Self-Play with Adversarial Critic: Provable and Scalable Offline Alignment for Language Models
2406.04274
0
0
💬
Abstract
This work studies the challenge of aligning large language models (LLMs) with offline preference data. We focus on alignment by Reinforcement Learning from Human Feedback (RLHF) in particular. While popular preference optimization methods exhibit good empirical performance in practice, they are not theoretically guaranteed to converge to the optimal policy and can provably fail when the data coverage is sparse by classical offline reinforcement learning (RL) results. On the other hand, a recent line of work has focused on theoretically motivated preference optimization methods with provable guarantees, but these are not computationally efficient for large-scale applications like LLM alignment. To bridge this gap, we propose SPAC, a new offline preference optimization method with self-play, inspired by the on-average pessimism technique from the offline RL literature, to be the first provable and scalable approach to LLM alignment. We both provide theoretical analysis for its convergence under single-policy concentrability for the general function approximation setting and demonstrate its competitive empirical performance for LLM alignment on a 7B Mistral model with Open LLM Leaderboard evaluations.
Create account to get full access
Overview
- This paper proposes a new approach called "Self-Play with Adversarial Critic" (SPAC) for aligning large language models (LLMs) with human preferences in an offline setting.
- The authors develop a provably efficient and scalable method for training LLMs to optimize a given reward function, without requiring online interaction with humans.
- The method involves training an adversarial critic to distinguish the model's outputs from human-preferred outputs, and then using this critic to guide the model's self-play training.
- The authors show that SPAC can outperform existing offline alignment methods on a range of tasks, while providing stronger theoretical guarantees.
Plain English Explanation
The paper tackles the challenge of aligning large language models (LLMs) with human preferences. LLMs are powerful AI systems that can generate human-like text, but they may not always behave in ways that align with human values and preferences. The authors propose a new approach called "Self-Play with Adversarial Critic" (SPAC) to address this.
The key idea behind SPAC is to train the LLM to optimize a given reward function, without requiring direct interaction with humans. Instead, the model trains itself by playing a game against an "adversarial critic" - an AI system that tries to distinguish the model's outputs from human-preferred outputs. By learning to fool the critic, the model is guided towards generating text that aligns with human preferences.
This approach has several advantages over existing offline alignment methods. First, it is more scalable and can be applied to larger, more complex LLMs. Second, it comes with stronger theoretical guarantees about the quality of the alignment, ensuring that the model's outputs will closely match the desired reward function.
By using this self-play approach with an adversarial critic, the authors demonstrate that their SPAC method can outperform other offline alignment techniques on a variety of tasks. This is an important step towards developing LLMs that are reliably aligned with human preferences without the need for continuous human oversight or interaction.
Technical Explanation
The paper proposes a new method called Self-Play with Adversarial Critic (SPAC) for aligning large language models (LLMs) with human preferences in an offline setting. The key elements of the SPAC approach are:
-
Adversarial Critic: The authors train an adversarial critic model to distinguish between the LLM's outputs and human-preferred outputs. This critic acts as a stand-in for human preferences, providing feedback to the LLM during training.
-
Self-Play: The LLM engages in a self-play procedure, generating its own inputs and then using the adversarial critic to evaluate the quality of its outputs. By learning to fool the critic, the LLM is guided towards generating text that aligns with human preferences.
-
Theoretical Guarantees: The authors provide theoretical analysis to show that the SPAC method can provably and efficiently converge to the optimal alignment between the LLM and the given reward function, even in the offline setting.
The authors evaluate SPAC on a range of tasks, including text generation, question answering, and summarization. They demonstrate that SPAC outperforms existing offline alignment methods, such as reward modeling and reinforcement learning, while also providing stronger theoretical guarantees about the quality of the alignment.
Critical Analysis
The paper presents a promising approach for aligning large language models with human preferences in an offline setting. The use of an adversarial critic and the self-play training procedure are novel and interesting ideas that address some of the limitations of existing offline alignment methods.
However, the paper does not address several important caveats and potential limitations of the SPAC approach:
-
Robustness to Distributional Shift: The paper assumes that the human preference data used to train the adversarial critic is representative of the true human preferences. In practice, this data may not capture the full range of human values, and the model's alignment may degrade when deployed in real-world settings with different distributions.
