SaRA: High-Efficient Diffusion Model Fine-tuning with Progressive Sparse Low-Rank Adaptation

0
📈
Sign in to get full access
Overview
- The paper proposes a novel fine-tuning method called SaRA to enhance the capabilities of pre-trained diffusion models like Stable Diffusion.
- The method re-utilizes the smallest 10-20% of parameters in the pre-trained model that do not significantly contribute to generation.
- SaRA uses a sparse, low-rank training scheme and a progressive parameter adjustment strategy to efficiently fine-tune the model.
- It also introduces a novel unstructured backpropagation technique to reduce memory costs during fine-tuning.
- The approach outperforms traditional fine-tuning methods like LoRA in maintaining the model's generalization ability.
Plain English Explanation
Large pre-trained AI models like Stable Diffusion are powerful, but also very computationally expensive. The researchers behind this paper wanted to find a way to fine-tune these models to handle new tasks without fully retraining them from scratch, which would be very resource-intensive.
They noticed that a small portion of the parameters (around 10-20%) in the pre-trained model didn't really contribute much to its image generation capabilities. The researchers proposed a method called SaRA that could re-use these "ineffective" parameters to teach the model new skills, while minimizing the amount of new training required.
SaRA uses a sparse, low-rank training approach and a clever technique called "progressive parameter adjustment" to fine-tune the model efficiently. It also has an innovative "unstructured backpropagation" strategy that reduces the amount of memory needed during the fine-tuning process.
Compared to other fine-tuning methods, SaRA is able to enhance the model's capabilities for new tasks while still preserving its original generalization abilities. This makes it a practical and efficient way to adapt powerful AI models to handle different applications.
Technical Explanation
The researchers first investigate the importance of parameters in pre-trained diffusion models and find that the smallest 10-20% of parameters by absolute value do not significantly contribute to the generation process. They then propose the SaRA method, which re-utilizes these temporarily ineffective parameters to learn task-specific knowledge.
To mitigate overfitting, SaRA uses a nuclear-norm-based low-rank sparse training scheme for efficient fine-tuning. The method also includes a progressive parameter adjustment strategy to make full use of the re-trained/fine-tuned parameters.
Furthermore, the researchers design a novel unstructural backpropagation strategy, which significantly reduces memory costs during fine-tuning. This allows SaRA to be more computationally efficient compared to traditional fine-tuning approaches.
Critical Analysis
The paper provides a promising approach to fine-tuning large pre-trained diffusion models like Stable Diffusion in a more efficient and effective manner. The key strengths of the SaRA method are its ability to re-utilize "ineffective" parameters, its use of sparse and low-rank training techniques to avoid overfitting, and its novel backpropagation strategy to reduce memory requirements.
However, the paper does not extensively discuss potential limitations or caveats of the proposed method. For example, it's unclear how the performance of SaRA would scale with the size of the pre-trained model or the complexity of the target task. Additionally, the paper does not compare SaRA to a wider range of fine-tuning techniques beyond LoRA.
Further research could explore the generalizability of SaRA across different pre-trained models and task domains, as well as investigate potential trade-offs between efficiency, performance, and model stability during the fine-tuning process.
Conclusion
The SaRA fine-tuning method presented in this paper demonstrates a promising approach to enhancing the capabilities of large pre-trained diffusion models without the need for costly full retraining. By re-utilizing "ineffective" parameters and using efficient training techniques, SaRA is able to fine-tune models for new tasks while preserving their generalization abilities.
