SceneTracker: Long-term Scene Flow Estimation Network
2403.19924
0
0
Abstract
Considering the complementarity of scene flow estimation in the spatial domain's focusing capability and 3D object tracking in the temporal domain's coherence, this study aims to address a comprehensive new task that can simultaneously capture fine-grained and long-term 3D motion in an online manner: long-term scene flow estimation (LSFE). We introduce SceneTracker, a novel learning-based LSFE network that adopts an iterative approach to approximate the optimal trajectory. Besides, it dynamically indexes and constructs appearance and depth correlation features simultaneously and employs the Transformer to explore and utilize long-range connections within and between trajectories. With detailed experiments, SceneTracker shows superior capabilities in handling 3D spatial occlusion and depth noise interference, highly tailored to the LSFE task's needs. Finally, we build the first real-world evaluation dataset, LSFDriving, further substantiating SceneTracker's commendable generalization capacity. The code and data for SceneTracker is available at https://github.com/wwsource/SceneTracker.
Create account to get full access
Introduction
The paper introduces a new task called long-term scene flow estimation (LSFE), which aims to capture fine-grained and long-term 3D motion of objects in a scene. Existing methods like scene flow estimation (SFE) and 3D object tracking (3D OT) partially address this issue but have limitations in capturing long-term 3D trajectories or fine-grained deformations within objects.
The proposed method, SceneTracker, is the first LSFE method that takes an RGB-D video and initial 3D coordinates of a target as input and produces the target's 3D trajectory across the frames. SceneTracker adopts an iterative approach to approximate the optimal trajectory and overcome large displacements between frames. It dynamically constructs appearance and depth correlation features to enhance localization of the target's 3D position. The Transformer architecture is employed to explore long-range connections within and between trajectories, improving long-term estimation accuracy.
Compared to baseline methods, SceneTracker effectively addresses 3D occlusion and depth noise, achieving significant improvements in 3D error reduction. The key contributions are introducing the LSFE task, proposing the SceneTracker method for effective per-point 3D trajectory estimation within RGB-D videos, and validating the approach through qualitative and quantitative experiments.
Related Works
The paper discusses several tasks related to estimating motion and tracking points in videos and 3D scenes:
Optical Flow Estimation aims to estimate pixel-wise 2D motion between consecutive video frames. Methods like FlowNet, PWC-Net, GMFlow, and RAFT have tackled this using deep neural networks and techniques like iterative refinement and global matching.
Scene Flow Estimation estimates 3D motion and depth for each pixel across video frames. Approaches include operating directly on point clouds (FlowNet3D), coarse-to-fine refinement (CamLiFlow), and using optical expansion (OpticalExp). Handling occlusions is a key challenge addressed by methods like RigidMask and RAFT-3D.
Tracking Any Point focuses on tracking the global motion trajectory of points over multiple frames. Methods like PIPs, TAP-Net, MFT, and Cotracker use techniques like cost volumes, iterative inference, and modeling uncertainty.
The paper also discusses reconstruction-based offline methods like 3D-GS, Dynamic 3D Gaussians, and 4D-GS that model dynamic 3D scenes using Gaussian representations learned from multi-view videos. In contrast, the Live Scene Flow Estimation (LSFE) task tackled in this paper focuses on challenging scenarios with limited observations and real-time constraints.
