A Dynamical Model of Neural Scaling Laws
2402.01092
0
0
Abstract
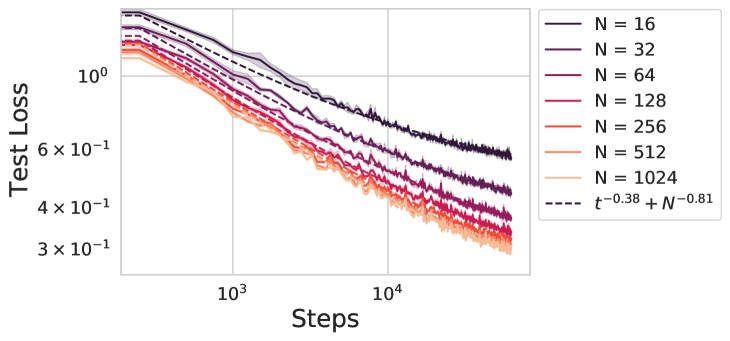
On a variety of tasks, the performance of neural networks predictably improves with training time, dataset size and model size across many orders of magnitude. This phenomenon is known as a neural scaling law. Of fundamental importance is the compute-optimal scaling law, which reports the performance as a function of units of compute when choosing model sizes optimally. We analyze a random feature model trained with gradient descent as a solvable model of network training and generalization. This reproduces many observations about neural scaling laws. First, our model makes a prediction about why the scaling of performance with training time and with model size have different power law exponents. Consequently, the theory predicts an asymmetric compute-optimal scaling rule where the number of training steps are increased faster than model parameters, consistent with recent empirical observations. Second, it has been observed that early in training, networks converge to their infinite-width dynamics at a rate $1/textit{width}$ but at late time exhibit a rate $textit{width}^{-c}$, where $c$ depends on the structure of the architecture and task. We show that our model exhibits this behavior. Lastly, our theory shows how the gap between training and test loss can gradually build up over time due to repeated reuse of data.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Neural networks have shown remarkable scaling properties, where their performance improves as the models become larger and are trained on more data.
- Researchers have observed that the test loss of neural networks scales as a power-law in training time, model size, and compute.
- This paper proposes a dynamical model to explain these scaling laws, using techniques from statistical physics and mean field theory.
Plain English Explanation
Neural networks, the algorithms that power many modern AI systems, have an interesting property: as they get bigger and are trained for longer, their performance tends to improve in a predictable way. Researchers have observed that the error rate, or "test loss", of these models decreases following a power-law relationship with the training time, the size of the model, and the amount of compute power used.
This paper presents a mathematical model to explain these scaling laws. The authors use techniques from statistical physics, like "mean field theory," to analyze how the dynamics of neural network training lead to these observed power-law relationships. Their model provides a theoretical framework for understanding the underlying mechanisms that give rise to the remarkable scalability of modern AI systems.
Technical Explanation
The paper proposes a dynamical model to explain the observed power-law scaling of neural network performance with training time, model size, and compute. The authors use a mean field theory approach, treating the network as a collection of interacting neurons in the infinite-width limit.
The key insights from their model are:
- The test loss decreases as a power-law in training time, with an exponent that depends on the network architecture and task.
- The test loss also scales as a power-law in model size and compute, with exponents that can be related to the training time exponent.
- The power-law exponents arise from the collective, mean-field-like dynamics of the neural network during training.
The authors validate their model through numerical simulations and comparisons to empirical scaling laws observed in real-world neural networks.
Critical Analysis
The paper provides a principled, physics-inspired framework for understanding the scaling properties of neural networks. By modeling the network as a statistical system in the infinite-width limit, the authors are able to derive analytical expressions for the power-law exponents governing the scaling of test loss.
However, the model makes several simplifying assumptions, such as treating the network as a mean-field system and neglecting finite-width effects. While these assumptions allow for analytical tractability, they may limit the model's ability to capture the full complexity of real-world neural network training dynamics.
Additionally, the paper focuses on the scaling of test loss, but does not address other important performance metrics, such as generalization capability or training efficiency. Further research is needed to understand how the proposed dynamical model relates to these other aspects of neural network performance.
