Scaling ResNets in the Large-depth Regime

0
📉
Sign in to get full access
Overview
- Deep ResNet architectures have achieved state-of-the-art results in complex machine learning tasks
- The remarkable performance of these models relies on a carefully crafted training procedure to avoid vanishing or exploding gradients, especially as the depth increases
- There is no consensus on how to mitigate this issue, though a widely discussed strategy is to scale the output of each layer by a factor
$\alpha_L$ - This paper analyzes the dynamics of deep ResNets from a probabilistic standpoint and provides insights on the relationship between scaling and the regularity of the weights across layers
Plain English Explanation
Deep ResNet models are known for their exceptional performance on challenging machine learning problems. However, the training of these very deep neural networks can be tricky, as the gradients used to update the model's parameters during training may become too small (vanishing gradients) or too large (exploding gradients) as the depth of the network increases.
To address this issue, researchers have explored various strategies, including scaling the output of each layer by a factor $\alpha_L$. This paper takes a closer look at the dynamics of deep ResNets from a probabilistic perspective and shows that the only non-trivial solution for this scaling factor is $\alpha_L = \frac{1}{\sqrt{L}}$, where $L$ is the depth of the network. Other choices lead to either an explosion or an identity mapping, which is not desirable.
Interestingly, the authors find that this scaling factor corresponds to a neural stochastic differential equation in the continuous-time limit, rather than a discretization of a neural ordinary differential equation, which is a common interpretation of deep ResNets. In the latter regime, stability is achieved with specific correlated initializations and a scaling factor of $\alpha_L = \frac{1}{L}$.
The analysis suggests that there is a strong relationship between the scaling factor $\alpha_L$ and the regularity of the weights as a function of the layer index. The authors also present a series of experiments that demonstrate a continuous range of regimes driven by these two parameters, which jointly impact the model's performance before and after training.
Technical Explanation
The paper analyzes the dynamics of deep ResNet architectures from a probabilistic standpoint. The authors show that with standard i.i.d. initializations, the only non-trivial dynamics for the scaling factor $\alpha_L$ is $\alpha_L = \frac{1}{\sqrt{L}}$, where $L$ is the depth of the network. Other choices for $\alpha_L$ lead either to an explosion or an identity mapping.
This scaling factor corresponds to a neural stochastic differential equation in the continuous-time limit, which is in contrast with the widespread interpretation of deep ResNets as discretizations of neural ordinary differential equations. In the latter regime, the authors find that stability is obtained with specific correlated initializations and $\alpha_L = \frac{1}{L}$.
The analysis suggests a strong interplay between the scaling factor $\alpha_L$ and the regularity of the weights as a function of the layer index. The authors present a series of experiments that exhibit a continuous range of regimes driven by these two parameters, which jointly impact the model's performance before and after training.
Critical Analysis
The paper provides a comprehensive theoretical analysis of the dynamics of deep ResNet architectures, offering insights into the relationship between the scaling factor $\alpha_L$ and the regularity of the weights across layers. The authors' findings challenge the common interpretation of deep ResNets as discretizations of neural ordinary differential equations and suggest that a more nuanced understanding of the underlying dynamics is needed.
However, the paper does not address the practical implications of these insights for the design and training of deep ResNet models. It would be interesting to see how the authors' recommendations for scaling and weight initialization could be incorporated into existing ResNet architectures and training procedures to improve their performance and stability.
Additionally, the paper focuses on a specific probabilistic setting and may not capture the full complexity of real-world deep learning scenarios. Further research is needed to understand the generalizability of these findings and their applicability to a wider range of deep learning architectures and tasks.
Conclusion
This paper provides a deep, probabilistic analysis of the dynamics of deep ResNet architectures, shedding light on the importance of the scaling factor $\alpha_L$ and the regularity of the weights across layers. The authors' findings challenge the common interpretation of deep ResNets as discretizations of neural ordinary differential equations and suggest that a more nuanced understanding of the underlying dynamics is required.
While the theoretical insights are valuable, the practical implications for the design and training of deep ResNet models remain to be explored. Further research is needed to understand the broader applicability of these findings and to incorporate them into the development of more stable and high-performing deep learning architectures.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
0
Scaling ResNets in the Large-depth Regime
Pierre Marion, Adeline Fermanian, G'erard Biau, Jean-Philippe Vert
Deep ResNets are recognized for achieving state-of-the-art results in complex machine learning tasks. However, the remarkable performance of these architectures relies on a training procedure that needs to be carefully crafted to avoid vanishing or exploding gradients, particularly as the depth $L$ increases. No consensus has been reached on how to mitigate this issue, although a widely discussed strategy consists in scaling the output of each layer by a factor $alpha_L$. We show in a probabilistic setting that with standard i.i.d.~initializations, the only non-trivial dynamics is for $alpha_L = frac{1}{sqrt{L}}$; other choices lead either to explosion or to identity mapping. This scaling factor corresponds in the continuous-time limit to a neural stochastic differential equation, contrarily to a widespread interpretation that deep ResNets are discretizations of neural ordinary differential equations. By contrast, in the latter regime, stability is obtained with specific correlated initializations and $alpha_L = frac{1}{L}$. Our analysis suggests a strong interplay between scaling and regularity of the weights as a function of the layer index. Finally, in a series of experiments, we exhibit a continuous range of regimes driven by these two parameters, which jointly impact performance before and after training.
