Towards Scalable & Efficient Interaction-Aware Planning in Autonomous Vehicles using Knowledge Distillation
2404.01746
0
0

Abstract
Real-world driving involves intricate interactions among vehicles navigating through dense traffic scenarios. Recent research focuses on enhancing the interaction awareness of autonomous vehicles to leverage these interactions in decision-making. These interaction-aware planners rely on neural-network-based prediction models to capture inter-vehicle interactions, aiming to integrate these predictions with traditional control techniques such as Model Predictive Control. However, this integration of deep learning-based models with traditional control paradigms often results in computationally demanding optimization problems, relying on heuristic methods. This study introduces a principled and efficient method for combining deep learning with constrained optimization, employing knowledge distillation to train smaller and more efficient networks, thereby mitigating complexity. We demonstrate that these refined networks maintain the problem-solving efficacy of larger models while significantly accelerating optimization. Specifically, in the domain of interaction-aware trajectory planning for autonomous vehicles, we illustrate that training a smaller prediction network using knowledge distillation speeds up optimization without sacrificing accuracy.
Create account to get full access
Overview
- This paper presents a novel approach for interaction-aware planning in autonomous vehicles using knowledge distillation.
- The key idea is to train a small, efficient neural network model to mimic the behavior of a larger, more complex model that can better capture the interactions between vehicles.
- The proposed method aims to achieve scalable and efficient planning for autonomous vehicles in real-world scenarios with many interacting agents.
Plain English Explanation
Autonomous vehicles, like self-driving cars, need to be able to plan their movements in a way that takes into account the actions of other nearby vehicles. This is called "interaction-aware planning." Traditionally, this type of planning has been done using large, complex models that can accurately capture these vehicle interactions, but they can be slow and computationally expensive.
The researchers in this paper propose a clever solution to this problem. They train a smaller, more efficient neural network model to essentially "mimic" the behavior of the larger, more complex model. This process is called "knowledge distillation." The key idea is that the smaller model can then be used for real-time planning in autonomous vehicles, while still capturing the essential interaction-aware behavior of the larger model.
This approach aims to provide scalable and efficient interaction-aware planning, which is important for autonomous vehicles to navigate complex, real-world driving scenarios safely and effectively.
Technical Explanation
The paper formulates the interaction-aware planning problem as a constrained optimization task, where the goal is to find the optimal trajectory for the autonomous vehicle while considering the predicted trajectories of surrounding vehicles. The authors use a large, neural network-based model to capture the complex interactions between vehicles.
To achieve scalable and efficient planning, the researchers employ a knowledge distillation approach. They train a smaller neural network model to mimic the behavior of the larger, more complex model. This is done by using the outputs of the larger model as "labels" to train the smaller model, effectively transferring the learned interaction-aware planning knowledge to the smaller model.
The authors evaluate their approach on various simulation scenarios and demonstrate that the distilled, smaller model can achieve comparable performance to the larger model, while being significantly more efficient in terms of computational cost and planning time. This makes the approach suitable for real-time deployment in autonomous vehicles.
Critical Analysis
The paper presents a compelling approach to addressing the challenge of interaction-aware planning in autonomous vehicles. The use of knowledge distillation to transfer the planning knowledge from a larger, more complex model to a smaller, more efficient model is a clever and innovative solution.
One potential limitation of the approach is that the performance of the distilled model may still be somewhat inferior to the larger, more comprehensive model, especially in complex or edge cases. The authors acknowledge this and suggest further research to improve the distillation process and the fidelity of the distilled model.
Additionally, the paper focuses on simulation-based evaluation, and real-world deployment of the approach may introduce additional challenges and considerations. Further experimentation and validation in real-world driving scenarios would be valuable to fully assess the practical applicability of the proposed method.
Conclusion
This paper presents a novel approach for achieving scalable and efficient interaction-aware planning in autonomous vehicles using knowledge distillation. By training a smaller neural network model to mimic the behavior of a larger, more complex model, the researchers have developed a solution that can capture the essential interaction-aware planning capabilities while being computationally efficient enough for real-time deployment.
