SAFDNet: A Simple and Effective Network for Fully Sparse 3D Object Detection

0
Sign in to get full access
Overview
- Proposes a simple and effective network called SAFDNet for fully sparse 3D object detection
- Leverages sparse point cloud data to efficiently detect 3D objects
- Aims to enhance existing sparse object detection methods
Plain English Explanation
SAFDNet is a new deep learning model designed for 3D object detection using sparse point cloud data. Unlike traditional 3D object detectors that process dense 3D data, SAFDNet focuses on efficiently processing sparse point clouds, which are common in many real-world 3D sensing applications like self-driving cars and robotics.
The key innovation of SAFDNet is its ability to effectively detect 3D objects from sparse inputs, without requiring a dense 3D representation. This makes it computationally efficient and well-suited for real-time applications. By leveraging sparse points to enhance 3D object detection, SAFDNet aims to advance the state-of-the-art in robust LiDAR-based 3D object detection.
The research also explores ways to enhance multi-view 3D object detection and develop robust multi-modal 3D object detection - two important areas in 3D perception that could benefit from efficient sparse point cloud processing.
Technical Explanation
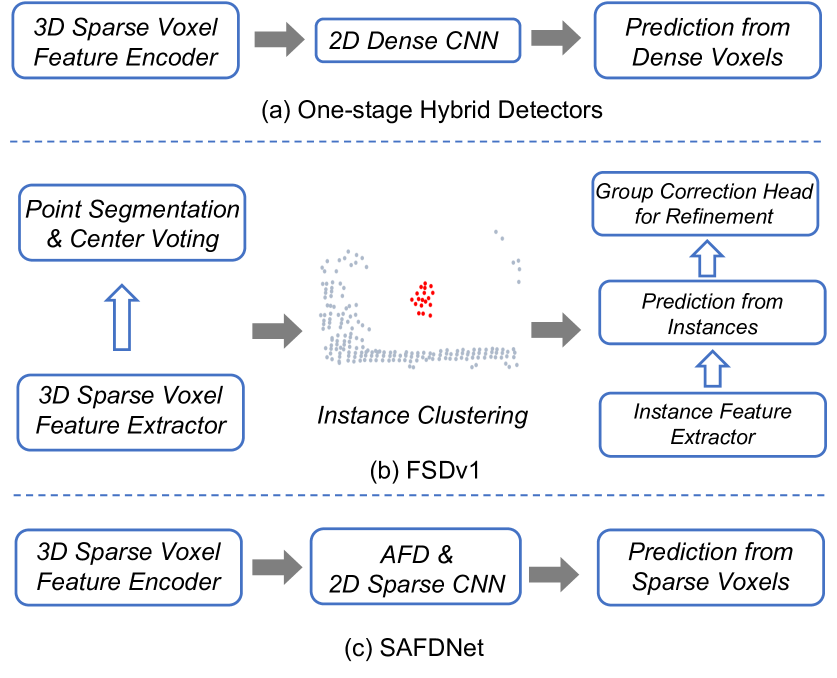
The SAFDNet architecture consists of a sparse feature encoder, a sparse region proposal network, and a sparse bounding box regressor. The sparse feature encoder efficiently processes the input point cloud, extracting relevant features. The sparse region proposal network then generates 3D bounding box proposals from the sparse features. Finally, the sparse bounding box regressor refines the proposals into the final 3D object detections.
The key technical innovations include:
- Sparse feature encoding: SAFDNet uses a sparse convolutional backbone to effectively extract features from the input point cloud, without the need to convert it to a dense 3D representation.
- Sparse region proposals: The sparse region proposal network generates 3D bounding box proposals directly from the sparse features, avoiding the need for dense feature processing.
- Sparse bounding box regression: The sparse bounding box regressor refines the proposals into the final 3D object detections using the sparse feature representation.
The researchers demonstrate the effectiveness of SAFDNet on standard 3D object detection benchmarks, showing that it can achieve state-of-the-art performance while being more computationally efficient than existing dense 3D object detectors.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the SAFDNet approach, including comparisons with various baseline methods and an ablation study to understand the contribution of each component. However, some potential limitations and areas for further research are not addressed:
- The performance of SAFDNet on very sparse point clouds, such as those encountered in long-range sensing scenarios, is not investigated. Further research is needed to understand the robustness of the approach in challenging real-world conditions.
- The paper does not discuss the memory and storage footprint of the SAFDNet model, which could be an important consideration for deployment on resource-constrained devices like self-driving cars or drones.
- The paper focuses on 3D object detection, but the potential of the sparse feature representation for other 3D perception tasks, such as full 3D occupancy prediction, is not explored.
Overall, the SAFDNet approach represents an important step forward in efficient 3D object detection using sparse point clouds. Further research to address the limitations and explore the broader applicability of the sparse feature representation could lead to even more impactful advancements in 3D perception.
