Scaling Motion Forecasting Models with Ensemble Distillation
2404.03843
0
0

Abstract
Motion forecasting has become an increasingly critical component of autonomous robotic systems. Onboard compute budgets typically limit the accuracy of real-time systems. In this work we propose methods of improving motion forecasting systems subject to limited compute budgets by combining model ensemble and distillation techniques. The use of ensembles of deep neural networks has been shown to improve generalization accuracy in many application domains. We first demonstrate significant performance gains by creating a large ensemble of optimized single models. We then develop a generalized framework to distill motion forecasting model ensembles into small student models which retain high performance with a fraction of the computing cost. For this study we focus on the task of motion forecasting using real world data from autonomous driving systems. We develop ensemble models that are very competitive on the Waymo Open Motion Dataset (WOMD) and Argoverse leaderboards. From these ensembles, we train distilled student models which have high performance at a fraction of the compute costs. These experiments demonstrate distillation from ensembles as an effective method for improving accuracy of predictive models for robotic systems with limited compute budgets.
Create account to get full access
Overview
- This paper introduces a technique called "ensemble distillation" to scale up motion forecasting models while maintaining their performance.
- Motion forecasting is the task of predicting the future trajectories of objects, such as vehicles or pedestrians, based on their current and past movements.
- Ensemble models, which combine the predictions of multiple individual models, typically achieve better performance than single models. However, ensemble models can be computationally expensive and complex.
- The authors propose a way to distill the knowledge from an ensemble of motion forecasting models into a single, more compact model, without sacrificing too much performance.
Plain English Explanation
The paper is about a method to make motion forecasting models more efficient and easier to use. Motion forecasting is the task of predicting where things like cars or people will move in the future, based on where they are now and where they've been.
Typically, using multiple "expert" models together (an "ensemble") leads to better predictions than using a single model. However, ensemble models can be very complex and take a lot of computing power to run. The authors propose a way to take the knowledge from an ensemble of motion forecasting models and distill it into a single, simpler model. This "distilled" model can make predictions almost as good as the full ensemble, but is much faster and easier to use.
The key idea is to train the distilled model to mimic the outputs of the ensemble, rather than learning from scratch. This allows the distilled model to benefit from the collective knowledge of the ensemble, without having to be as large or complex. The authors show this approach can significantly reduce the computational cost of motion forecasting while maintaining high accuracy.
Technical Explanation
The paper presents a technique called "ensemble distillation" to scale up motion forecasting models. Motion forecasting is the task of predicting the future trajectories of dynamic objects, such as vehicles or pedestrians, based on their current and past movements.
Ensemble models, which combine the predictions of multiple individual models, have been shown to achieve better performance than single models for motion forecasting. However, ensemble models can be computationally expensive and complex, limiting their practical deployment.
The authors propose a way to distill the knowledge from an ensemble of motion forecasting models into a single, more compact model. This is done by training the distilled model to mimic the outputs of the ensemble, rather than learning from scratch. The key idea is to leverage the collective knowledge of the ensemble to train a simpler model that can make nearly as accurate predictions, but is much faster and easier to deploy.
The authors evaluate their ensemble distillation approach on several publicly available motion forecasting datasets. They show that the distilled model can achieve comparable or better performance than the full ensemble, while being significantly more efficient in terms of inference time and model size. For example, on the nuScenes dataset, the distilled model is 4.6x faster and has 6.5x fewer parameters than the ensemble, with only a 2.6% drop in prediction accuracy.
The authors also analyze the characteristics of the ensemble that lead to the most effective distillation, providing insights into the design of efficient motion forecasting models.
Critical Analysis
The authors make a compelling case for the value of ensemble distillation in motion forecasting. By effectively compressing the knowledge of an ensemble model into a single, more efficient model, this approach addresses a key practical limitation of ensemble models.
One potential limitation is that the distillation process may not fully capture all the nuances and edge cases learned by the ensemble. The authors acknowledge this and suggest further research into more sophisticated distillation techniques to mitigate this issue.
Additionally, the authors focus on improving the efficiency of motion forecasting models, but do not extensively discuss the broader implications of such models. It would be helpful to see a more in-depth discussion of the societal and ethical considerations of deploying these systems, such as their potential biases and impacts on vulnerable road users.
Overall, the paper presents a promising and well-executed approach to scaling up motion forecasting models through ensemble distillation. The authors provide a thoughtful technical contribution, and further research in this direction could lead to even more efficient and practical motion forecasting systems.
