SC-MoE: Switch Conformer Mixture of Experts for Unified Streaming and Non-streaming Code-Switching ASR

0
Sign in to get full access
Overview
- This paper introduces SC-MoE, a novel architecture for code-switching automatic speech recognition (ASR) that can handle both streaming and non-streaming scenarios.
- It combines a Switch Conformer (SC) encoder with a Mixture of Experts (MoE) decoder to enable unified processing of different language inputs.
- The SC-MoE model achieves state-of-the-art performance on multiple code-switching ASR benchmarks while maintaining low latency for streaming applications.
Plain English Explanation
SC-MoE is a new machine learning model designed for automatic speech recognition (ASR) in situations where people switch between multiple languages, known as "code-switching." This is a common challenge in many parts of the world where people regularly mix different languages in their speech.
The key innovation in SC-MoE is the combination of two powerful techniques: Switch Conformer (SC) and Mixture of Experts (MoE). The SC encoder can efficiently process speech signals that switch between languages, while the MoE decoder allows the model to specialize in different language pairs.
This unified architecture enables SC-MoE to perform well on both streaming (real-time) and non-streaming (batch) code-switching ASR tasks. Streaming ASR is important for applications like virtual assistants, where low latency is critical. Non-streaming ASR is used for tasks like transcribing recorded audio.
By combining these advanced techniques, the SC-MoE model achieves state-of-the-art performance on several benchmark datasets for code-switching ASR. This means it can accurately transcribe speech that mixes multiple languages, which is a significant advancement for making speech recognition technology more inclusive and accessible in multilingual environments.
Technical Explanation
The SC-MoE model builds on previous work in streaming and non-streaming code-switching ASR, as well as Mixture of Experts (MoE) architectures.
The key components of SC-MoE are:
-
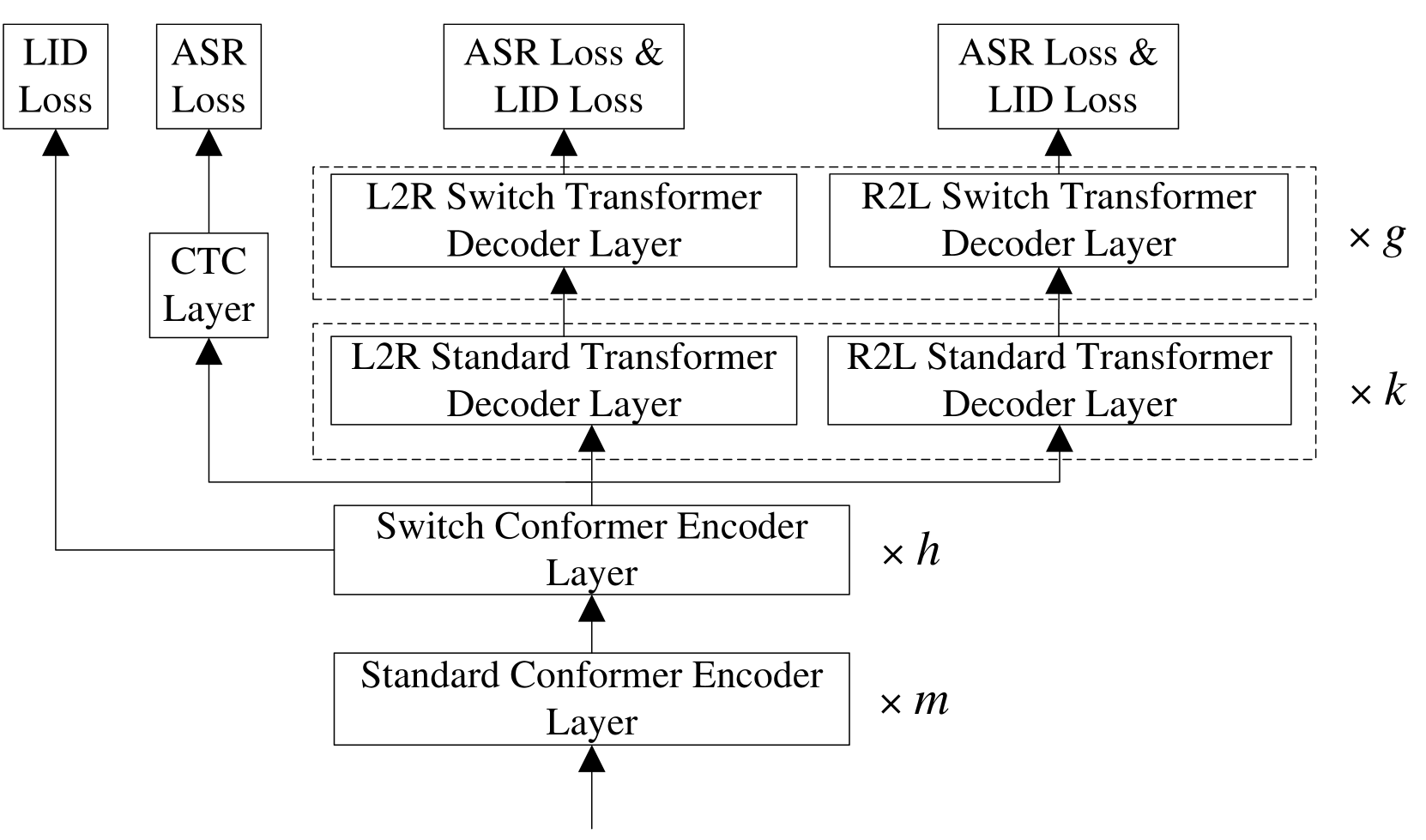
Switch Conformer (SC) Encoder: This encoder uses a novel "switch" mechanism to efficiently process speech signals that switch between multiple languages. It builds on the Conformer architecture, which combines convolutional and self-attention layers to capture both local and global speech features.