This work contributes to the growing body of research on parameter-efficient fine-tuning, which is crucial for making powerful AI models more accessible and adaptable for a wide range of real-world applications. The practical benefits of SaRA, such as its ease of implementation and compatibility with existing methods, also make it a compelling option for practitioners working with large-scale diffusion models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
SaRA: High-Efficient Diffusion Model Fine-tuning with Progressive Sparse Low-Rank Adaptation
Teng Hu, Jiangning Zhang, Ran Yi, Hongrui Huang, Yabiao Wang, Lizhuang Ma
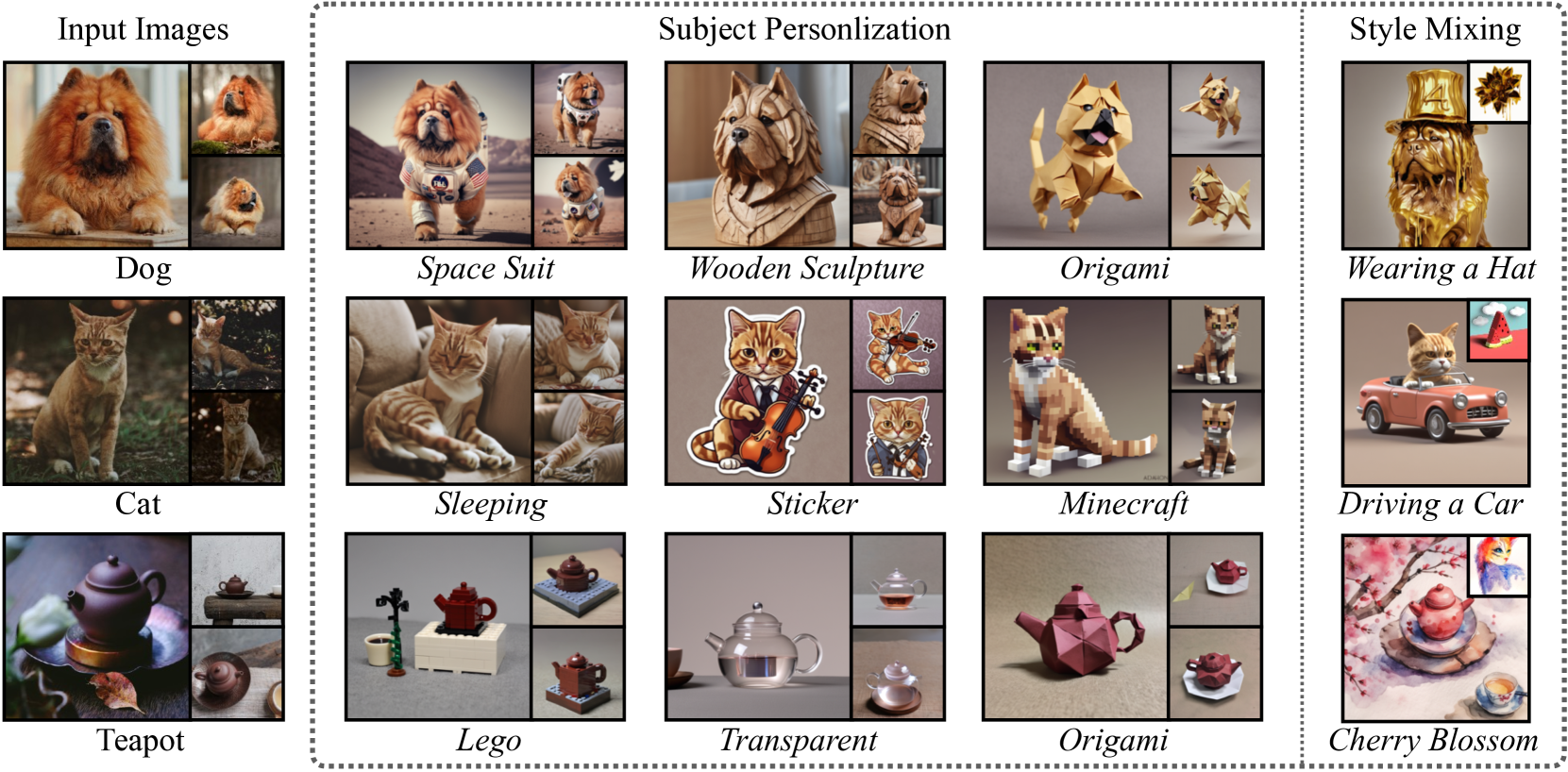
In recent years, the development of diffusion models has led to significant progress in image and video generation tasks, with pre-trained models like the Stable Diffusion series playing a crucial role. Inspired by model pruning which lightens large pre-trained models by removing unimportant parameters, we propose a novel model fine-tuning method to make full use of these ineffective parameters and enable the pre-trained model with new task-specified capabilities. In this work, we first investigate the importance of parameters in pre-trained diffusion models, and discover that the smallest 10% to 20% of parameters by absolute values do not contribute to the generation process. Based on this observation, we propose a method termed SaRA that re-utilizes these temporarily ineffective parameters, equating to optimizing a sparse weight matrix to learn the task-specific knowledge. To mitigate overfitting, we propose a nuclear-norm-based low-rank sparse training scheme for efficient fine-tuning. Furthermore, we design a new progressive parameter adjustment strategy to make full use of the re-trained/finetuned parameters. Finally, we propose a novel unstructural backpropagation strategy, which significantly reduces memory costs during fine-tuning. Our method enhances the generative capabilities of pre-trained models in downstream applications and outperforms traditional fine-tuning methods like LoRA in maintaining model's generalization ability. We validate our approach through fine-tuning experiments on SD models, demonstrating significant improvements. SaRA also offers a practical advantage that requires only a single line of code modification for efficient implementation and is seamlessly compatible with existing methods.
