SAM-SP: Self-Prompting Makes SAM Great Again

0

Sign in to get full access
Overview
- The paper introduces a novel approach called SAM-SP, which enhances the performance of the Segment Anything Model (SAM) through self-prompting.
- SAM-SP leverages the existing capabilities of SAM to generate prompts that further improve its own segmentation abilities.
- The paper demonstrates that SAM-SP outperforms the original SAM model across various tasks and datasets.
Plain English Explanation
The Segment Anything Model (SAM) is a powerful AI system that can identify and segment objects in images. However, the researchers noticed that SAM's performance could be further improved.
To address this, they developed a new approach called SAM-SP, which stands for "Self-Prompting SAM." The key idea behind SAM-SP is to have SAM generate its own prompts, which are then used to enhance its own segmentation abilities. This self-prompting process allows SAM to continuously refine and improve its object segmentation capabilities.
The researchers found that SAM-SP outperforms the original SAM model across a variety of tasks and datasets. This means that SAM-SP is able to more accurately identify and segment objects in images compared to the original SAM.
Technical Explanation
The paper introduces a new technique called SAM-SP, which builds upon the Segment Anything Model (SAM). SAM-SP leverages SAM's existing capabilities to generate its own prompts, which are then used to further improve the model's segmentation performance.
The researchers first fine-tune the SAM model on a diverse dataset of images and masks. They then use this fine-tuned SAM model to generate prompts for new images, which are in turn used to refine the segmentation outputs. This self-prompting process is repeated iteratively, allowing SAM-SP to continuously learn and improve its segmentation abilities.
The authors evaluate SAM-SP on a range of benchmarks, including object segmentation and instance segmentation tasks. They demonstrate that SAM-SP outperforms the original SAM model, as well as other state-of-the-art segmentation approaches, across these various datasets and metrics.
Critical Analysis
The paper presents a promising approach for enhancing the performance of the Segment Anything Model through self-prompting. By allowing SAM to generate its own prompts, the researchers have found a way to further refine and improve the model's segmentation capabilities.
One potential limitation of the SAM-SP approach is the computational cost associated with the iterative self-prompting process. Each iteration requires running the SAM model to generate prompts, which could be time-consuming, especially for large-scale deployment. The authors do not discuss the computational efficiency of their method in detail.
Additionally, the paper does not explore the generalization of SAM-SP to out-of-distribution data or its robustness to various types of image perturbations. Further research would be needed to understand the broader applicability and limitations of this approach.
Conclusion
The SAM-SP: Self-Prompting Makes SAM Great Again paper introduces an innovative technique for improving the performance of the Segment Anything Model through self-prompting. By leveraging SAM's existing capabilities to generate its own prompts, the researchers have developed a method that outperforms the original SAM model across a range of segmentation tasks.
This work highlights the potential for self-supervised techniques in computer vision, where models can continuously learn and refine their abilities through iterative self-improvement. The broader implications of this research could extend to other areas of AI, where the ability to self-prompt and self-improve could lead to more robust and capable systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SAM-SP: Self-Prompting Makes SAM Great Again
Chunpeng Zhou, Kangjie Ning, Qianqian Shen, Sheng Zhou, Zhi Yu, Haishuai Wang
The recently introduced Segment Anything Model (SAM), a Visual Foundation Model (VFM), has demonstrated impressive capabilities in zero-shot segmentation tasks across diverse natural image datasets. Despite its success, SAM encounters noticeably performance degradation when applied to specific domains, such as medical images. Current efforts to address this issue have involved fine-tuning strategies, intended to bolster the generalizability of the vanilla SAM. However, these approaches still predominantly necessitate the utilization of domain specific expert-level prompts during the evaluation phase, which severely constrains the model's practicality. To overcome this limitation, we introduce a novel self-prompting based fine-tuning approach, called SAM-SP, tailored for extending the vanilla SAM model. Specifically, SAM-SP leverages the output from the previous iteration of the model itself as prompts to guide subsequent iteration of the model. This self-prompting module endeavors to learn how to generate useful prompts autonomously and alleviates the dependence on expert prompts during the evaluation phase, significantly broadening SAM's applicability. Additionally, we integrate a self-distillation module to enhance the self-prompting process further. Extensive experiments across various domain specific datasets validate the effectiveness of the proposed SAM-SP. Our SAM-SP not only alleviates the reliance on expert prompts but also exhibits superior segmentation performance comparing to the state-of-the-art task-specific segmentation approaches, the vanilla SAM, and SAM-based approaches.
Read more8/23/2024