-
Mixture of Experts (MoE) Decoder: The decoder uses an MoE approach, where multiple specialized "expert" decoders are combined to handle different language pairs. This allows the model to learn language-specific representations and improve performance on code-switching tasks.
-
Unified Streaming and Non-streaming Training: SC-MoE is trained on both streaming and non-streaming data, enabling it to perform well in both real-time and offline code-switching ASR scenarios.
The researchers evaluate SC-MoE on several benchmark datasets for code-switching ASR, including CoSDA-ML and CSS10. They demonstrate that SC-MoE outperforms previous state-of-the-art models in terms of word error rate (WER) while maintaining low latency for streaming applications.
Critical Analysis
The paper provides a compelling solution for the challenging problem of code-switching ASR, which is an important capability for building inclusive speech recognition systems in multilingual environments.
One potential limitation is that the researchers only evaluate SC-MoE on a relatively small number of language pairs (English-Mandarin and English-Spanish). It would be valuable to see how the model performs on a wider range of language combinations, especially those with more significant linguistic differences.
Additionally, the paper does not provide much discussion of the computational efficiency and hardware requirements of the SC-MoE model. This information would be helpful for understanding the practical deployment considerations, especially for resourced-constrained edge devices.
Overall, the SC-MoE architecture represents an important advancement in code-switching ASR, and the researchers have made a valuable contribution to the field. Further exploration of the model's generalization capabilities and real-world deployment feasibility would be valuable next steps.
Conclusion
The SC-MoE model proposed in this paper is a significant step forward in building robust and inclusive automatic speech recognition systems for multilingual environments. By combining a Switch Conformer encoder and a Mixture of Experts decoder, the model can effectively handle code-switching scenarios while maintaining low latency for streaming applications.
