Scaling Data-Driven Building Energy Modelling using Large Language Models

0
💬
Sign in to get full access
Overview
- Building management systems (BMS) often face challenges with data and model scalability.
- Researchers propose using large language models (LLMs) to automate the data processing and model development for BMS.
- LLMs can incorporate domain knowledge to generate code for data-driven modeling tailored to specific building requirements.
- This approach aims to reduce the time, effort, and cost associated with manual data and model development.
Plain English Explanation
Building management systems (BMS) are used to automate and control various functions in buildings, such as heating, ventilation, and air conditioning (HVAC). However, developing data-driven models for BMS can be challenging due to issues with data scalability and model scalability.
The researchers propose using large language models (LLMs) to automate the data processing and model development for BMS. LLMs are AI models that can understand and generate human-like text, and they have shown impressive adaptability in code generation.
The idea is that LLMs can incorporate domain knowledge about data science and BMS to generate code that processes structured data from BMS and builds data-driven models tailored to the specific requirements of different building types and control objectives. This could eliminate the need for manual data and model development, reducing the time, effort, and cost associated with this process.
The researchers hypothesize that this approach can improve the accuracy and scalability of data-driven modeling for BMS, making it more accessible to a broader range of users.
Technical Explanation
The researchers propose a methodology to tackle the scalability challenges associated with the development of data-driven models for BMS by using LLMs. They use LLMs to generate code that processes structured data from BMS and builds data-driven models for BMS's specific requirements.
The researchers follow the framework of Machine Learning Operations (MLOps) to design a prompt template for the LLMs. This template systematically generates Python code for data-driven modeling, incorporating domain knowledge about data science and BMS.
The researchers conduct a case study to evaluate the effectiveness of their approach. They use a bi-sequential prompting technique, where the first prompt generates the overall code structure, and the second prompt fine-tunes the code for specific requirements. The results indicate that this approach can achieve a high success rate of code generation and code accuracy, significantly reducing human labor costs.
Critical Analysis
The researchers' approach of using LLMs to automate the data processing and model development for BMS is an innovative solution to address the scalability challenges faced by traditional methods. By incorporating domain knowledge, the researchers aim to ensure that the generated code and models are tailored to the specific requirements of different building types and control objectives.
However, the researchers acknowledge that their approach relies on the availability and quality of the training data for the LLMs. The performance of the generated code and models may be influenced by the completeness and accuracy of the training data, which could be a potential limitation.
Additionally, the researchers focus on structured data from BMS, but building management systems may also handle unstructured data, such as sensor logs, maintenance records, and occupant feedback. Extending the researchers' approach to handle unstructured data could be an area for further research.
The researchers also mention the potential for improved accuracy and scalability, but they do not provide a comprehensive evaluation of these metrics. Conducting a more thorough evaluation, including comparisons with traditional data and model development methods, could further strengthen the researchers' claims.
Conclusion
The researchers have proposed a novel approach to address the scalability challenges associated with the development of data-driven models for building management systems (BMS). By leveraging the code generation capabilities of large language models (LLMs), they aim to automate the data processing and model development process, reducing the time, effort, and cost involved.
If successful, this approach could enable broader adoption of BMS by making the technology more accessible to a wider range of users. The researchers' case study suggests that their bi-sequential prompting technique can generate accurate code with high success rates, indicating the potential for this method to improve the scalability and accuracy of data-driven modeling for BMS.
Further research is needed to address the limitations, such as the reliance on high-quality training data and the handling of unstructured data. Comprehensive evaluations of the approach's performance and comparisons with traditional methods could also provide valuable insights and help to solidify the researchers' claims.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Scaling Data-Driven Building Energy Modelling using Large Language Models
Sunil Khadka, Liang Zhang
Building Management System (BMS) through a data-driven method always faces data and model scalability issues. We propose a methodology to tackle the scalability challenges associated with the development of data-driven models for BMS by using Large Language Models (LLMs). LLMs' code generation adaptability can enable broader adoption of BMS by automating the automation, particularly the data handling and data-driven modeling processes. In this paper, we use LLMs to generate code that processes structured data from BMS and build data-driven models for BMS's specific requirements. This eliminates the need for manual data and model development, reducing the time, effort, and cost associated with this process. Our hypothesis is that LLMs can incorporate domain knowledge about data science and BMS into data processing and modeling, ensuring that the data-driven modeling is automated for specific requirements of different building types and control objectives, which also improves accuracy and scalability. We generate a prompt template following the framework of Machine Learning Operations so that the prompts are designed to systematically generate Python code for data-driven modeling. Our case study indicates that bi-sequential prompting under the prompt template can achieve a high success rate of code generation and code accuracy, and significantly reduce human labor costs.
Read more7/8/2024

