Scaling up Multimodal Pre-training for Sign Language Understanding

0

Sign in to get full access
Overview
- This paper presents a novel multimodal pre-training approach to improve sign language understanding.
- The method leverages large-scale video data with pose information to learn a powerful visual representation.
- The pre-trained model can be fine-tuned on various sign language tasks and achieves state-of-the-art performance.
Plain English Explanation
The paper focuses on developing a new way to help computers better understand sign language. Sign language is a visual form of communication that uses hand, arm, and body movements to convey meaning. However, it can be challenging for computers to interpret these complex visual cues.
The researchers' approach is to [object Object] a neural network on a large dataset of sign language videos. This pre-training allows the model to learn a rich visual representation of sign language. The key insight is to use the [object Object] - the detailed position and movement of the body and hands - to guide the learning process.
Once the model is pre-trained, it can be [object Object] on specific sign language tasks, such as translation or recognition. This approach allows the model to leverage the general visual understanding gained during pre-training, while also adapting to the nuances of the target task.
The researchers show that their multi-modal pre-training method outperforms previous state-of-the-art approaches on several sign language benchmarks. This suggests that their technique is a promising step towards more [object Object] systems.
Technical Explanation
The paper presents a novel multimodal pre-training approach for sign language understanding. The key idea is to leverage large-scale video data with associated pose information to learn a powerful visual representation of sign language.
The pre-training process involves feeding the video frames and corresponding 3D pose data into a [object Object] (CNN) backbone. The CNN learns to extract visual features from the images, while the pose data provides additional supervisory signals to guide the learning of hand and body movements.
The pre-trained model is then fine-tuned on various sign language tasks, such as sign language translation or recognition. The researchers demonstrate that this approach outperforms previous state-of-the-art methods on several benchmark datasets, highlighting the effectiveness of their multimodal pre-training strategy.
Critical Analysis
The paper presents a compelling approach to improving sign language understanding through multimodal pre-training. However, the authors acknowledge several limitations and areas for future research:
-
Dataset Size and Diversity: The pre-training dataset, while large, may not capture the full diversity of sign languages and linguistic variations. Expanding the dataset to include more languages and regional dialects could further improve the model's generalization abilities.
-
Pose Estimation Accuracy: The performance of the pre-training approach is dependent on the quality of the pose estimation. Advancements in [object Object] could potentially lead to even better visual representations.
-
Interpretability and Explainability: As with many deep learning models, the internal workings of the pre-trained network may be difficult to interpret. Developing more [object Object] sign language understanding systems could be a valuable direction for future research.
Overall, the paper presents a promising approach to leveraging large-scale multimodal data for improved sign language understanding. The authors have clearly demonstrated the advantages of their method, while also highlighting important areas for further investigation and improvement.
Conclusion
This paper introduces a novel multimodal pre-training approach for sign language understanding. By leveraging large-scale video data with pose information, the researchers have developed a powerful visual representation that can be effectively fine-tuned for various sign language tasks.
The results show that this method outperforms previous state-of-the-art techniques, suggesting that it is a significant step towards more robust and universal sign language understanding systems. The insights gained from this work could also have broader implications for other domains that rely on complex visual inputs, such as human action recognition or video understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Scaling up Multimodal Pre-training for Sign Language Understanding
Wengang Zhou, Weichao Zhao, Hezhen Hu, Zecheng Li, Houqiang Li
Sign language serves as the primary meaning of communication for the deaf-mute community. Different from spoken language, it commonly conveys information by the collaboration of manual features, i.e., hand gestures and body movements, and non-manual features, i.e., facial expressions and mouth cues. To facilitate communication between the deaf-mute and hearing people, a series of sign language understanding (SLU) tasks have been studied in recent years, including isolated/continuous sign language recognition (ISLR/CSLR), gloss-free sign language translation (GF-SLT) and sign language retrieval (SL-RT). Sign language recognition and translation aims to understand the semantic meaning conveyed by sign languages from gloss-level and sentence-level, respectively. In contrast, SL-RT focuses on retrieving sign videos or corresponding texts from a closed-set under the query-by-example search paradigm. These tasks investigate sign language topics from diverse perspectives and raise challenges in learning effective representation of sign language videos. To advance the development of sign language understanding, exploring a generalized model that is applicable across various SLU tasks is a profound research direction.