Proposed Method
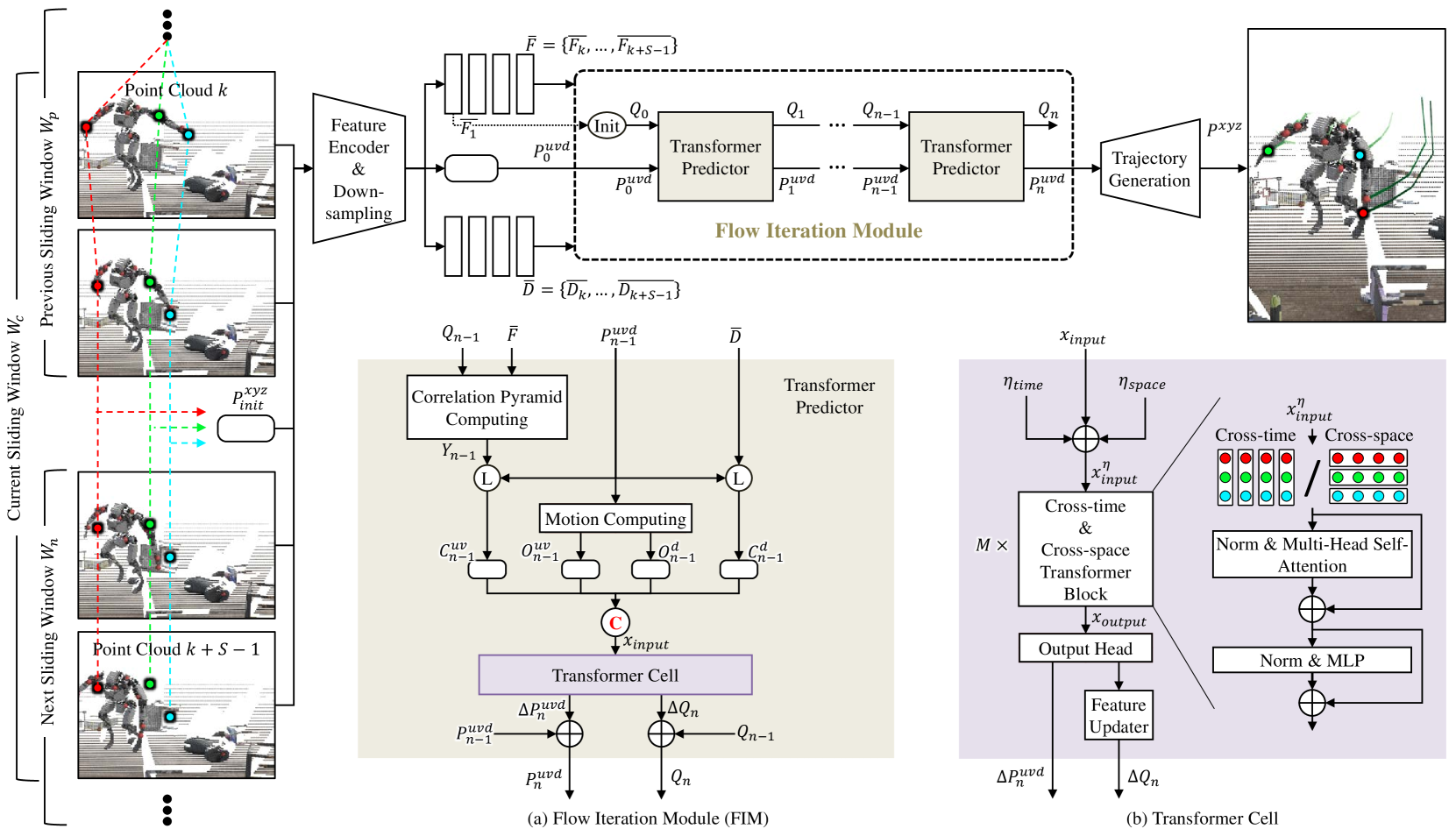
The paper describes an approach called SceneTracker for tracking 3D points throughout a 3D video sequence. The overall architecture involves dividing the video into overlapping sliding windows and iteratively updating the trajectories and template features for a set of query points within each window.
Key components include:
-
Feature Encoder and Downsampling: Extracts multi-scale image features and downsampled depth maps from the input RGB frames and depth maps.
-
Trajectory Initialization: Initializes the 3D trajectories for the query points in each sliding window based on the previous window's estimates.
-
Flow Iteration Module: Iteratively updates the template features and 3D trajectories by correlating them with the image features and depth maps using a transformer-based architecture. It constructs correlation features and motion features to model interactions.
-
Transformer Cell Network: Uses alternating cross-time and cross-space transformer blocks along with sinusoidal positional encodings to explore long-range dependencies within and between trajectories. Predicts residuals to update the trajectories and features.