0
Text2BIM: Generating Building Models Using a Large Language Model-based Multi-Agent Framework
Changyu Du, Sebastian Esser, Stavros Nousias, Andr'e Borrmann
The conventional BIM authoring process typically requires designers to master complex and tedious modeling commands in order to materialize their design intentions within BIM authoring tools. This additional cognitive burden complicates the design process and hinders the adoption of BIM and model-based design in the AEC (Architecture, Engineering, and Construction) industry. To facilitate the expression of design intentions more intuitively, we propose Text2BIM, an LLM-based multi-agent framework that can generate 3D building models from natural language instructions. This framework orchestrates multiple LLM agents to collaborate and reason, transforming textual user input into imperative code that invokes the BIM authoring tool's APIs, thereby generating editable BIM models with internal layouts, external envelopes, and semantic information directly in the software. Furthermore, a rule-based model checker is introduced into the agentic workflow, utilizing predefined domain knowledge to guide the LLM agents in resolving issues within the generated models and iteratively improving model quality. Extensive experiments were conducted to compare and analyze the performance of three different LLMs under the proposed framework. The evaluation results demonstrate that our approach can effectively generate high-quality, structurally rational building models that are aligned with the abstract concepts specified by user input. Finally, an interactive software prototype was developed to integrate the framework into the BIM authoring software Vectorworks, showcasing the potential of modeling by chatting.
Read more8/16/2024

0
Enabling Large Language Models to Perform Power System Simulations with Previously Unseen Tools: A Case of Daline
Mengshuo Jia, Zeyu Cui, Gabriela Hug
The integration of experiment technologies with large language models (LLMs) is transforming scientific research, offering AI capabilities beyond specialized problem-solving to becoming research assistants for human scientists. In power systems, simulations are essential for research. However, LLMs face significant challenges in power system simulations due to limited pre-existing knowledge and the complexity of power grids. To address this issue, this work proposes a modular framework that integrates expertise from both the power system and LLM domains. This framework enhances LLMs' ability to perform power system simulations on previously unseen tools. Validated using 34 simulation tasks in Daline, a (optimal) power flow simulation and linearization toolbox not yet exposed to LLMs, the proposed framework improved GPT-4o's simulation coding accuracy from 0% to 96.07%, also outperforming the ChatGPT-4o web interface's 33.8% accuracy (with the entire knowledge base uploaded). These results highlight the potential of LLMs as research assistants in power systems.
Read more6/27/2024
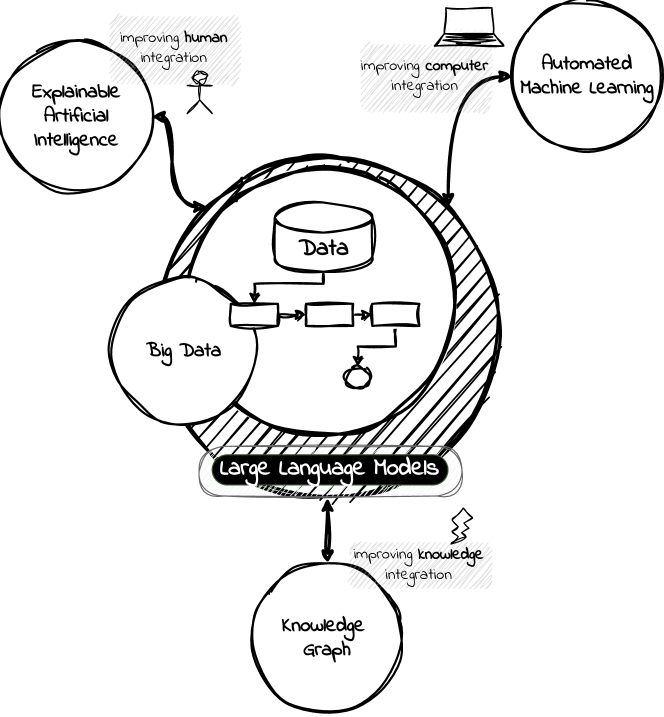
0
Are Large Language Models the New Interface for Data Pipelines?
Sylvio Barbon Junior, Paolo Ceravolo, Sven Groppe, Mustafa Jarrar, Samira Maghool, Florence S`edes, Soror Sahri, Maurice Van Keulen
A Language Model is a term that encompasses various types of models designed to understand and generate human communication. Large Language Models (LLMs) have gained significant attention due to their ability to process text with human-like fluency and coherence, making them valuable for a wide range of data-related tasks fashioned as pipelines. The capabilities of LLMs in natural language understanding and generation, combined with their scalability, versatility, and state-of-the-art performance, enable innovative applications across various AI-related fields, including eXplainable Artificial Intelligence (XAI), Automated Machine Learning (AutoML), and Knowledge Graphs (KG). Furthermore, we believe these models can extract valuable insights and make data-driven decisions at scale, a practice commonly referred to as Big Data Analytics (BDA). In this position paper, we provide some discussions in the direction of unlocking synergies among these technologies, which can lead to more powerful and intelligent AI solutions, driving improvements in data pipelines across a wide range of applications and domains integrating humans, computers, and knowledge.
Read more6/12/2024