U2++ MoE: Scaling 4.7x parameters with minimal impact on RTF

0
Sign in to get full access
Overview
- The paper describes a new technique called "U2++ MoE" that can scale up the number of parameters in a Mixture-of-Experts (MoE) model by 4.7x with minimal impact on the runtime and inference time.
- MoE models are a type of neural network architecture that uses multiple specialized "expert" models instead of a single large model.
- The key innovations in U2++ MoE include a new expert architecture and a specialized training process to achieve this parameter scaling with limited performance degradation.
Plain English Explanation
The paper presents a new way to build Mixture-of-Experts (MoE) models, which are a type of neural network that uses multiple specialized "expert" submodels instead of a single large model. The authors' technique, called "U2++ MoE", can increase the total number of parameters in the model by 4.7 times compared to previous approaches, while only having a minimal impact on the model's runtime and inference speed.
This is useful because larger models tend to perform better on complex tasks, but they also require more computing power and memory to run. MoE models aim to get the benefits of a large model by combining multiple smaller, more efficient expert models. The U2++ MoE approach takes this idea further by allowing the experts to be even larger without slowing down the overall model.
The key innovations in U2++ MoE include a new expert model architecture and a specialized training process. These technical details allow the model to scale up in size while maintaining its efficiency and speed. For a general audience, the main takeaway is that U2++ MoE represents an advance in building powerful AI models that can still be used in practical applications.
Technical Explanation
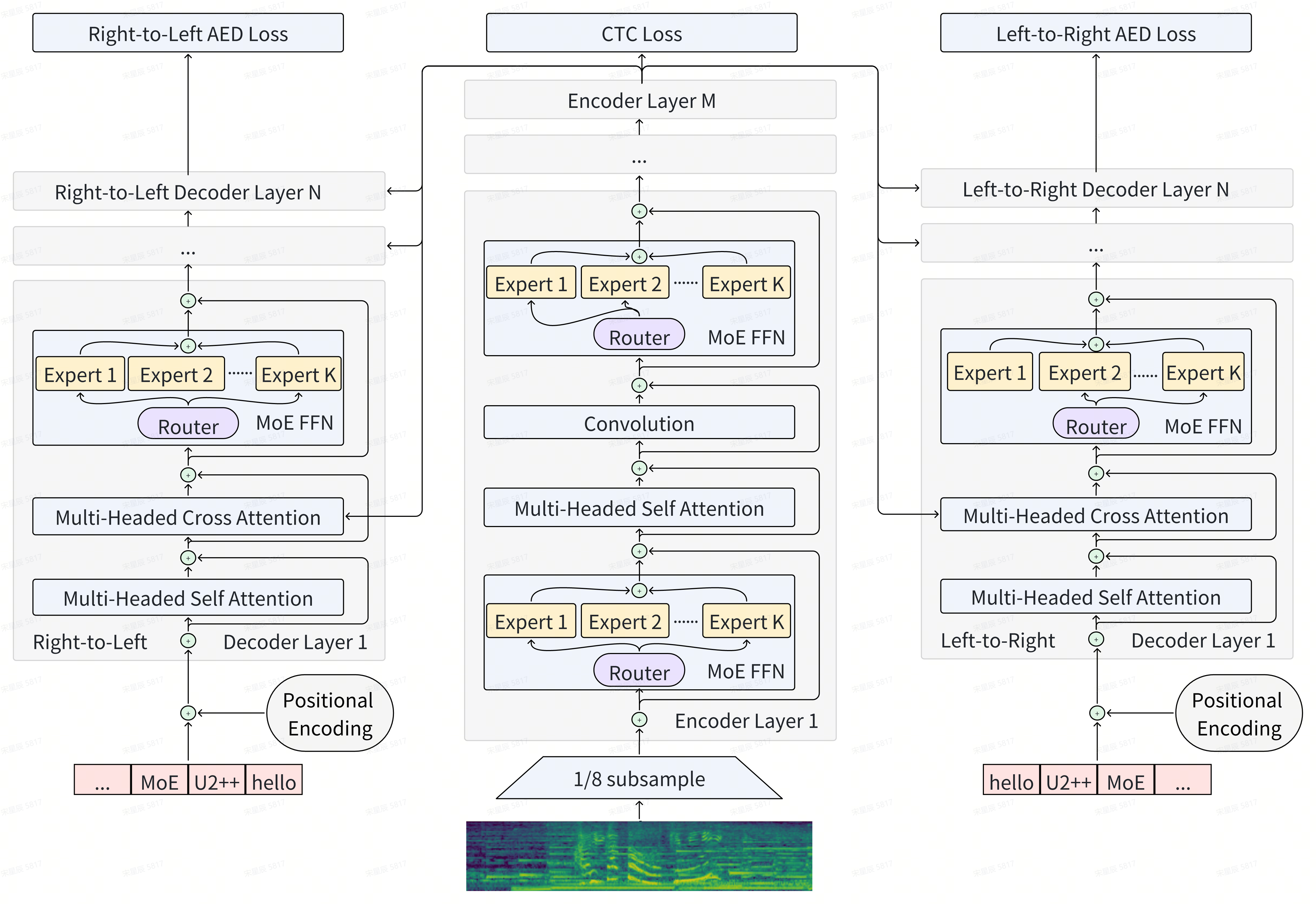
The paper introduces a new Mixture-of-Experts (MoE) architecture called "U2++ MoE" that can scale the number of parameters by 4.7x compared to prior approaches, with minimal impact on runtime and inference time (RTF).