Conclusion
This paper presents a promising theoretical framework for understanding the remarkable scaling properties of modern neural networks. By modeling the network training process as a mean-field statistical system, the authors are able to derive analytical expressions for the power-law scaling of test loss with training time, model size, and compute. While the model makes simplifying assumptions, it provides a new perspective on the underlying mechanisms behind the observed scaling laws in AI systems. This work lays the groundwork for further research into the fundamental principles governing the scalability of deep learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
Explaining Neural Scaling Laws
Yasaman Bahri, Ethan Dyer, Jared Kaplan, Jaehoon Lee, Utkarsh Sharma
0
0
The population loss of trained deep neural networks often follows precise power-law scaling relations with either the size of the training dataset or the number of parameters in the network. We propose a theory that explains the origins of and connects these scaling laws. We identify variance-limited and resolution-limited scaling behavior for both dataset and model size, for a total of four scaling regimes. The variance-limited scaling follows simply from the existence of a well-behaved infinite data or infinite width limit, while the resolution-limited regime can be explained by positing that models are effectively resolving a smooth data manifold. In the large width limit, this can be equivalently obtained from the spectrum of certain kernels, and we present evidence that large width and large dataset resolution-limited scaling exponents are related by a duality. We exhibit all four scaling regimes in the controlled setting of large random feature and pretrained models and test the predictions empirically on a range of standard architectures and datasets. We also observe several empirical relationships between datasets and scaling exponents under modifications of task and architecture aspect ratio. Our work provides a taxonomy for classifying different scaling regimes, underscores that there can be different mechanisms driving improvements in loss, and lends insight into the microscopic origins of and relationships between scaling exponents.
4/30/2024
📈
An exactly solvable model for emergence and scaling laws
Yoonsoo Nam, Nayara Fonseca, Seok Hyeong Lee, Ard Louis
0
0
Deep learning models can exhibit what appears to be a sudden ability to solve a new problem as training time ($T$), training data ($D$), or model size ($N$) increases, a phenomenon known as emergence. In this paper, we present a framework where each new ability (a skill) is represented as a basis function. We solve a simple multi-linear model in this skill-basis, finding analytic expressions for the emergence of new skills, as well as for scaling laws of the loss with training time, data size, model size, and optimal compute ($C$). We compare our detailed calculations to direct simulations of a two-layer neural network trained on multitask sparse parity, where the tasks in the dataset are distributed according to a power-law. Our simple model captures, using a single fit parameter, the sigmoidal emergence of multiple new skills as training time, data size or model size increases in the neural network.