-
Interpretability and Transparency: The SPAC method is complex, involving the training of both the LLM and the adversarial critic. It may be challenging to understand and interpret the reasons behind the model's decisions, which could limit its transparency and accountability.
-
Scalability Limitations: While the paper claims that SPAC is scalable, the training of the adversarial critic may become computationally intractable as the LLM size and complexity increase, particularly for more advanced language models.
-
Ethical Considerations: The paper does not discuss the potential ethical implications of deploying large language models aligned with human preferences. There may be concerns around bias, fairness, and the societal impact of such systems.
Future research should address these concerns and explore ways to make the SPAC approach more robust, interpretable, and scalable, while also considering the broader ethical implications of aligning LLMs with human preferences.
Conclusion
This paper presents a novel approach called "Self-Play with Adversarial Critic" (SPAC) for aligning large language models (LLMs) with human preferences in an offline setting. The key idea is to train an adversarial critic to distinguish the LLM's outputs from human-preferred outputs, and then use this critic to guide the model's self-play training.
The SPAC method offers several advantages over existing offline alignment techniques, including improved scalability and stronger theoretical guarantees. The authors demonstrate the effectiveness of SPAC on a range of tasks, showing that it can outperform other offline alignment methods.
While the SPAC approach is a promising step forward, the paper also highlights several important caveats and potential limitations that future research should address. These include concerns around robustness to distributional shift, interpretability and transparency, scalability limitations, and broader ethical considerations.
Overall, this paper contributes a novel and interesting solution to the challenging problem of aligning LLMs with human preferences. As the development of large, powerful language models continues to advance, methods like SPAC will become increasingly important for ensuring these systems behave in ways that are consistent with human values and preferences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
SAIL: Self-Improving Efficient Online Alignment of Large Language Models
Mucong Ding, Souradip Chakraborty, Vibhu Agrawal, Zora Che, Alec Koppel, Mengdi Wang, Amrit Bedi, Furong Huang
0
0