MoE models use multiple specialized "expert" submodels, each focusing on a different part of the task, alongside a "router" that dynamically selects which experts to use for each input. This allows MoE models to be more efficient and adaptable than a single large model.
The key innovations in U2++ MoE include:
- A new expert model architecture that uses a rank-1 decomposition to dramatically increase the number of parameters without a proportional increase in computation.
- A specialized training process that sparsely activates the experts during training, forcing them to learn more efficient representations.
Through these technical advances, the U2++ MoE model is able to scale up the number of parameters by 4.7x compared to prior MoE approaches, while only experiencing a 12% increase in RTF. This allows U2++ MoE to achieve higher performance on complex tasks without becoming prohibitively expensive to run.
Critical Analysis
The paper provides a thorough technical explanation of the U2++ MoE architecture and training process. However, some potential limitations and areas for further research are worth considering:
-
The paper focuses on improving parameter scaling, but does not extensively evaluate the model's performance on downstream tasks compared to other large language models. Toward Inference-Optimal Mixture of Experts for Large Language Models could provide a useful comparison.
-
The training process relies on sparse activation of experts, which may make the model less robust to changes in the input distribution. Further research is needed to understand the long-term stability and generalization capabilities of U2++ MoE.
-
While the RTF increase is relatively modest, the power and memory requirements of the larger model may still limit its practical deployment, especially in resource-constrained environments. Techniques like SEER-MoE: Sparse Expert Efficiency through Regularization could help address this issue.
Overall, the U2++ MoE represents an interesting advance in scaling MoE models, but further empirical evaluation and practical considerations will be important to fully assess its impact and potential applications.
Conclusion
The U2++ MoE paper describes a novel technique for scaling up Mixture-of-Experts (MoE) models by 4.7x while maintaining reasonable runtime and inference speed. This is an important advancement, as larger models tend to perform better on complex tasks, but their increased computational and memory requirements can limit their practical deployment.
The key innovations in U2++ MoE include a new expert model architecture and a specialized training process that enables this parameter scaling with minimal performance degradation. While further research is needed to fully evaluate the model's long-term stability and real-world performance, the U2++ MoE represents a promising step forward in building powerful yet efficient AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
U2++ MoE: Scaling 4.7x parameters with minimal impact on RTF
Xingchen Song, Di Wu, Binbin Zhang, Dinghao Zhou, Zhendong Peng, Bo Dang, Fuping Pan, Chao Yang
Scale has opened new frontiers in natural language processing, but at a high cost. In response, by learning to only activate a subset of parameters in training and inference, Mixture-of-Experts (MoE) have been proposed as an energy efficient path to even larger and more capable language models and this shift towards a new generation of foundation models is gaining momentum, particularly within the field of Automatic Speech Recognition (ASR). Recent works that incorporating MoE into ASR models have complex designs such as routing frames via supplementary embedding network, improving multilingual ability for the experts, and utilizing dedicated auxiliary losses for either expert load balancing or specific language handling. We found that delicate designs are not necessary, while an embarrassingly simple substitution of MoE layers for all Feed-Forward Network (FFN) layers is competent for the ASR task. To be more specific, we benchmark our proposed model on a large scale inner-source dataset (160k hours), the results show that we can scale our baseline Conformer (Dense-225M) to its MoE counterparts (MoE-1B) and achieve Dense-1B level Word Error Rate (WER) while maintaining a Dense-225M level Real Time Factor (RTF). Furthermore, by applying Unified 2-pass framework with bidirectional attention decoders (U2++), we achieve the streaming and non-streaming decoding modes in a single MoE based model, which we call U2++ MoE. We hope that our study can facilitate the research on scaling speech foundation models without sacrificing deployment efficiency.