4/29/2024
A Resource Model For Neural Scaling Law
Jinyeop Song, Ziming Liu, Max Tegmark, Jeff Gore
0
0
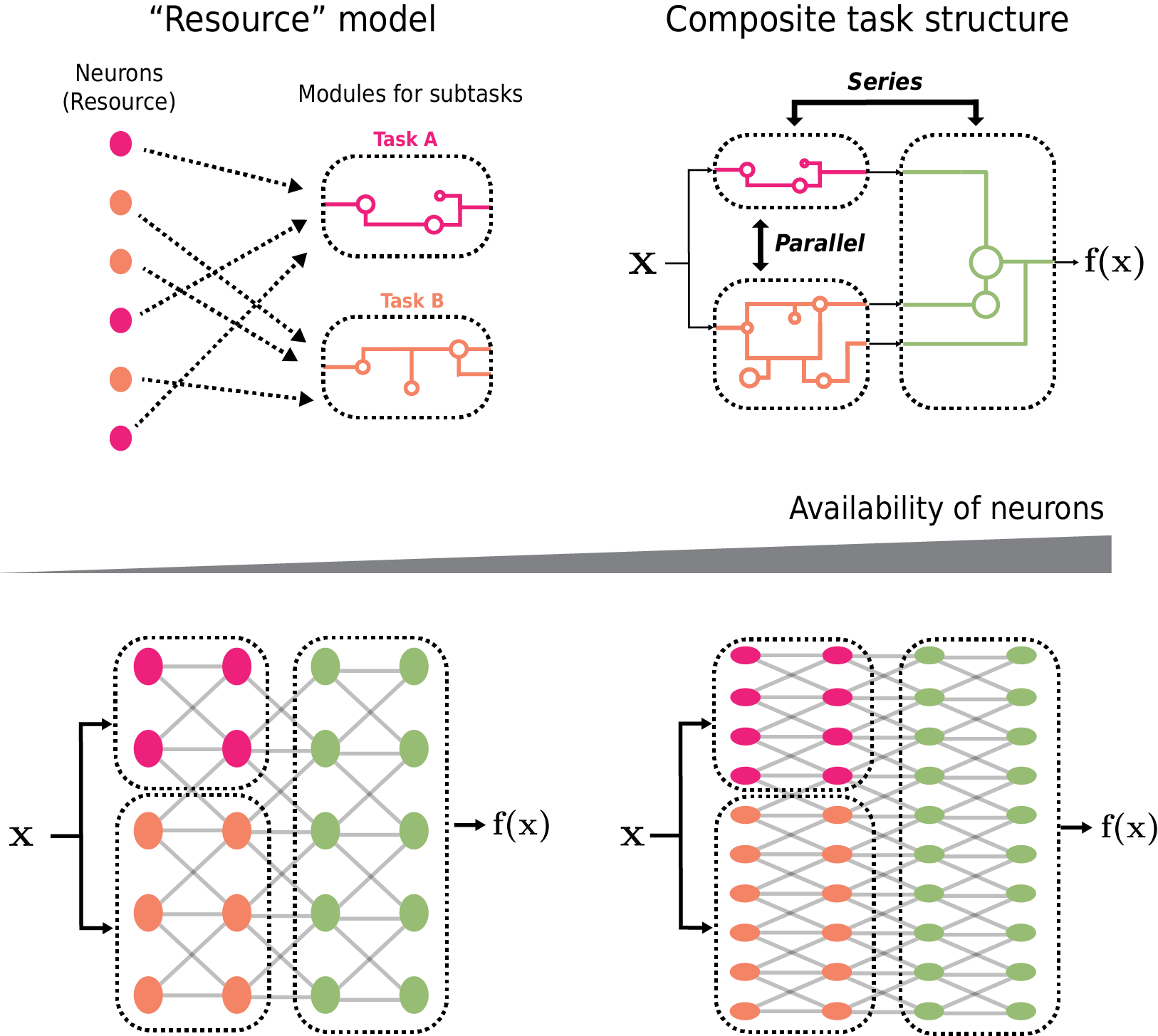
Neural scaling laws characterize how model performance improves as the model size scales up. Inspired by empirical observations, we introduce a resource model of neural scaling. A task is usually composite hence can be decomposed into many subtasks, which compete for resources (measured by the number of neurons allocated to subtasks). On toy problems, we empirically find that: (1) The loss of a subtask is inversely proportional to its allocated neurons. (2) When multiple subtasks are present in a composite task, the resources acquired by each subtask uniformly grow as models get larger, keeping the ratios of acquired resources constants. We hypothesize these findings to be generally true and build a model to predict neural scaling laws for general composite tasks, which successfully replicates the neural scaling law of Chinchilla models reported in arXiv:2203.15556. We believe that the notion of resource used in this paper will be a useful tool for characterizing and diagnosing neural networks.
5/16/2024
Unraveling the Mystery of Scaling Laws: Part I
Hui Su, Zhi Tian, Xiaoyu Shen, Xunliang Cai
0
0
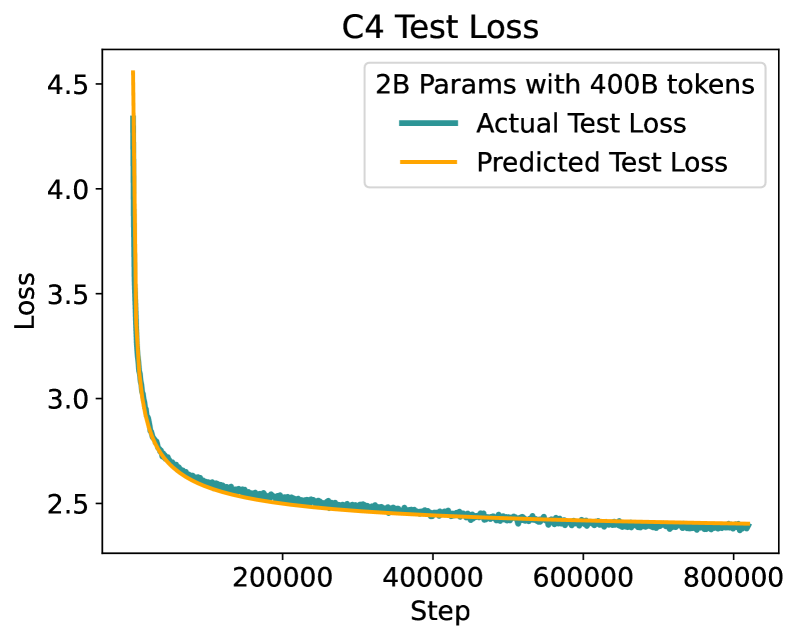
Scaling law principles indicate a power-law correlation between loss and variables such as model size, dataset size, and computational resources utilized during training. These principles play a vital role in optimizing various aspects of model pre-training, ultimately contributing to the success of large language models such as GPT-4, Llama and Gemini. However, the original scaling law paper by OpenAI did not disclose the complete details necessary to derive the precise scaling law formulas, and their conclusions are only based on models containing up to 1.5 billion parameters. Though some subsequent works attempt to unveil these details and scale to larger models, they often neglect the training dependency of important factors such as the learning rate, context length and batch size, leading to their failure to establish a reliable formula for predicting the test loss trajectory. In this technical report, we confirm that the scaling law formulations proposed in the original OpenAI paper remain valid when scaling the model size up to 33 billion, but the constant coefficients in these formulas vary significantly with the experiment setup. We meticulously identify influential factors and provide transparent, step-by-step instructions to estimate all constant terms in scaling-law formulas by training on models with only 1M~60M parameters. Using these estimated formulas, we showcase the capability to accurately predict various attributes for models with up to 33B parameters before their training, including (1) the minimum possible test loss; (2) the minimum required training steps and processed tokens to achieve a specific loss; (3) the critical batch size with an optimal time/computation trade-off at any loss value; and (4) the complete test loss trajectory with arbitrary batch size.
4/8/2024