Read more6/11/2024
🧠
0
Explaining Neural Scaling Laws
Yasaman Bahri, Ethan Dyer, Jared Kaplan, Jaehoon Lee, Utkarsh Sharma
The population loss of trained deep neural networks often follows precise power-law scaling relations with either the size of the training dataset or the number of parameters in the network. We propose a theory that explains the origins of and connects these scaling laws. We identify variance-limited and resolution-limited scaling behavior for both dataset and model size, for a total of four scaling regimes. The variance-limited scaling follows simply from the existence of a well-behaved infinite data or infinite width limit, while the resolution-limited regime can be explained by positing that models are effectively resolving a smooth data manifold. In the large width limit, this can be equivalently obtained from the spectrum of certain kernels, and we present evidence that large width and large dataset resolution-limited scaling exponents are related by a duality. We exhibit all four scaling regimes in the controlled setting of large random feature and pretrained models and test the predictions empirically on a range of standard architectures and datasets. We also observe several empirical relationships between datasets and scaling exponents under modifications of task and architecture aspect ratio. Our work provides a taxonomy for classifying different scaling regimes, underscores that there can be different mechanisms driving improvements in loss, and lends insight into the microscopic origins of and relationships between scaling exponents.
Read more4/30/2024

0
Compelling ReLU Network Initialization and Training to Leverage Exponential Scaling with Depth
Max Milkert, David Hyde, Forrest Laine
A neural network with ReLU activations may be viewed as a composition of piecewise linear functions. For such networks, the number of distinct linear regions expressed over the input domain has the potential to scale exponentially with depth, but it is not expected to do so when the initial parameters are chosen randomly. This poor scaling can necessitate the use of overly large models to approximate even simple functions. To address this issue, we introduce a novel training strategy: we first reparameterize the network weights in a manner that forces the network to display a number of activation patterns exponential in depth. Training first on our derived parameters provides an initial solution that can later be refined by directly updating the underlying model weights. This approach allows us to learn approximations of convex, one-dimensional functions that are several orders of magnitude more accurate than their randomly initialized counterparts.
Read more6/4/2024
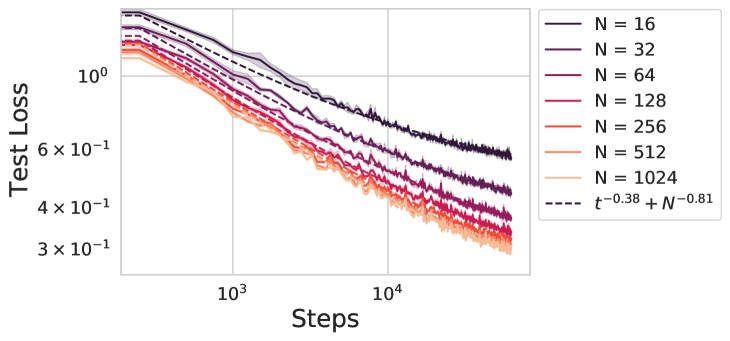
0
A Dynamical Model of Neural Scaling Laws
Blake Bordelon, Alexander Atanasov, Cengiz Pehlevan
On a variety of tasks, the performance of neural networks predictably improves with training time, dataset size and model size across many orders of magnitude. This phenomenon is known as a neural scaling law. Of fundamental importance is the compute-optimal scaling law, which reports the performance as a function of units of compute when choosing model sizes optimally. We analyze a random feature model trained with gradient descent as a solvable model of network training and generalization. This reproduces many observations about neural scaling laws. First, our model makes a prediction about why the scaling of performance with training time and with model size have different power law exponents. Consequently, the theory predicts an asymmetric compute-optimal scaling rule where the number of training steps are increased faster than model parameters, consistent with recent empirical observations. Second, it has been observed that early in training, networks converge to their infinite-width dynamics at a rate $1/textit{width}$ but at late time exhibit a rate $textit{width}^{-c}$, where $c$ depends on the structure of the architecture and task. We show that our model exhibits this behavior. Lastly, our theory shows how the gap between training and test loss can gradually build up over time due to repeated reuse of data.
Read more6/26/2024