Reinforcement Learning from Human Feedback (RLHF) is a key method for aligning large language models (LLMs) with human preferences. However, current offline alignment approaches like DPO, IPO, and SLiC rely heavily on fixed preference datasets, which can lead to sub-optimal performance. On the other hand, recent literature has focused on designing online RLHF methods but still lacks a unified conceptual formulation and suffers from distribution shift issues. To address this, we establish that online LLM alignment is underpinned by bilevel optimization. By reducing this formulation to an efficient single-level first-order method (using the reward-policy equivalence), our approach generates new samples and iteratively refines model alignment by exploring responses and regulating preference labels. In doing so, we permit alignment methods to operate in an online and self-improving manner, as well as generalize prior online RLHF methods as special cases. Compared to state-of-the-art iterative RLHF methods, our approach significantly improves alignment performance on open-sourced datasets with minimal computational overhead.
6/26/2024
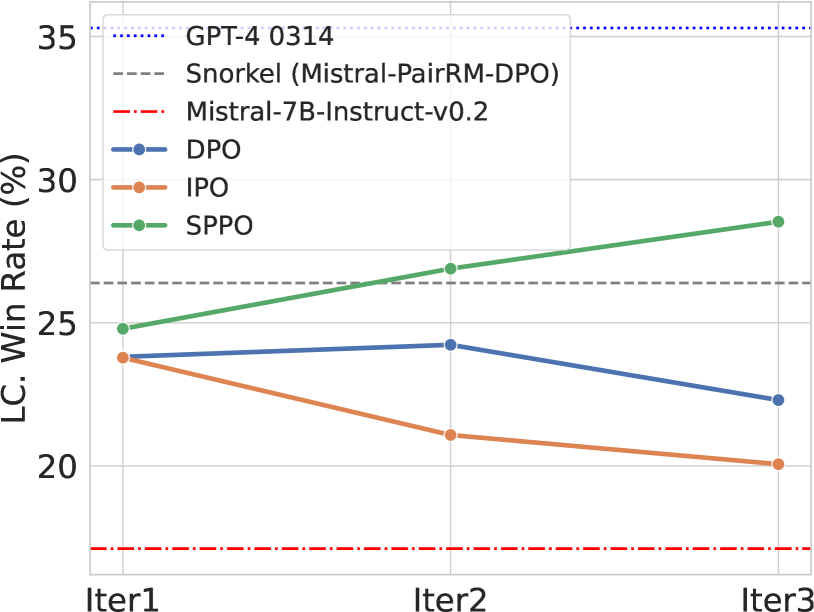
Self-Play Preference Optimization for Language Model Alignment
Yue Wu, Zhiqing Sun, Huizhuo Yuan, Kaixuan Ji, Yiming Yang, Quanquan Gu
0
0
Traditional reinforcement learning from human feedback (RLHF) approaches relying on parametric models like the Bradley-Terry model fall short in capturing the intransitivity and irrationality in human preferences. Recent advancements suggest that directly working with preference probabilities can yield a more accurate reflection of human preferences, enabling more flexible and accurate language model alignment. In this paper, we propose a self-play-based method for language model alignment, which treats the problem as a constant-sum two-player game aimed at identifying the Nash equilibrium policy. Our approach, dubbed Self-Play Preference Optimization (SPPO), approximates the Nash equilibrium through iterative policy updates and enjoys a theoretical convergence guarantee. Our method can effectively increase the log-likelihood of the chosen response and decrease that of the rejected response, which cannot be trivially achieved by symmetric pairwise loss such as Direct Preference Optimization (DPO) and Identity Preference Optimization (IPO). In our experiments, using only 60k prompts (without responses) from the UltraFeedback dataset and without any prompt augmentation, by leveraging a pre-trained preference model PairRM with only 0.4B parameters, SPPO can obtain a model from fine-tuning Mistral-7B-Instruct-v0.2 that achieves the state-of-the-art length-controlled win-rate of 28.53% against GPT-4-Turbo on AlpacaEval 2.0. It also outperforms the (iterative) DPO and IPO on MT-Bench and the Open LLM Leaderboard. Starting from a stronger base model Llama-3-8B-Instruct, we are able to achieve a length-controlled win rate of 38.77%. Notably, the strong performance of SPPO is achieved without additional external supervision (e.g., responses, preferences, etc.) from GPT-4 or other stronger language models. Codes are available at https://github.com/uclaml/SPPO.