Conclusion
This paper introduces a technique called "ensemble distillation" to scale up motion forecasting models while maintaining their performance. By distilling the knowledge from an ensemble of motion forecasting models into a single, more compact model, the authors are able to achieve significant reductions in computational cost and model size, with only a small drop in prediction accuracy.
The key insight is that the distilled model can leverage the collective knowledge of the ensemble to make accurate predictions, without needing to be as large or complex. This addresses a practical limitation of ensemble models, which can be computationally expensive and difficult to deploy.
The authors demonstrate the effectiveness of their approach on several public motion forecasting datasets, showing that the distilled model can outperform the full ensemble in terms of efficiency, while maintaining comparable or better prediction performance. This work represents an important step towards more scalable and efficient motion forecasting systems that can be more widely deployed in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
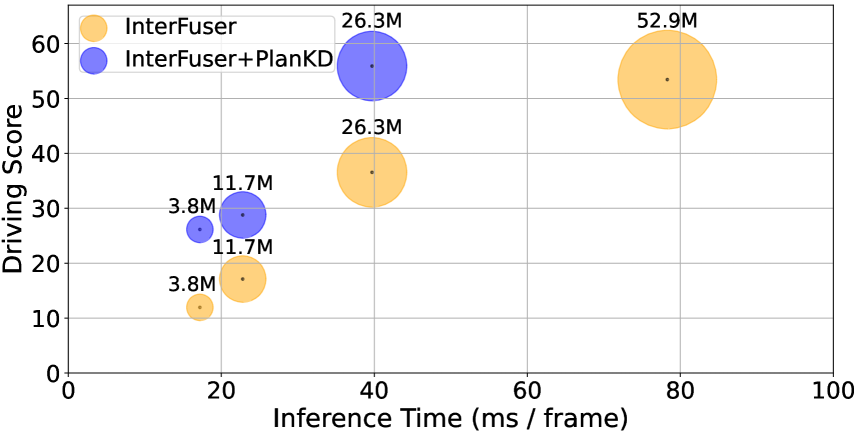
On the Road to Portability: Compressing End-to-End Motion Planner for Autonomous Driving
Kaituo Feng, Changsheng Li, Dongchun Ren, Ye Yuan, Guoren Wang
0
0
End-to-end motion planning models equipped with deep neural networks have shown great potential for enabling full autonomous driving. However, the oversized neural networks render them impractical for deployment on resource-constrained systems, which unavoidably requires more computational time and resources during reference.To handle this, knowledge distillation offers a promising approach that compresses models by enabling a smaller student model to learn from a larger teacher model. Nevertheless, how to apply knowledge distillation to compress motion planners has not been explored so far. In this paper, we propose PlanKD, the first knowledge distillation framework tailored for compressing end-to-end motion planners. First, considering that driving scenes are inherently complex, often containing planning-irrelevant or even noisy information, transferring such information is not beneficial for the student planner. Thus, we design an information bottleneck based strategy to only distill planning-relevant information, rather than transfer all information indiscriminately. Second, different waypoints in an output planned trajectory may hold varying degrees of importance for motion planning, where a slight deviation in certain crucial waypoints might lead to a collision. Therefore, we devise a safety-aware waypoint-attentive distillation module that assigns adaptive weights to different waypoints based on the importance, to encourage the student to accurately mimic more crucial waypoints, thereby improving overall safety. Experiments demonstrate that our PlanKD can boost the performance of smaller planners by a large margin, and significantly reduce their reference time.
4/16/2024
🔄
EqDrive: Efficient Equivariant Motion Forecasting with Multi-Modality for Autonomous Driving
Yuping Wang, Jier Chen
0
0
Forecasting vehicular motions in autonomous driving requires a deep understanding of agent interactions and the preservation of motion equivariance under Euclidean geometric transformations. Traditional models often lack the sophistication needed to handle the intricate dynamics inherent to autonomous vehicles and the interaction relationships among agents in the scene. As a result, these models have a lower model capacity, which then leads to higher prediction errors and lower training efficiency. In our research, we employ EqMotion, a leading equivariant particle, and human prediction model that also accounts for invariant agent interactions, for the task of multi-agent vehicle motion forecasting. In addition, we use a multi-modal prediction mechanism to account for multiple possible future paths in a probabilistic manner. By leveraging EqMotion, our model achieves state-of-the-art (SOTA) performance with fewer parameters (1.2 million) and a significantly reduced training time (less than 2 hours).