The proposed method has the potential to significantly advance the state of the art in autonomous vehicle planning, enabling these vehicles to navigate complex, real-world driving scenarios more safely and effectively. While there are some remaining challenges and areas for further research, this work represents an important step forward in addressing a critical problem in the field of autonomous driving.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
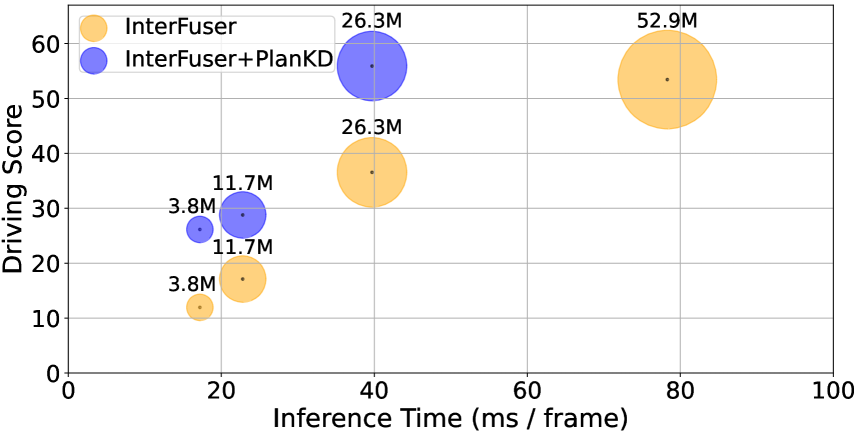
On the Road to Portability: Compressing End-to-End Motion Planner for Autonomous Driving
Kaituo Feng, Changsheng Li, Dongchun Ren, Ye Yuan, Guoren Wang
0
0
End-to-end motion planning models equipped with deep neural networks have shown great potential for enabling full autonomous driving. However, the oversized neural networks render them impractical for deployment on resource-constrained systems, which unavoidably requires more computational time and resources during reference.To handle this, knowledge distillation offers a promising approach that compresses models by enabling a smaller student model to learn from a larger teacher model. Nevertheless, how to apply knowledge distillation to compress motion planners has not been explored so far. In this paper, we propose PlanKD, the first knowledge distillation framework tailored for compressing end-to-end motion planners. First, considering that driving scenes are inherently complex, often containing planning-irrelevant or even noisy information, transferring such information is not beneficial for the student planner. Thus, we design an information bottleneck based strategy to only distill planning-relevant information, rather than transfer all information indiscriminately. Second, different waypoints in an output planned trajectory may hold varying degrees of importance for motion planning, where a slight deviation in certain crucial waypoints might lead to a collision. Therefore, we devise a safety-aware waypoint-attentive distillation module that assigns adaptive weights to different waypoints based on the importance, to encourage the student to accurately mimic more crucial waypoints, thereby improving overall safety. Experiments demonstrate that our PlanKD can boost the performance of smaller planners by a large margin, and significantly reduce their reference time.
4/16/2024
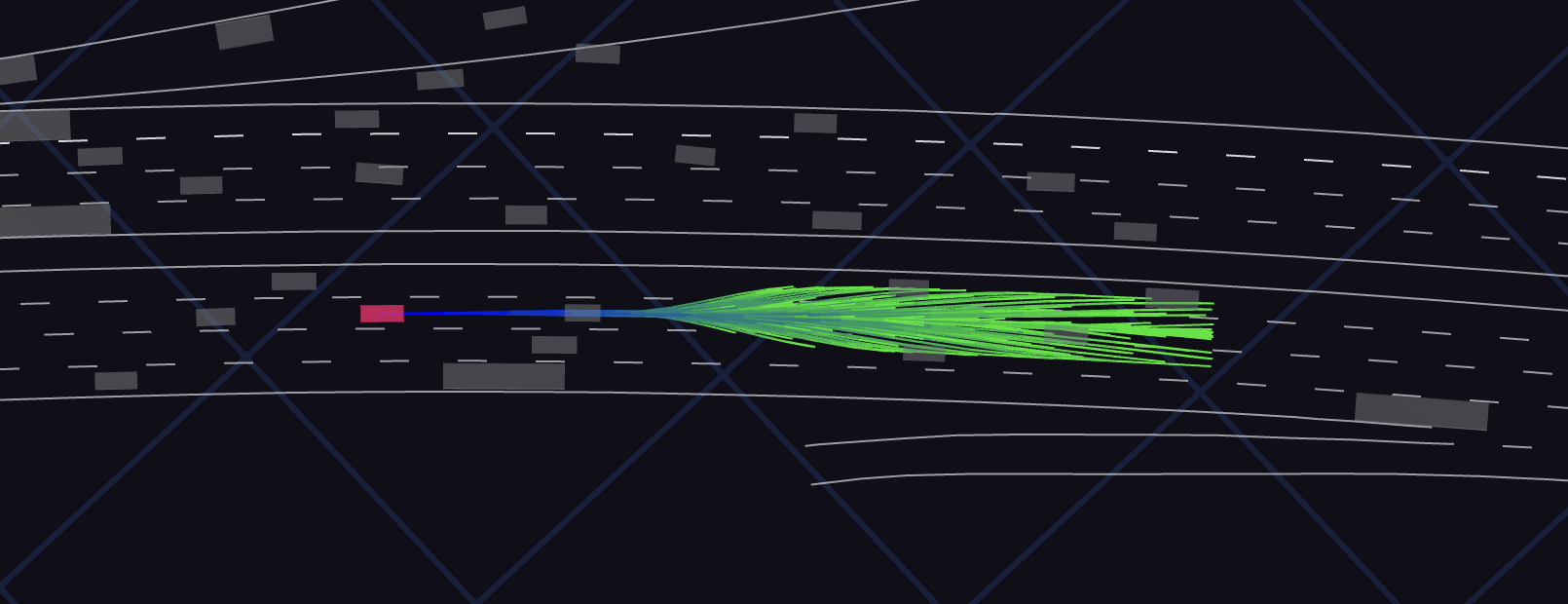
QuAD: Query-based Interpretable Neural Motion Planning for Autonomous Driving
Sourav Biswas, Sergio Casas, Quinlan Sykora, Ben Agro, Abbas Sadat, Raquel Urtasun
0
0
A self-driving vehicle must understand its environment to determine the appropriate action. Traditional autonomy systems rely on object detection to find the agents in the scene. However, object detection assumes a discrete set of objects and loses information about uncertainty, so any errors compound when predicting the future behavior of those agents. Alternatively, dense occupancy grid maps have been utilized to understand free-space. However, predicting a grid for the entire scene is wasteful since only certain spatio-temporal regions are reachable and relevant to the self-driving vehicle. We present a unified, interpretable, and efficient autonomy framework that moves away from cascading modules that first perceive, then predict, and finally plan. Instead, we shift the paradigm to have the planner query occupancy at relevant spatio-temporal points, restricting the computation to those regions of interest. Exploiting this representation, we evaluate candidate trajectories around key factors such as collision avoidance, comfort, and progress for safety and interpretability. Our approach achieves better highway driving quality than the state-of-the-art in high-fidelity closed-loop simulations.