0
ESP-MedSAM: Efficient Self-Prompting SAM for Universal Domain-Generalized Medical Image Segmentation
Qing Xu, Jiaxuan Li, Xiangjian He, Ziyu Liu, Zhen Chen, Wenting Duan, Chenxin Li, Maggie M. He, Fiseha B. Tesema, Wooi P. Cheah, Yi Wang, Rong Qu, Jonathan M. Garibaldi
The universality of deep neural networks across different modalities and their generalization capabilities to unseen domains play an essential role in medical image segmentation. The recent Segment Anything Model (SAM) has demonstrated its potential in both settings. However, the huge computational costs, demand for manual annotations as prompts and conflict-prone decoding process of SAM degrade its generalizability and applicability in clinical scenarios. To address these issues, we propose an efficient self-prompting SAM for universal domain-generalized medical image segmentation, named ESP-MedSAM. Specifically, we first devise the Multi-Modal Decoupled Knowledge Distillation (MMDKD) strategy to construct a lightweight semi-parameter sharing image encoder that produces discriminative visual features for diverse modalities. Further, we introduce the Self-Patch Prompt Generator (SPPG) to automatically generate high-quality dense prompt embeddings for guiding segmentation decoding. Finally, we design the Query-Decoupled Modality Decoder (QDMD) that leverages a one-to-one strategy to provide an independent decoding channel for every modality. Extensive experiments indicate that ESP-MedSAM outperforms state-of-the-arts in diverse medical imaging segmentation tasks, displaying superior modality universality and generalization capabilities. Especially, ESP-MedSAM uses only 4.5% parameters compared to SAM-H. The source code is available at https://github.com/xq141839/ESP-MedSAM.
Read more8/20/2024
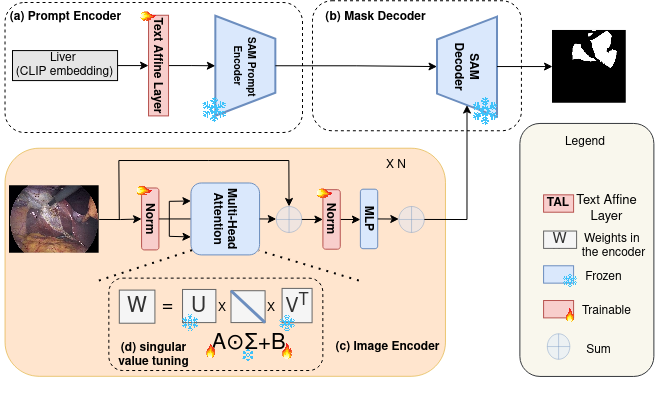
0
S-SAM: SVD-based Fine-Tuning of Segment Anything Model for Medical Image Segmentation
Jay N. Paranjape, Shameema Sikder, S. Swaroop Vedula, Vishal M. Patel
Medical image segmentation has been traditionally approached by training or fine-tuning the entire model to cater to any new modality or dataset. However, this approach often requires tuning a large number of parameters during training. With the introduction of the Segment Anything Model (SAM) for prompted segmentation of natural images, many efforts have been made towards adapting it efficiently for medical imaging, thus reducing the training time and resources. However, these methods still require expert annotations for every image in the form of point prompts or bounding box prompts during training and inference, making it tedious to employ them in practice. In this paper, we propose an adaptation technique, called S-SAM, that only trains parameters equal to 0.4% of SAM's parameters and at the same time uses simply the label names as prompts for producing precise masks. This not only makes tuning SAM more efficient than the existing adaptation methods but also removes the burden of providing expert prompts. We call this modified version S-SAM and evaluate it on five different modalities including endoscopic images, x-ray, ultrasound, CT, and histology images. Our experiments show that S-SAM outperforms state-of-the-art methods as well as existing SAM adaptation methods while tuning a significantly less number of parameters. We release the code for S-SAM at https://github.com/JayParanjape/SVDSAM.
Read more8/14/2024

0
TAVP: Task-Adaptive Visual Prompt for Cross-domain Few-shot Segmentation
Jiaqi Yang, Ye Huang, Xiangjian He, Linlin Shen, Guoping Qiu
Under the backdrop of large-scale pre-training, large visual models (LVM) have demonstrated significant potential in image understanding. The recent emergence of the Segment Anything Model (SAM) has brought a qualitative shift in the field of image segmentation, supporting flexible interactive cues and strong learning capabilities. However, its performance often falls short in cross-domain and few-shot applications. Transferring prior knowledge from foundation models to new applications while preserving learning capabilities is worth exploring. This work proposes a task-adaptive prompt framework based on SAM, a new paradigm for Cross-dominan few-shot segmentation (CD-FSS). First, a Multi-level Feature Fusion (MFF) was used for integrated feature extraction. Besides, an additional Class Domain Task-Adaptive Auto-Prompt (CDTAP) module was combined with the segmentation branch for class-domain agnostic feature extraction and high-quality learnable prompt production. This significant advancement uses a unique generative approach to prompts alongside a comprehensive model structure and specialized prototype computation. While ensuring that the prior knowledge of SAM is not discarded, the new branch disentangles category and domain information through prototypes, guiding it in adapting the CD-FSS. We have achieved the best results on three benchmarks compared to the recent state-of-the-art (SOTA) methods. Comprehensive experiments showed that after task-specific and weighted guidance, the abundant feature information of SAM can be better learned for CD-FSS.
Read more9/10/2024