Conclusion
The SAFDNet paper presents a novel approach for 3D object detection that leverages sparse point cloud data, rather than dense 3D representations. By efficiently processing sparse features, SAFDNet achieves state-of-the-art performance while being more computationally efficient than existing dense 3D object detectors. This work has the potential to significantly impact real-world 3D perception applications, such as autonomous vehicles and robotics, where computational efficiency and the ability to handle sparse data are crucial. The research also opens up new directions for exploring the use of sparse feature representations in other 3D perception tasks, further advancing the field of 3D computer vision.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SAFDNet: A Simple and Effective Network for Fully Sparse 3D Object Detection
Gang Zhang, Junnan Chen, Guohuan Gao, Jianmin Li, Si Liu, Xiaolin Hu
LiDAR-based 3D object detection plays an essential role in autonomous driving. Existing high-performing 3D object detectors usually build dense feature maps in the backbone network and prediction head. However, the computational costs introduced by the dense feature maps grow quadratically as the perception range increases, making these models hard to scale up to long-range detection. Some recent works have attempted to construct fully sparse detectors to solve this issue; nevertheless, the resulting models either rely on a complex multi-stage pipeline or exhibit inferior performance. In this work, we propose SAFDNet, a straightforward yet highly effective architecture, tailored for fully sparse 3D object detection. In SAFDNet, an adaptive feature diffusion strategy is designed to address the center feature missing problem. We conducted extensive experiments on Waymo Open, nuScenes, and Argoverse2 datasets. SAFDNet performed slightly better than the previous SOTA on the first two datasets but much better on the last dataset, which features long-range detection, verifying the efficacy of SAFDNet in scenarios where long-range detection is required. Notably, on Argoverse2, SAFDNet surpassed the previous best hybrid detector HEDNet by 2.6% mAP while being 2.1x faster, and yielded 2.1% mAP gains over the previous best sparse detector FSDv2 while being 1.3x faster. The code will be available at https://github.com/zhanggang001/HEDNet.
Read more9/24/2024

0
SparseDet: A Simple and Effective Framework for Fully Sparse LiDAR-based 3D Object Detection
Lin Liu, Ziying Song, Qiming Xia, Feiyang Jia, Caiyan Jia, Lei Yang, Hongyu Pan
LiDAR-based sparse 3D object detection plays a crucial role in autonomous driving applications due to its computational efficiency advantages. Existing methods either use the features of a single central voxel as an object proxy, or treat an aggregated cluster of foreground points as an object proxy. However, the former lacks the ability to aggregate contextual information, resulting in insufficient information expression in object proxies. The latter relies on multi-stage pipelines and auxiliary tasks, which reduce the inference speed. To maintain the efficiency of the sparse framework while fully aggregating contextual information, in this work, we propose SparseDet which designs sparse queries as object proxies. It introduces two key modules, the Local Multi-scale Feature Aggregation (LMFA) module and the Global Feature Aggregation (GFA) module, aiming to fully capture the contextual information, thereby enhancing the ability of the proxies to represent objects. Where LMFA sub-module achieves feature fusion across different scales for sparse key voxels %which does this through via coordinate transformations and using nearest neighbor relationships to capture object-level details and local contextual information, GFA sub-module uses self-attention mechanisms to selectively aggregate the features of the key voxels across the entire scene for capturing scene-level contextual information. Experiments on nuScenes and KITTI demonstrate the effectiveness of our method. Specifically, on nuScene, SparseDet surpasses the previous best sparse detector VoxelNeXt by 2.2% mAP with 13.5 FPS, and on KITTI, it surpasses VoxelNeXt by 1.12% $mathbf{AP_{3D}}$ on hard level tasks with 17.9 FPS.
Read more6/18/2024
🔎
0
Fully Sparse Fusion for 3D Object Detection
Yingyan Li, Lue Fan, Yang Liu, Zehao Huang, Yuntao Chen, Naiyan Wang, Zhaoxiang Zhang
Currently prevalent multimodal 3D detection methods are built upon LiDAR-based detectors that usually use dense Bird's-Eye-View (BEV) feature maps. However, the cost of such BEV feature maps is quadratic to the detection range, making it not suitable for long-range detection. Fully sparse architecture is gaining attention as they are highly efficient in long-range perception. In this paper, we study how to effectively leverage image modality in the emerging fully sparse architecture. Particularly, utilizing instance queries, our framework integrates the well-studied 2D instance segmentation into the LiDAR side, which is parallel to the 3D instance segmentation part in the fully sparse detector. This design achieves a uniform query-based fusion framework in both the 2D and 3D sides while maintaining the fully sparse characteristic. Extensive experiments showcase state-of-the-art results on the widely used nuScenes dataset and the long-range Argoverse 2 dataset. Notably, the inference speed of the proposed method under the long-range LiDAR perception setting is 2.7 $times$ faster than that of other state-of-the-art multimodal 3D detection methods. Code will be released at url{https://github.com/BraveGroup/FullySparseFusion}.
Read more4/30/2024
0
MR3D-Net: Dynamic Multi-Resolution 3D Sparse Voxel Grid Fusion for LiDAR-Based Collective Perception
Sven Teufel, Jorg Gamerdinger, Georg Volk, Oliver Bringmann
The safe operation of automated vehicles depends on their ability to perceive the environment comprehensively. However, occlusion, sensor range, and environmental factors limit their perception capabilities. To overcome these limitations, collective perception enables vehicles to exchange information. However, fusing this exchanged information is a challenging task. Early fusion approaches require large amounts of bandwidth, while intermediate fusion approaches face interchangeability issues. Late fusion of shared detections is currently the only feasible approach. However, it often results in inferior performance due to information loss. To address this issue, we propose MR3D-Net, a dynamic multi-resolution 3D sparse voxel grid fusion backbone architecture for LiDAR-based collective perception. We show that sparse voxel grids at varying resolutions provide a meaningful and compact environment representation that can adapt to the communication bandwidth. MR3D-Net achieves state-of-the-art performance on the OPV2V 3D object detection benchmark while reducing the required bandwidth by up to 94% compared to early fusion. Code is available at https://github.com/ekut-es/MR3D-Net
Read more8/13/2024