4/3/2024

Small Scale Data-Free Knowledge Distillation
He Liu, Yikai Wang, Huaping Liu, Fuchun Sun, Anbang Yao
0
0
Data-free knowledge distillation is able to utilize the knowledge learned by a large teacher network to augment the training of a smaller student network without accessing the original training data, avoiding privacy, security, and proprietary risks in real applications. In this line of research, existing methods typically follow an inversion-and-distillation paradigm in which a generative adversarial network on-the-fly trained with the guidance of the pre-trained teacher network is used to synthesize a large-scale sample set for knowledge distillation. In this paper, we reexamine this common data-free knowledge distillation paradigm, showing that there is considerable room to improve the overall training efficiency through a lens of ``small-scale inverted data for knowledge distillation. In light of three empirical observations indicating the importance of how to balance class distributions in terms of synthetic sample diversity and difficulty during both data inversion and distillation processes, we propose Small Scale Data-free Knowledge Distillation SSD-KD. In formulation, SSD-KD introduces a modulating function to balance synthetic samples and a priority sampling function to select proper samples, facilitated by a dynamic replay buffer and a reinforcement learning strategy. As a result, SSD-KD can perform distillation training conditioned on an extremely small scale of synthetic samples (e.g., 10X less than the original training data scale), making the overall training efficiency one or two orders of magnitude faster than many mainstream methods while retaining superior or competitive model performance, as demonstrated on popular image classification and semantic segmentation benchmarks. The code is available at https://github.com/OSVAI/SSD-KD.
6/13/2024
🤖
Enhance Planning with Physics-informed Safety Controllor for End-to-end Autonomous Driving
Hang Zhou, Haichao Liu, Hongliang Lu, Dan Xu, Jun Ma, Yiding Ji
0
0
Recent years have seen a growing research interest in applications of Deep Neural Networks (DNN) on autonomous vehicle technology. The trend started with perception and prediction a few years ago and it is gradually being applied to motion planning tasks. Despite the performance of networks improve over time, DNN planners inherit the natural drawbacks of Deep Learning. Learning-based planners have limitations in achieving perfect accuracy on the training dataset and network performance can be affected by out-of-distribution problem. In this paper, we propose FusionAssurance, a novel trajectory-based end-to-end driving fusion framework which combines physics-informed control for safety assurance. By incorporating Potential Field into Model Predictive Control, FusionAssurance is capable of navigating through scenarios that are not included in the training dataset and scenarios where neural network fail to generalize. The effectiveness of the approach is demonstrated by extensive experiments under various scenarios on the CARLA benchmark.
5/7/2024