RLHF Workflow: From Reward Modeling to Online RLHF
2405.07863
0
0
🧠
Abstract
We present the workflow of Online Iterative Reinforcement Learning from Human Feedback (RLHF) in this technical report, which is widely reported to outperform its offline counterpart by a large margin in the recent large language model (LLM) literature. However, existing open-source RLHF projects are still largely confined to the offline learning setting. In this technical report, we aim to fill in this gap and provide a detailed recipe that is easy to reproduce for online iterative RLHF. In particular, since online human feedback is usually infeasible for open-source communities with limited resources, we start by constructing preference models using a diverse set of open-source datasets and use the constructed proxy preference model to approximate human feedback. Then, we discuss the theoretical insights and algorithmic principles behind online iterative RLHF, followed by a detailed practical implementation. Our trained LLM, LLaMA-3-8B-SFR-Iterative-DPO-R, achieves impressive performance on LLM chatbot benchmarks, including AlpacaEval-2, Arena-Hard, and MT-Bench, as well as other academic benchmarks such as HumanEval and TruthfulQA. We have shown that supervised fine-tuning (SFT) and iterative RLHF can obtain state-of-the-art performance with fully open-source datasets. Further, we have made our models, curated datasets, and comprehensive step-by-step code guidebooks publicly available. Please refer to https://github.com/RLHFlow/RLHF-Reward-Modeling and https://github.com/RLHFlow/Online-RLHF for more detailed information.
Create account to get full access
Overview
- The paper presents a detailed workflow for Online Iterative Reinforcement Learning from Human Feedback (RLHF), which is reported to outperform its offline counterpart in recent large language model (LLM) literature.
- Existing open-source RLHF projects are largely confined to the offline learning setting, so the paper aims to fill this gap and provide a reproducible recipe for online iterative RLHF.
- Since online human feedback is often infeasible for open-source communities, the authors construct proxy preference models using diverse open-source datasets to approximate human feedback.
- The paper discusses the theoretical insights and algorithmic principles behind online iterative RLHF, followed by a detailed practical implementation.
- The authors have made their trained LLM, curated datasets, and comprehensive step-by-step code guidebooks publicly available.
Plain English Explanation
The paper describes a new way to train large language models (LLMs) to be better at tasks that require understanding human preferences, like having natural conversations. The traditional approach, called "offline RLHF," has limitations, so the authors present a new "online iterative RLHF" method that is reported to work better.
The key idea is to use a model that can predict how humans would rate the responses of the LLM, and then use that model to guide the training of the LLM to produce better responses. This is done in an iterative process, where the prediction model is continuously updated and used to further improve the LLM.
Since it's often not feasible for open-source projects to get direct feedback from humans, the authors use a clever workaround. They construct these "preference models" using existing open-source datasets, which allows them to approximate human feedback without actually having humans in the loop.
The paper provides a detailed step-by-step guide on how to implement this online iterative RLHF approach, and the authors have made their trained models, datasets, and code publicly available for others to use and build upon.
Technical Explanation
The paper presents a detailed workflow for Online Iterative Reinforcement Learning from Human Feedback (RLHF), which is widely reported to outperform its offline counterpart by a large margin in the recent large language model (LLM) literature.
To address the fact that existing open-source RLHF projects are still largely confined to the offline learning setting, the authors start by constructing preference models using a diverse set of open-source datasets. These proxy preference models are used to approximate human feedback, as online human feedback is usually infeasible for open-source communities with limited resources.
The paper then discusses the theoretical insights and algorithmic principles behind online iterative RLHF, followed by a detailed practical implementation. The key steps include:
- Pretraining an LLM (e.g., LLaMA-3-8B) using supervised fine-tuning (SFT) on a diverse set of open-source datasets.
- Constructing a preference model to approximate human feedback using the SFT-trained LLM and open-source datasets.
- Iteratively fine-tuning the LLM using the preference model as the reward signal, following the principles of RLHF.
- Evaluating the performance of the iteratively fine-tuned LLM on a variety of benchmarks, including AlpacaEval-2, Arena-Hard, MT-Bench, HumanEval, and TruthfulQA.
The authors' trained LLM, called SFR-Iterative-DPO-LLaMA-3-8B-R, achieves impressive performance on these benchmarks, demonstrating that supervised fine-tuning (SFT) and iterative RLHF can obtain state-of-the-art results using fully open-source datasets.
Critical Analysis
The paper provides a comprehensive and detailed workflow for implementing online iterative RLHF, which is a significant contribution to the field. However, a few caveats and areas for further research are worth noting:
-
The reliance on proxy preference models constructed from open-source datasets, while a necessary workaround, may introduce biases and limitations compared to direct human feedback. Further research is needed to understand the impact of this approximation.
-
The paper does not provide a thorough analysis of the training dynamics and convergence properties of the online iterative RLHF approach. Additional theoretical and empirical investigations could shed more light on the underlying mechanisms and potential failure modes.