Read more8/9/2024
0
Toward Inference-optimal Mixture-of-Expert Large Language Models
Longfei Yun, Yonghao Zhuang, Yao Fu, Eric P Xing, Hao Zhang
Mixture-of-Expert (MoE) based large language models (LLMs), such as the recent Mixtral and DeepSeek-MoE, have shown great promise in scaling model size without suffering from the quadratic growth of training cost of dense transformers. Like dense models, training MoEs requires answering the same question: given a training budget, what is the optimal allocation on the model size and number of tokens? We study the scaling law of MoE-based LLMs regarding the relations between the model performance, model size, dataset size, and the expert degree. Echoing previous research studying MoE in different contexts, we observe the diminishing return of increasing the number of experts, but this seems to suggest we should scale the number of experts until saturation, as the training cost would remain constant, which is problematic during inference time. We propose to amend the scaling law of MoE by introducing inference efficiency as another metric besides the validation loss. We find that MoEs with a few (4/8) experts are the most serving efficient solution under the same performance, but costs 2.5-3.5x more in training. On the other hand, training a (16/32) expert MoE much smaller (70-85%) than the loss-optimal solution, but with a larger training dataset is a promising setup under a training budget.
Read more4/4/2024

218
Mixture of A Million Experts
Xu Owen He
The feedforward (FFW) layers in standard transformer architectures incur a linear increase in computational costs and activation memory as the hidden layer width grows. Sparse mixture-of-experts (MoE) architectures have emerged as a viable approach to address this issue by decoupling model size from computational cost. The recent discovery of the fine-grained MoE scaling law shows that higher granularity leads to better performance. However, existing MoE models are limited to a small number of experts due to computational and optimization challenges. This paper introduces PEER (parameter efficient expert retrieval), a novel layer design that utilizes the product key technique for sparse retrieval from a vast pool of tiny experts (over a million). Experiments on language modeling tasks demonstrate that PEER layers outperform dense FFWs and coarse-grained MoEs in terms of performance-compute trade-off. By enabling efficient utilization of a massive number of experts, PEER unlocks the potential for further scaling of transformer models while maintaining computational efficiency.
Read more7/8/2024
🚀
0
New!Time-MoE: Billion-Scale Time Series Foundation Models with Mixture of Experts
Xiaoming Shi, Shiyu Wang, Yuqi Nie, Dianqi Li, Zhou Ye, Qingsong Wen, Ming Jin
Deep learning for time series forecasting has seen significant advancements over the past decades. However, despite the success of large-scale pre-training in language and vision domains, pre-trained time series models remain limited in scale and operate at a high cost, hindering the development of larger capable forecasting models in real-world applications. In response, we introduce Time-MoE, a scalable and unified architecture designed to pre-train larger, more capable forecasting foundation models while reducing inference costs. By leveraging a sparse mixture-of-experts (MoE) design, Time-MoE enhances computational efficiency by activating only a subset of networks for each prediction, reducing computational load while maintaining high model capacity. This allows Time-MoE to scale effectively without a corresponding increase in inference costs. Time-MoE comprises a family of decoder-only transformer models that operate in an auto-regressive manner and support flexible forecasting horizons with varying input context lengths. We pre-trained these models on our newly introduced large-scale data Time-300B, which spans over 9 domains and encompassing over 300 billion time points. For the first time, we scaled a time series foundation model up to 2.4 billion parameters, achieving significantly improved forecasting precision. Our results validate the applicability of scaling laws for training tokens and model size in the context of time series forecasting. Compared to dense models with the same number of activated parameters or equivalent computation budgets, our models consistently outperform them by large margin. These advancements position Time-MoE as a state-of-the-art solution for tackling real-world time series forecasting challenges with superior capability, efficiency, and flexibility.
Read more9/25/2024