secure, capable of recognizing and refusing to answer malicious questions. However, the role of internal parameters in maintaining this security is not well understood, further these models are vulnerable to security degradation when fine-tuned with non-malicious backdoor data or normal data. To address these challenges, our work uncovers the mechanism behind security in aligned LLMs at the parameter level, identifying a small set of contiguous layers in the middle of the model that are crucial for distinguishing malicious queries from normal ones, referred to as safety layers. We first confirm the existence of these safety layers by analyzing variations in input vectors within the model's internal layers. Additionally, we leverage the over-rejection phenomenon and parameters scaling analysis to precisely locate the safety layers. Building on this understanding, we propose a novel fine-tuning approach, Safely Partial-Parameter Fine-Tuning (SPPFT), that fixes the gradient of the safety layers during fine-tuning to address the security degradation. Our experiments demonstrate that this approach significantly preserves model security while maintaining performance and reducing computational resources compared to full fine-tuning.
Read more9/2/2024
👀
0
Safety Fine-Tuning at (Almost) No Cost: A Baseline for Vision Large Language Models
Yongshuo Zong, Ondrej Bohdal, Tingyang Yu, Yongxin Yang, Timothy Hospedales
Current vision large language models (VLLMs) exhibit remarkable capabilities yet are prone to generate harmful content and are vulnerable to even the simplest jailbreaking attacks. Our initial analysis finds that this is due to the presence of harmful data during vision-language instruction fine-tuning, and that VLLM fine-tuning can cause forgetting of safety alignment previously learned by the underpinning LLM. To address this issue, we first curate a vision-language safe instruction-following dataset VLGuard covering various harmful categories. Our experiments demonstrate that integrating this dataset into standard vision-language fine-tuning or utilizing it for post-hoc fine-tuning effectively safety aligns VLLMs. This alignment is achieved with minimal impact on, or even enhancement of, the models' helpfulness. The versatility of our safety fine-tuning dataset makes it a valuable resource for safety-testing existing VLLMs, training new models or safeguarding pre-trained VLLMs. Empirical results demonstrate that fine-tuned VLLMs effectively reject unsafe instructions and substantially reduce the success rates of several black-box adversarial attacks, which approach zero in many cases. The code and dataset are available at https://github.com/ys-zong/VLGuard.
Read more6/19/2024
0
Safety Alignment Should Be Made More Than Just a Few Tokens Deep
Xiangyu Qi, Ashwinee Panda, Kaifeng Lyu, Xiao Ma, Subhrajit Roy, Ahmad Beirami, Prateek Mittal, Peter Henderson
The safety alignment of current Large Language Models (LLMs) is vulnerable. Relatively simple attacks, or even benign fine-tuning, can jailbreak aligned models. We argue that many of these vulnerabilities are related to a shared underlying issue: safety alignment can take shortcuts, wherein the alignment adapts a model's generative distribution primarily over only its very first few output tokens. We refer to this issue as shallow safety alignment. In this paper, we present case studies to explain why shallow safety alignment can exist and provide evidence that current aligned LLMs are subject to this issue. We also show how these findings help explain multiple recently discovered vulnerabilities in LLMs, including the susceptibility to adversarial suffix attacks, prefilling attacks, decoding parameter attacks, and fine-tuning attacks. Importantly, we discuss how this consolidated notion of shallow safety alignment sheds light on promising research directions for mitigating these vulnerabilities. For instance, we show that deepening the safety alignment beyond just the first few tokens can often meaningfully improve robustness against some common exploits. Finally, we design a regularized finetuning objective that makes the safety alignment more persistent against fine-tuning attacks by constraining updates on initial tokens. Overall, we advocate that future safety alignment should be made more than just a few tokens deep.
Read more6/11/2024