-
The evaluation is focused on language model benchmarks, but the broader applicability and real-world performance of the trained LLM in more diverse and open-ended tasks remain to be explored.
-
The paper does not address potential issues around the safe and ethical deployment of LLMs trained using RLHF. Further research is needed to understand and mitigate any unintended consequences.
Overall, the paper presents a significant advancement in the field of RLHF and opens up promising avenues for further research and development in this area.
Conclusion
This paper presents a detailed workflow for Online Iterative Reinforcement Learning from Human Feedback (RLHF), a promising approach to training large language models (LLMs) that can better align with human preferences. By constructing proxy preference models from open-source datasets and using them to guide the iterative fine-tuning of the LLM, the authors have demonstrated a practical way to improve LLM performance on a variety of benchmarks.
The public release of the authors' trained models, curated datasets, and comprehensive step-by-step code guidebooks is a valuable contribution that will enable open-source communities to build upon this work and advance the field of RLHF. While the reliance on proxy feedback models and the need for further research on safety and ethics remain as areas for improvement, this paper represents a significant step forward in the quest to develop LLMs that can engage in more natural and meaningful interactions with humans.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Iterative Preference Learning from Human Feedback: Bridging Theory and Practice for RLHF under KL-Constraint
Wei Xiong, Hanze Dong, Chenlu Ye, Ziqi Wang, Han Zhong, Heng Ji, Nan Jiang, Tong Zhang
0
0
This paper studies the alignment process of generative models with Reinforcement Learning from Human Feedback (RLHF). We first identify the primary challenges of existing popular methods like offline PPO and offline DPO as lacking in strategical exploration of the environment. Then, to understand the mathematical principle of RLHF, we consider a standard mathematical formulation, the reverse-KL regularized contextual bandit for RLHF. Despite its widespread practical application, a rigorous theoretical analysis of this formulation remains open. We investigate its behavior in three distinct settings -- offline, online, and hybrid -- and propose efficient algorithms with finite-sample theoretical guarantees. Moving towards practical applications, our framework, with a robust approximation of the information-theoretical policy improvement oracle, naturally gives rise to several novel RLHF algorithms. This includes an iterative version of the Direct Preference Optimization (DPO) algorithm for online settings, and a multi-step rejection sampling strategy for offline scenarios. Our empirical evaluations on real-world alignment experiment of large language model demonstrate that these proposed methods significantly surpass existing strong baselines, such as DPO and Rejection Sampling Optimization (RSO), showcasing the connections between solid theoretical foundations and their potent practical implementations.
5/2/2024

RLHF Deciphered: A Critical Analysis of Reinforcement Learning from Human Feedback for LLMs
Shreyas Chaudhari, Pranjal Aggarwal, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, Karthik Narasimhan, Ameet Deshpande, Bruno Castro da Silva
0
0
State-of-the-art large language models (LLMs) have become indispensable tools for various tasks. However, training LLMs to serve as effective assistants for humans requires careful consideration. A promising approach is reinforcement learning from human feedback (RLHF), which leverages human feedback to update the model in accordance with human preferences and mitigate issues like toxicity and hallucinations. Yet, an understanding of RLHF for LLMs is largely entangled with initial design choices that popularized the method and current research focuses on augmenting those choices rather than fundamentally improving the framework. In this paper, we analyze RLHF through the lens of reinforcement learning principles to develop an understanding of its fundamentals, dedicating substantial focus to the core component of RLHF -- the reward model. Our study investigates modeling choices, caveats of function approximation, and their implications on RLHF training algorithms, highlighting the underlying assumptions made about the expressivity of reward. Our analysis improves the understanding of the role of reward models and methods for their training, concurrently revealing limitations of the current methodology. We characterize these limitations, including incorrect generalization, model misspecification, and the sparsity of feedback, along with their impact on the performance of a language model. The discussion and analysis are substantiated by a categorical review of current literature, serving as a reference for researchers and practitioners to understand the challenges of RLHF and build upon existing efforts.
4/17/2024

OpenRLHF: An Easy-to-use, Scalable and High-performance RLHF Framework
Jian Hu, Xibin Wu, Weixun Wang, Xianyu, Dehao Zhang, Yu Cao
0
0
As large language models (LLMs) continue to grow by scaling laws, reinforcement learning from human feedback (RLHF) has gained significant attention due to its outstanding performance. However, unlike pretraining or fine-tuning a single model, scaling reinforcement learning from human feedback (RLHF) for training large language models poses coordination challenges across four models. We present OpenRLHF, an open-source framework enabling efficient RLHF scaling. Unlike existing RLHF frameworks that co-locate four models on the same GPUs, OpenRLHF re-designs scheduling for the models beyond 70B parameters using Ray, vLLM, and DeepSpeed, leveraging improved resource utilization and diverse training approaches. Integrating seamlessly with Hugging Face, OpenRLHF provides an out-of-the-box solution with optimized algorithms and launch scripts, which ensures user-friendliness. OpenRLHF implements RLHF, DPO, rejection sampling, and other alignment techniques. Empowering state-of-the-art LLM development, OpenRLHF's code is available at https://github.com/OpenLLMAI/OpenRLHF.
