SAFNet: Selective Alignment Fusion Network for Efficient HDR Imaging

0

Sign in to get full access
Overview
- Introduces SAFNet, a selective alignment fusion network for efficient HDR imaging
- Focuses on tackling the challenges of large motion and aligning low-exposure and high-exposure images
- Proposes a novel fusion approach to combine selectively aligned features for high-quality HDR reconstruction
Plain English Explanation
The paper presents a new method called SAFNet, or the Selective Alignment Fusion Network, for efficiently creating high-dynamic range (HDR) images from a set of low and high-exposure photos.
The key challenge in HDR imaging is aligning the low and high-exposure images, especially when there is a lot of motion in the scene. SAFNet addresses this by selectively aligning only the relevant features between the images, rather than trying to align everything. This selective alignment helps preserve important details and avoids blurring or artifacts caused by misalignment.
After the selective alignment, SAFNet then uses a novel fusion approach to combine the selectively aligned features into a final high-quality HDR output. This fusion step allows the network to focus on preserving the most important information from each input image.
The end result is an efficient HDR imaging system that can handle scenes with large motion and produce high-quality HDR photos, without the computational complexity of aligning the entire image. This makes it a promising approach for practical HDR applications on resource-constrained devices.
Technical Explanation
The paper introduces the SAFNet architecture, which consists of three key components:
-
Selective Alignment Module: This module selectively aligns features between the low and high-exposure input images, focusing only on the most relevant regions rather than trying to align the entire image. This helps preserve important details while avoiding blurring from misalignment.
-
Fusion Module: After selective alignment, the fusion module combines the selectively aligned features in an intelligent way to produce the final HDR output. This fusion step allows the network to emphasize the most crucial information from each input.
-
Lightweight Backbone: The overall SAFNet architecture is designed to be computationally efficient, using a lightweight backbone network to enable practical HDR imaging on resource-constrained devices.
The paper demonstrates the effectiveness of SAFNet through extensive experiments on public HDR datasets, showing that it outperforms state-of-the-art HDR reconstruction methods in terms of both quality and efficiency.
Critical Analysis
The paper does a good job of identifying and addressing key challenges in HDR imaging, such as large motion and the need for efficient algorithms. The proposed SAFNet architecture seems to be a promising solution, with its selective alignment and intelligent fusion approach.
However, the paper does not delve deeply into the potential limitations or caveats of the method. For example, it would be helpful to understand how SAFNet might perform on more complex scenes with extensive motion or challenging lighting conditions. Additionally, the paper could have explored potential failure cases or edge cases where the selective alignment might not work as well.
Further research could also investigate ways to further improve the efficiency of SAFNet, such as by exploring more lightweight backbone architectures or techniques for reducing the computational requirements. Comparisons to other efficient HDR methods would also help provide a more comprehensive understanding of SAFNet's strengths and weaknesses.
Conclusion
The SAFNet paper presents an innovative approach to efficient HDR imaging that addresses the challenges of large motion and aligning low and high-exposure images. By selectively aligning features and using a novel fusion technique, the method is able to produce high-quality HDR outputs while maintaining computational efficiency.
This work demonstrates the potential for selective and intelligent processing techniques to enable practical HDR applications on resource-constrained devices. As the demand for HDR imaging continues to grow, especially in mobile and embedded applications, methods like SAFNet could play an important role in making HDR technology more accessible and usable in real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SAFNet: Selective Alignment Fusion Network for Efficient HDR Imaging
Lingtong Kong, Bo Li, Yike Xiong, Hao Zhang, Hong Gu, Jinwei Chen
Multi-exposure High Dynamic Range (HDR) imaging is a challenging task when facing truncated texture and complex motion. Existing deep learning-based methods have achieved great success by either following the alignment and fusion pipeline or utilizing attention mechanism. However, the large computation cost and inference delay hinder them from deploying on resource limited devices. In this paper, to achieve better efficiency, a novel Selective Alignment Fusion Network (SAFNet) for HDR imaging is proposed. After extracting pyramid features, it jointly refines valuable area masks and cross-exposure motion in selected regions with shared decoders, and then fuses high quality HDR image in an explicit way. This approach can focus the model on finding valuable regions while estimating their easily detectable and meaningful motion. For further detail enhancement, a lightweight refine module is introduced which enjoys privileges from previous optical flow, selection masks and initial prediction. Moreover, to facilitate learning on samples with large motion, a new window partition cropping method is presented during training. Experiments on public and newly developed challenging datasets show that proposed SAFNet not only exceeds previous SOTA competitors quantitatively and qualitatively, but also runs order of magnitude faster. Code and dataset is available at https://github.com/ltkong218/SAFNet.