The strong performance of SC-MoE on benchmark datasets demonstrates the potential for this approach to enable more accessible and equitable speech recognition technology, which is crucial for supporting diverse linguistic communities. As the researchers continue to refine and expand the model, it will be exciting to see how SC-MoE can be applied to real-world multilingual speech recognition challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SC-MoE: Switch Conformer Mixture of Experts for Unified Streaming and Non-streaming Code-Switching ASR
Shuaishuai Ye, Shunfei Chen, Xinhui Hu, Xinkang Xu
In this work, we propose a Switch-Conformer-based MoE system named SC-MoE for unified streaming and non-streaming code-switching (CS) automatic speech recognition (ASR), where we design a streaming MoE layer consisting of three language experts, which correspond to Mandarin, English, and blank, respectively, and equipped with a language identification (LID) network with a Connectionist Temporal Classification (CTC) loss as a router in the encoder of SC-MoE to achieve a real-time streaming CS ASR system. To further utilize the language information embedded in text, we also incorporate MoE layers into the decoder of SC-MoE. In addition, we introduce routers into every MoE layer of the encoder and the decoder and achieve better recognition performance. Experimental results show that the SC-MoE significantly improves CS ASR performances over baseline with comparable computational efficiency.
Read more6/27/2024

0
Boosting Code-Switching ASR with Mixture of Experts Enhanced Speech-Conditioned LLM
Fengrun Zhang, Wang Geng, Hukai Huang, Cheng Yi, He Qu
In this paper, we introduce a speech-conditioned Large Language Model (LLM) integrated with a Mixture of Experts (MoE) based connector to address the challenge of Code-Switching (CS) in Automatic Speech Recognition (ASR). Specifically, we propose an Insertion and Deletion of Interruption Token (IDIT) mechanism for better transfer text generation ability of LLM to speech recognition task. We also present a connecter with MoE architecture that manages multiple languages efficiently. To further enhance the collaboration of multiple experts and leverage the understanding capabilities of LLM, we propose a two-stage progressive training strategy: 1) The connector is unfrozen and trained with language-specialized experts to map speech representations to the text space. 2) The connector and LLM LoRA adaptor are trained with the proposed IDIT mechanism and all experts are activated to learn general representations. Experimental results demonstrate that our method significantly outperforms state-of-the-art models, including end-to-end and large-scale audio-language models.
Read more9/25/2024

0
Dynamic Language Group-Based MoE: Enhancing Efficiency and Flexibility for Code-Switching Speech Recognition
Hukai Huang, Shenghui Lu, Yahui Shan, He Qu, Wenhao Guan, Qingyang Hong, Lin Li
The Mixture of Experts (MoE) approach is well-suited for multilingual and code-switching (CS) tasks due to its multi-expert architecture. This work introduces the DLG-MoE, a Dynamic Language Group-based MoE optimized for bilingual and CS scenarios. DLG-MoE operates based on a hierarchical routing mechanism. First, the language router explicitly models the language and dispatches the representations to the corresponding language expert groups. Subsequently, the unsupervised router within each language group implicitly models attributes beyond language, and coordinates expert routing and collaboration. The model achieves state-of-the-art (SOTA) performance while also having unparalleled flexibility. It supports different top-k inference and streaming capabilities, and can also prune the model parameters to obtain a monolingual sub-model. The Code will be released.
Read more8/9/2024

0
Enhancing Code-Switching Speech Recognition with LID-Based Collaborative Mixture of Experts Model
Hukai Huang, Jiayan Lin, Kaidi Wang, Yishuang Li, Wenhao Guan, Lin Li, Qingyang Hong
Due to the inherent difficulty in modeling phonetic similarities across different languages, code-switching speech recognition presents a formidable challenge. This study proposes a Collaborative-MoE, a Mixture of Experts (MoE) model that leverages a collaborative mechanism among expert groups. Initially, a preceding routing network explicitly learns Language Identification (LID) tasks and selects experts based on acquired LID weights. This process ensures robust routing information to the MoE layer, mitigating interference from diverse language domains on expert network parameter updates. The LID weights are also employed to facilitate inter-group collaboration, enabling the integration of language-specific representations. Furthermore, within each language expert group, a gating network operates unsupervised to foster collaboration on attributes beyond language. Extensive experiments demonstrate the efficacy of our approach, achieving significant performance enhancements compared to alternative methods. Importantly, our method preserves the efficient inference capabilities characteristic of MoE models without necessitating additional pre-training.
Read more9/6/2024