Read more8/19/2024

0
Scaling Sign Language Translation
Biao Zhang, Garrett Tanzer, Orhan Firat
Sign language translation (SLT) addresses the problem of translating information from a sign language in video to a spoken language in text. Existing studies, while showing progress, are often limited to narrow domains and/or few sign languages and struggle with open-domain tasks. In this paper, we push forward the frontier of SLT by scaling pretraining data, model size, and number of translation directions. We perform large-scale SLT pretraining on different data including 1) noisy multilingual YouTube SLT data, 2) parallel text corpora, and 3) SLT data augmented by translating video captions to other languages with off-the-shelf machine translation models. We unify different pretraining tasks with task-specific prompts under the encoder-decoder architecture, and initialize the SLT model with pretrained (m/By)T5 models across model sizes. SLT pretraining results on How2Sign and FLEURS-ASL#0 (ASL to 42 spoken languages) demonstrate the significance of data/model scaling and cross-lingual cross-modal transfer, as well as the feasibility of zero-shot SLT. We finetune the pretrained SLT models on 5 downstream open-domain SLT benchmarks covering 5 sign languages. Experiments show substantial quality improvements over the vanilla baselines, surpassing the previous state-of-the-art (SOTA) by wide margins.
Read more7/17/2024
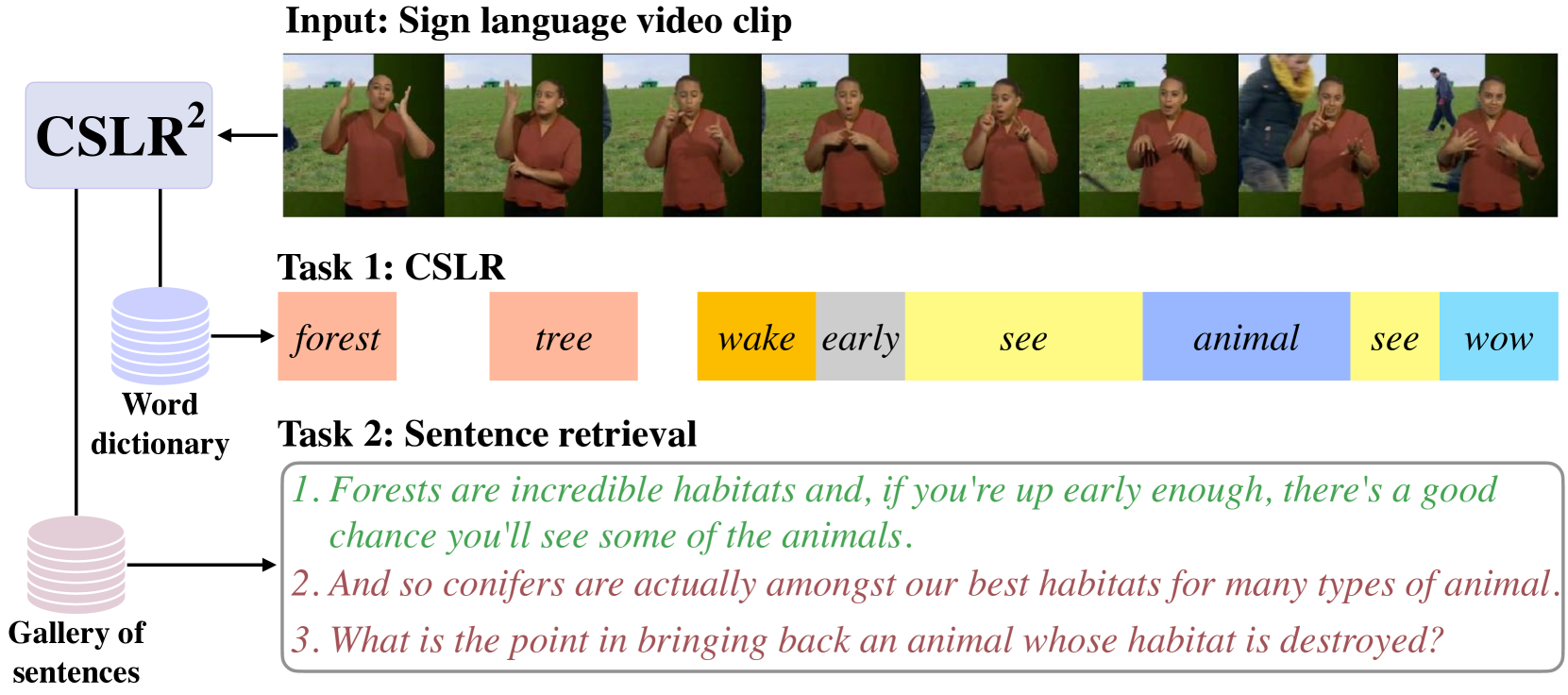
0
A Tale of Two Languages: Large-Vocabulary Continuous Sign Language Recognition from Spoken Language Supervision
Charles Raude, K R Prajwal, Liliane Momeni, Hannah Bull, Samuel Albanie, Andrew Zisserman, Gul Varol
In this work, our goals are two fold: large-vocabulary continuous sign language recognition (CSLR), and sign language retrieval. To this end, we introduce a multi-task Transformer model, CSLR2, that is able to ingest a signing sequence and output in a joint embedding space between signed language and