Read more7/24/2024
0
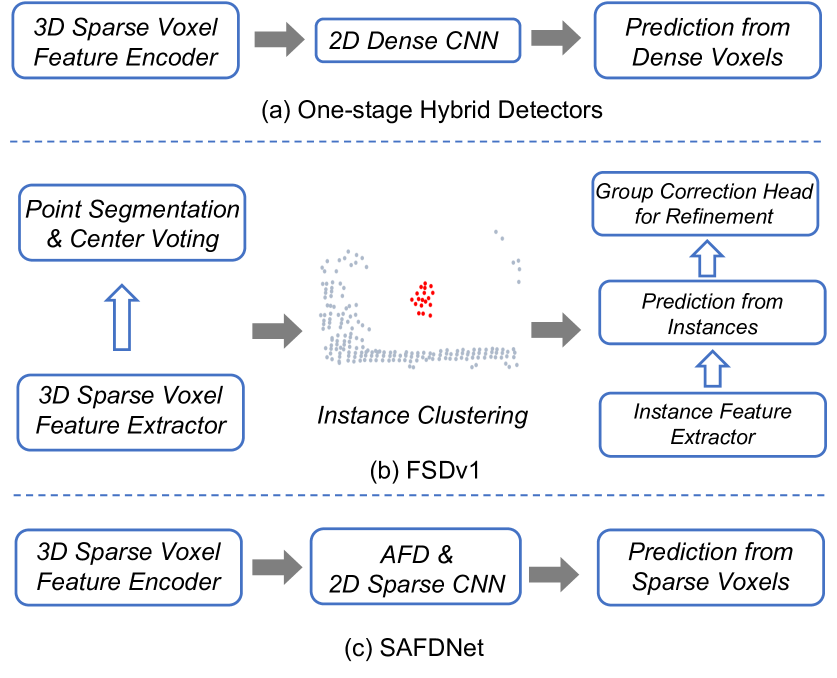
SAFDNet: A Simple and Effective Network for Fully Sparse 3D Object Detection
Gang Zhang, Junnan Chen, Guohuan Gao, Jianmin Li, Si Liu, Xiaolin Hu
LiDAR-based 3D object detection plays an essential role in autonomous driving. Existing high-performing 3D object detectors usually build dense feature maps in the backbone network and prediction head. However, the computational costs introduced by the dense feature maps grow quadratically as the perception range increases, making these models hard to scale up to long-range detection. Some recent works have attempted to construct fully sparse detectors to solve this issue; nevertheless, the resulting models either rely on a complex multi-stage pipeline or exhibit inferior performance. In this work, we propose SAFDNet, a straightforward yet highly effective architecture, tailored for fully sparse 3D object detection. In SAFDNet, an adaptive feature diffusion strategy is designed to address the center feature missing problem. We conducted extensive experiments on Waymo Open, nuScenes, and Argoverse2 datasets. SAFDNet performed slightly better than the previous SOTA on the first two datasets but much better on the last dataset, which features long-range detection, verifying the efficacy of SAFDNet in scenarios where long-range detection is required. Notably, on Argoverse2, SAFDNet surpassed the previous best hybrid detector HEDNet by 2.6% mAP while being 2.1x faster, and yielded 2.1% mAP gains over the previous best sparse detector FSDv2 while being 1.3x faster. The code will be available at https://github.com/zhanggang001/HEDNet.
Read more4/23/2024
🏋️
0
FastHDRNet: A new efficient method for SDR-to-HDR Translation
Siyuan Tian, Hao Wang, Yiren Rong, Junhao Wang, Renjie Dai, Zhengxiao He
Modern displays nowadays possess the capability to render video content with a high dynamic range (HDR) and an extensive color gamut .However, the majority of available resources are still in standard dynamic range (SDR). Therefore, we need to identify an effective methodology for this objective.The existing deep neural networks (DNN) based SDR to HDR conversion methods outperforms conventional methods, but they are either too large to implement or generate some terrible artifacts. We propose a neural network for SDR to HDR conversion, termed FastHDRNet. This network includes two parts, Adaptive Universal Color Transformation (AUCT) and Local Enhancement (LE). The architecture is designed as a lightweight network that utilizes global statistics and local information with super high efficiency. After the experiment, we find that our proposed method achieves state-of-the-art performance in both quantitative comparisons and visual quality with a lightweight structure and a enhanced infer speed.
Read more5/14/2024
🖼️
0
Searching a Compact Architecture for Robust Multi-Exposure Image Fusion
Zhu Liu, Jinyuan Liu, Guanyao Wu, Zihang Chen, Xin Fan, Risheng Liu
In recent years, learning-based methods have achieved significant advancements in multi-exposure image fusion. However, two major stumbling blocks hinder the development, including pixel misalignment and inefficient inference. Reliance on aligned image pairs in existing methods causes susceptibility to artifacts due to device motion. Additionally, existing techniques often rely on handcrafted architectures with huge network engineering, resulting in redundant parameters, adversely impacting inference efficiency and flexibility. To mitigate these limitations, this study introduces an architecture search-based paradigm incorporating self-alignment and detail repletion modules for robust multi-exposure image fusion. Specifically, targeting the extreme discrepancy of exposure, we propose the self-alignment module, leveraging scene relighting to constrain the illumination degree for following alignment and feature extraction. Detail repletion is proposed to enhance the texture details of scenes. Additionally, incorporating a hardware-sensitive constraint, we present the fusion-oriented architecture search to explore compact and efficient networks for fusion. The proposed method outperforms various competitive schemes, achieving a noteworthy 3.19% improvement in PSNR for general scenarios and an impressive 23.5% enhancement in misaligned scenarios. Moreover, it significantly reduces inference time by 69.1%. The code will be available at https://github.com/LiuZhu-CV/CRMEF.
Read more8/27/2024