Read more9/11/2024
0
Spectrum-Aware Parameter Efficient Fine-Tuning for Diffusion Models
Xinxi Zhang, Song Wen, Ligong Han, Felix Juefei-Xu, Akash Srivastava, Junzhou Huang, Hao Wang, Molei Tao, Dimitris N. Metaxas
Adapting large-scale pre-trained generative models in a parameter-efficient manner is gaining traction. Traditional methods like low rank adaptation achieve parameter efficiency by imposing constraints but may not be optimal for tasks requiring high representation capacity. We propose a novel spectrum-aware adaptation framework for generative models. Our method adjusts both singular values and their basis vectors of pretrained weights. Using the Kronecker product and efficient Stiefel optimizers, we achieve parameter-efficient adaptation of orthogonal matrices. We introduce Spectral Orthogonal Decomposition Adaptation (SODA), which balances computational efficiency and representation capacity. Extensive evaluations on text-to-image diffusion models demonstrate SODA's effectiveness, offering a spectrum-aware alternative to existing fine-tuning methods.
Read more6/3/2024

0
SARA: Singular-Value Based Adaptive Low-Rank Adaption
Jihao Gu, Shuai Chen, Zelin Wang, Yibo Zhang, Ping Gong
With the increasing number of parameters in large pre-trained models, LoRA as a parameter-efficient fine-tuning(PEFT) method is widely used for not adding inference overhead. The LoRA method assumes that weight changes during fine-tuning can be approximated by low-rank matrices. However, the rank values need to be manually verified to match different downstream tasks, and they cannot accommodate the varying importance of different layers in the model. In this work, we first analyze the relationship between the performance of different layers and their ranks using SVD. Based on this, we design the Singular-Value Based Adaptive Low-Rank Adaption(SARA), which adaptively finds the rank during initialization by performing SVD on the pre-trained weights. Additionally, we explore the Mixture-of-SARA(Mo-SARA), which significantly reduces the number of parameters by fine-tuning only multiple parallel sets of singular values controlled by a router. Extensive experiments on various complex tasks demonstrate the simplicity and parameter efficiency of our methods. They can effectively and adaptively find the most suitable rank for each layer of each model.
Read more8/7/2024

0
DoRA: Enhancing Parameter-Efficient Fine-Tuning with Dynamic Rank Distribution
Yulong Mao, Kaiyu Huang, Changhao Guan, Ganglin Bao, Fengran Mo, Jinan Xu
Fine-tuning large-scale pre-trained models is inherently a resource-intensive task. While it can enhance the capabilities of the model, it also incurs substantial computational costs, posing challenges to the practical application of downstream tasks. Existing parameter-efficient fine-tuning (PEFT) methods such as Low-Rank Adaptation (LoRA) rely on a bypass framework that ignores the differential parameter budget requirements across weight matrices, which may lead to suboptimal fine-tuning outcomes. To address this issue, we introduce the Dynamic Low-Rank Adaptation (DoRA) method. DoRA decomposes high-rank LoRA layers into structured single-rank components, allowing for dynamic pruning of parameter budget based on their importance to specific tasks during training, which makes the most of the limited parameter budget. Experimental results demonstrate that DoRA can achieve competitive performance compared with LoRA and full model fine-tuning, and outperform various strong baselines with the same storage parameter budget. Our code is available at https://github.com/MIkumikumi0116/DoRA
Read more6/27/2024