spoken language text. To enable CSLR evaluation in the large-vocabulary setting, we introduce new dataset annotations that have been manually collected. These provide continuous sign-level annotations for six hours of test videos, and will be made publicly available. We demonstrate that by a careful choice of loss functions, training the model for both the CSLR and retrieval tasks is mutually beneficial in terms of performance -- retrieval improves CSLR performance by providing context, while CSLR improves retrieval with more fine-grained supervision. We further show the benefits of leveraging weak and noisy supervision from large-vocabulary datasets such as BOBSL, namely sign-level pseudo-labels, and English subtitles. Our model significantly outperforms the previous state of the art on both tasks.
Read more5/17/2024
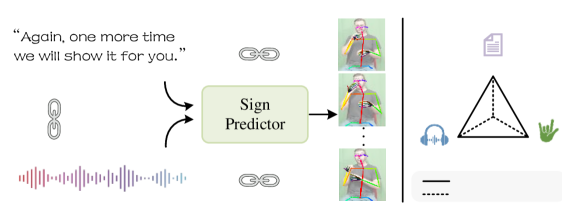
0
MS2SL: Multimodal Spoken Data-Driven Continuous Sign Language Production
Jian Ma, Wenguan Wang, Yi Yang, Feng Zheng
Sign language understanding has made significant strides; however, there is still no viable solution for generating sign sequences directly from entire spoken content, e.g., text or speech. In this paper, we propose a unified framework for continuous sign language production, easing communication between sign and non-sign language users. In particular, a sequence diffusion model, utilizing embeddings extracted from text or speech, is crafted to generate sign predictions step by step. Moreover, by creating a joint embedding space for text, audio, and sign, we bind these modalities and leverage the semantic consistency among them to provide informative feedback for the model training. This embedding-consistency learning strategy minimizes the reliance on sign triplets and ensures continuous model refinement, even with a missing audio modality. Experiments on How2Sign and PHOENIX14T datasets demonstrate that our model achieves competitive performance in sign language production.
Read more7/19/2024