6/17/2024
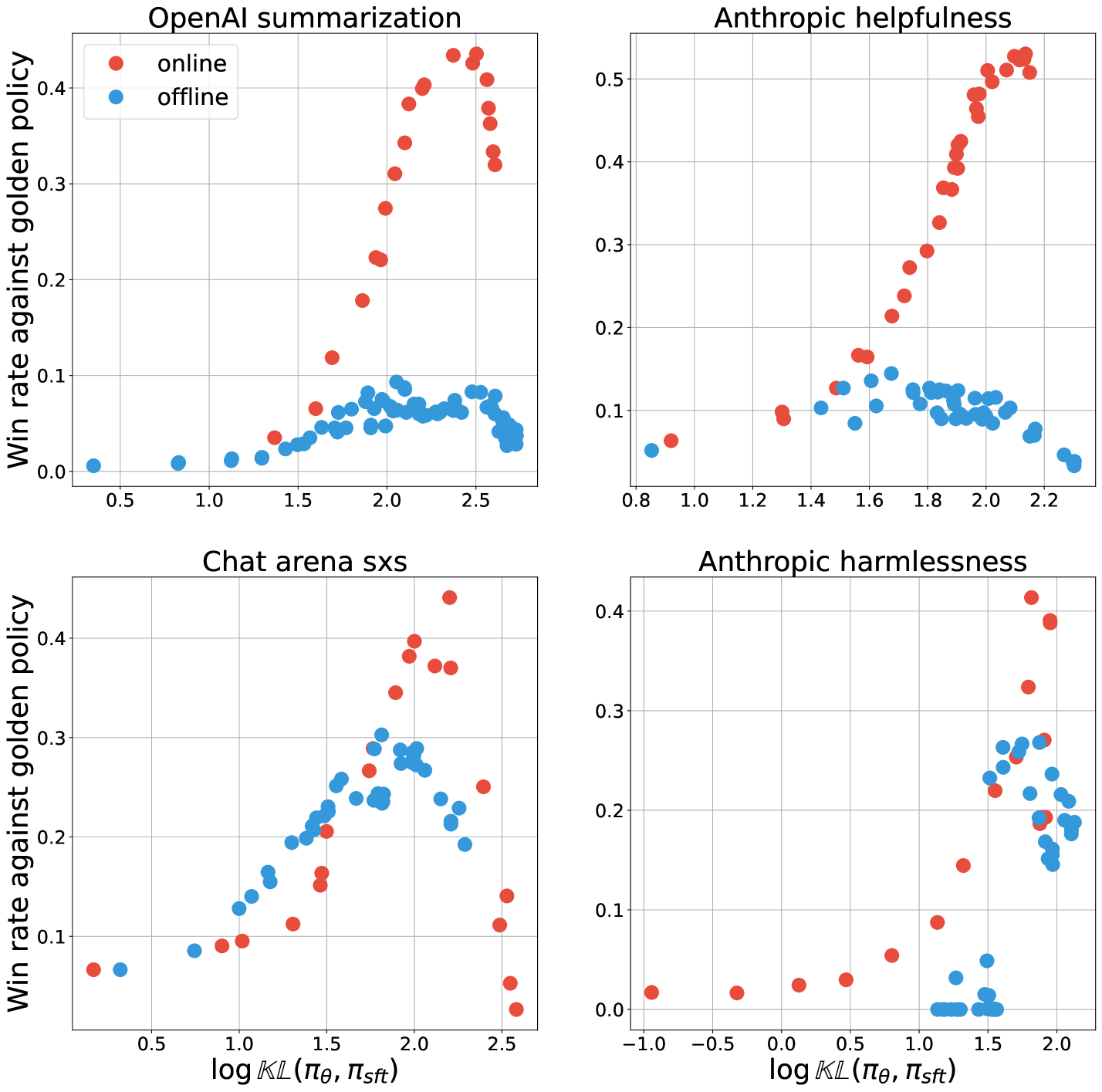
Understanding the performance gap between online and offline alignment algorithms
Yunhao Tang, Daniel Zhaohan Guo, Zeyu Zheng, Daniele Calandriello, Yuan Cao, Eugene Tarassov, R'emi Munos, Bernardo 'Avila Pires, Michal Valko, Yong Cheng, Will Dabney
0
0
Reinforcement learning from human feedback (RLHF) is the canonical framework for large language model alignment. However, rising popularity in offline alignment algorithms challenge the need for on-policy sampling in RLHF. Within the context of reward over-optimization, we start with an opening set of experiments that demonstrate the clear advantage of online methods over offline methods. This prompts us to investigate the causes to the performance discrepancy through a series of carefully designed experimental ablations. We show empirically that hypotheses such as offline data coverage and data quality by itself cannot convincingly explain the performance difference. We also find that while offline algorithms train policy to become good at pairwise classification, it is worse at generations; in the meantime the policies trained by online algorithms are good at generations while worse at pairwise classification. This hints at a unique interplay between discriminative and generative capabilities, which is greatly impacted by the sampling process. Lastly, we observe that the performance discrepancy persists for both contrastive and non-contrastive loss functions, and appears not to be addressed by simply scaling up policy networks. Taken together, our study sheds light on the pivotal role of on-policy sampling in AI alignment, and hints at certain fundamental challenges of offline alignment algorithms.
5/15/2024
💬
Privately Aligning Language Models with Reinforcement Learning
Fan Wu, Huseyin A. Inan, Arturs Backurs, Varun Chandrasekaran, Janardhan Kulkarni, Robert Sim
0
0
Positioned between pre-training and user deployment, aligning large language models (LLMs) through reinforcement learning (RL) has emerged as a prevailing strategy for training instruction following-models such as ChatGPT. In this work, we initiate the study of privacy-preserving alignment of LLMs through Differential Privacy (DP) in conjunction with RL. Following the influential work of Ziegler et al. (2020), we study two dominant paradigms: (i) alignment via RL without human in the loop (e.g., positive review generation) and (ii) alignment via RL from human feedback (RLHF) (e.g., summarization in a human-preferred way). We give a new DP framework to achieve alignment via RL, and prove its correctness. Our experimental results validate the effectiveness of our approach, offering competitive utility while ensuring strong privacy protections.
5/6/2024