6/4/2024
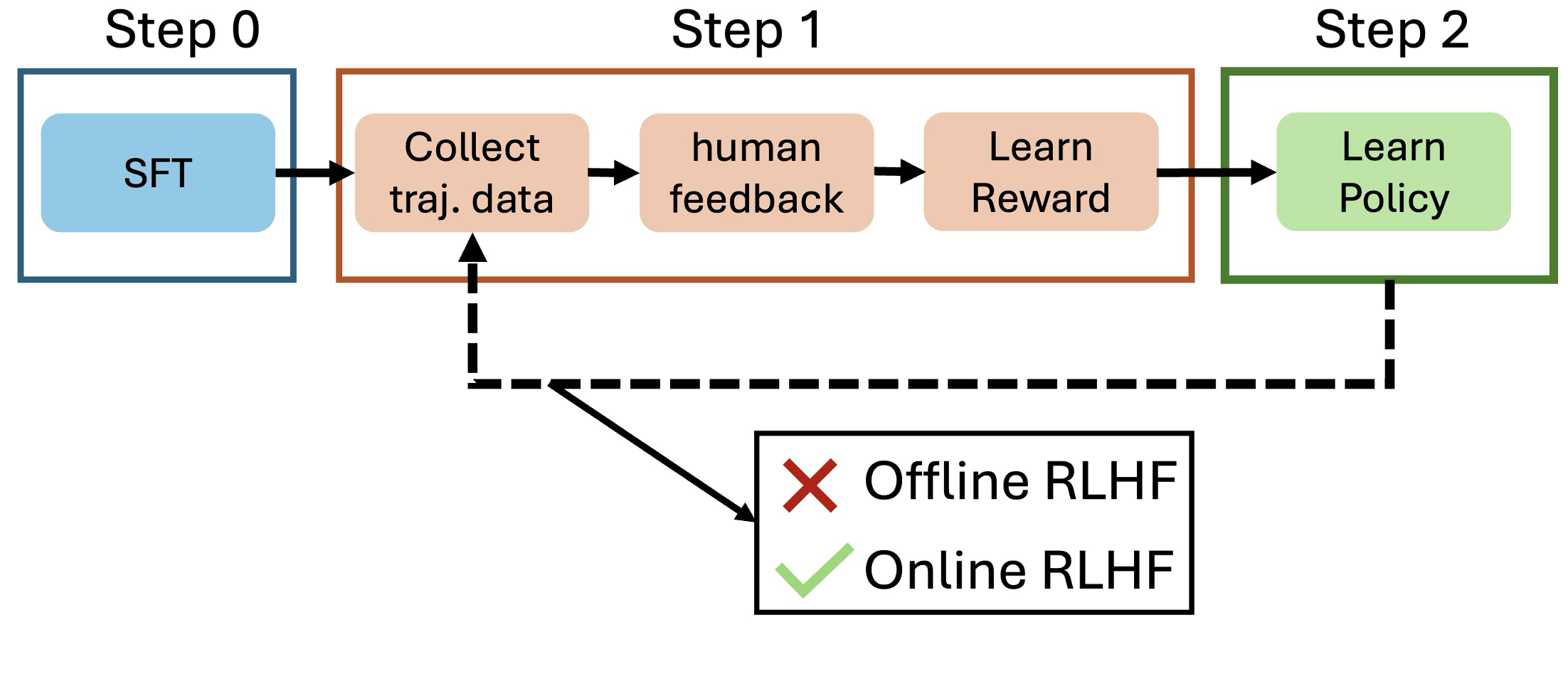
SAIL: Self-Improving Efficient Online Alignment of Large Language Models
Mucong Ding, Souradip Chakraborty, Vibhu Agrawal, Zora Che, Alec Koppel, Mengdi Wang, Amrit Bedi, Furong Huang
0
0
Reinforcement Learning from Human Feedback (RLHF) is a key method for aligning large language models (LLMs) with human preferences. However, current offline alignment approaches like DPO, IPO, and SLiC rely heavily on fixed preference datasets, which can lead to sub-optimal performance. On the other hand, recent literature has focused on designing online RLHF methods but still lacks a unified conceptual formulation and suffers from distribution shift issues. To address this, we establish that online LLM alignment is underpinned by bilevel optimization. By reducing this formulation to an efficient single-level first-order method (using the reward-policy equivalence), our approach generates new samples and iteratively refines model alignment by exploring responses and regulating preference labels. In doing so, we permit alignment methods to operate in an online and self-improving manner, as well as generalize prior online RLHF methods as special cases. Compared to state-of-the-art iterative RLHF methods, our approach significantly improves alignment performance on open-sourced datasets with minimal computational overhead.
6/26/2024