4/11/2024
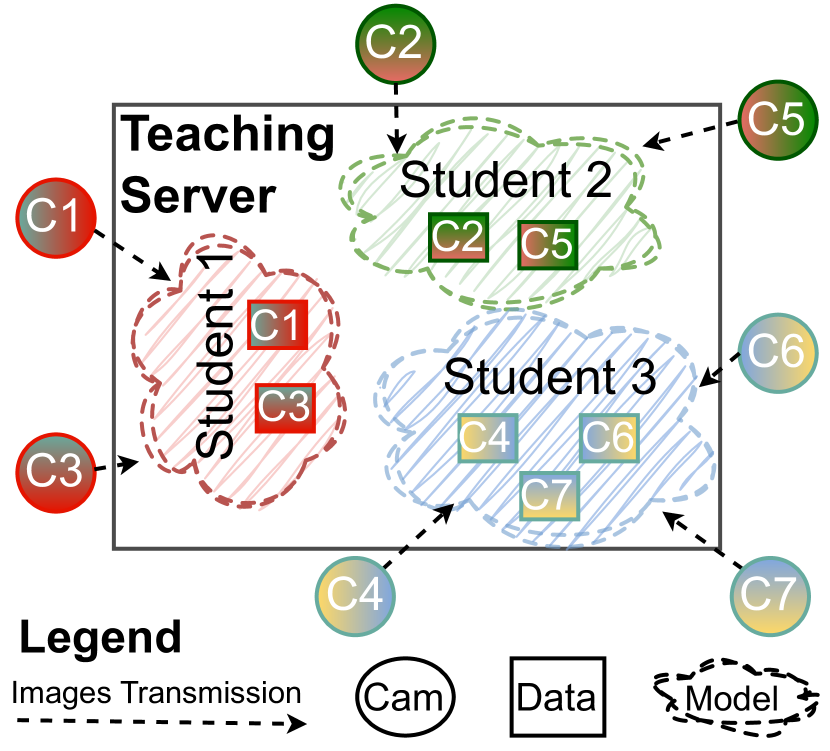
Camera clustering for scalable stream-based active distillation
Dani Manjah, Davide Cacciarelli, Christophe De Vleeschouwer, Benoit Macq
0
0
We present a scalable framework designed to craft efficient lightweight models for video object detection utilizing self-training and knowledge distillation techniques. We scrutinize methodologies for the ideal selection of training images from video streams and the efficacy of model sharing across numerous cameras. By advocating for a camera clustering methodology, we aim to diminish the requisite number of models for training while augmenting the distillation dataset. The findings affirm that proper camera clustering notably amplifies the accuracy of distilled models, eclipsing the methodologies that employ distinct models for each camera or a universal model trained on the aggregate camera data.
4/17/2024

Valeo4Cast: A Modular Approach to End-to-End Forecasting
Yihong Xu, 'Eloi Zablocki, Alexandre Boulch, Gilles Puy, Mickael Chen, Florent Bartoccioni, Nermin Samet, Oriane Sim'eoni, Spyros Gidaris, Tuan-Hung Vu, Andrei Bursuc, Eduardo Valle, Renaud Marlet, Matthieu Cord
0
0
Motion forecasting is crucial in autonomous driving systems to anticipate the future trajectories of surrounding agents such as pedestrians, vehicles, and traffic signals. In end-to-end forecasting, the model must jointly detect from sensor data (cameras or LiDARs) the position and past trajectories of the different elements of the scene and predict their future location. We depart from the current trend of tackling this task via end-to-end training from perception to forecasting and we use a modular approach instead. Following a recent study, we individually build and train detection, tracking, and forecasting modules. We then only use consecutive finetuning steps to integrate the modules better and alleviate compounding errors. Our study reveals that this simple yet effective approach significantly improves performance on the end-to-end forecasting benchmark. Consequently, our solution ranks first in the Argoverse 2 end-to-end Forecasting Challenge held at CVPR 2024 Workshop on Autonomous Driving (WAD), with 63.82 mAPf. We surpass forecasting results by +17.1 points over last year's winner and by +13.3 points over this year's runner-up. This remarkable performance in forecasting can be explained by our modular paradigm, which integrates finetuning strategies and significantly outperforms the end-to-end-trained counterparts.
6/13/2024