-
Training: Supervises the network using ground truth 3D trajectories, computing a 3D loss that measures errors in predicted positions and inverse depths.
The method aims to handle large inter-frame motions by iteratively refining the trajectories within each sliding window in a coarse-to-fine manner, leveraging transformer architectures to capture long-range spatio-temporal dependencies.
Experiments
The paper describes the datasets, experimental setup, evaluation metrics, implementation details, and training processes used for the proposed long sequence flow estimation (LSFE) method called SceneTracker.
Datasets:
- LSFE lacks a dedicated dataset, so an augmented dataset called LSFOdyssey is constructed based on the PointOdyssey dataset for trajectory annotation prediction (TAP).
- LSFOdyssey has 127,437 training samples and 90 testing samples, with each sample containing a 24/40-frame 3D video and trajectories of 256 non-occluded query points.
Evaluation Metrics:
- 2D metrics: average 2D position accuracy, median 2D trajectory error, 2D survival rate.
- 3D metrics: percentages of points within distance thresholds, median/end-point 3D trajectory errors, 3D survival rate.
Implementation Details:
- PyTorch implementation, AdamW optimizer, one-cycle learning rate scheduler.
- Specific hyperparameter values for the network architecture.
Training Process:
- Odyssey process trains the model from scratch on LSFOdyssey with a 2e-4 learning rate for 200K steps.
The paper then visualizes SceneTracker's results on the test set and compares it against scene flow (SF) and TAP baselines, showing significant performance improvements. Ablation studies analyze the effects of the inference window size and number of updates in the iterative update module.
Conclusion
The paper proposes a new task called long-term scene flow estimation (LSFE) to better capture fine-grained and long-term 3D motion. To effectively tackle this task, the authors introduce a novel approach named SceneTracker. Experiments demonstrate that SceneTracker excels at handling 3D spatial occlusion and depth noise interference, making it well-suited for the LSFE task's requirements. The work proves the feasibility of simultaneously capturing fine-grained and long-term 3D motion, positioning LSFE as a promising direction for future research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🚀
Learning Optical Flow and Scene Flow with Bidirectional Camera-LiDAR Fusion
Haisong Liu, Tao Lu, Yihui Xu, Jia Liu, Limin Wang
0
0
In this paper, we study the problem of jointly estimating the optical flow and scene flow from synchronized 2D and 3D data. Previous methods either employ a complex pipeline that splits the joint task into independent stages, or fuse 2D and 3D information in an ``early-fusion'' or ``late-fusion'' manner. Such one-size-fits-all approaches suffer from a dilemma of failing to fully utilize the characteristic of each modality or to maximize the inter-modality complementarity. To address the problem, we propose a novel end-to-end framework, which consists of 2D and 3D branches with multiple bidirectional fusion connections between them in specific layers. Different from previous work, we apply a point-based 3D branch to extract the LiDAR features, as it preserves the geometric structure of point clouds. To fuse dense image features and sparse point features, we propose a learnable operator named bidirectional camera-LiDAR fusion module (Bi-CLFM). We instantiate two types of the bidirectional fusion pipeline, one based on the pyramidal coarse-to-fine architecture (dubbed CamLiPWC), and the other one based on the recurrent all-pairs field transforms (dubbed CamLiRAFT). On FlyingThings3D, both CamLiPWC and CamLiRAFT surpass all existing methods and achieve up to a 47.9% reduction in 3D end-point-error from the best published result. Our best-performing model, CamLiRAFT, achieves an error of 4.26% on the KITTI Scene Flow benchmark, ranking 1st among all submissions with much fewer parameters. Besides, our methods have strong generalization performance and the ability to handle non-rigid motion. Code is available at https://github.com/MCG-NJU/CamLiFlow.
4/9/2024
DifFlow3D: Toward Robust Uncertainty-Aware Scene Flow Estimation with Diffusion Model
Jiuming Liu, Guangming Wang, Weicai Ye, Chaokang Jiang, Jinru Han, Zhe Liu, Guofeng Zhang, Dalong Du, Hesheng Wang
0
0
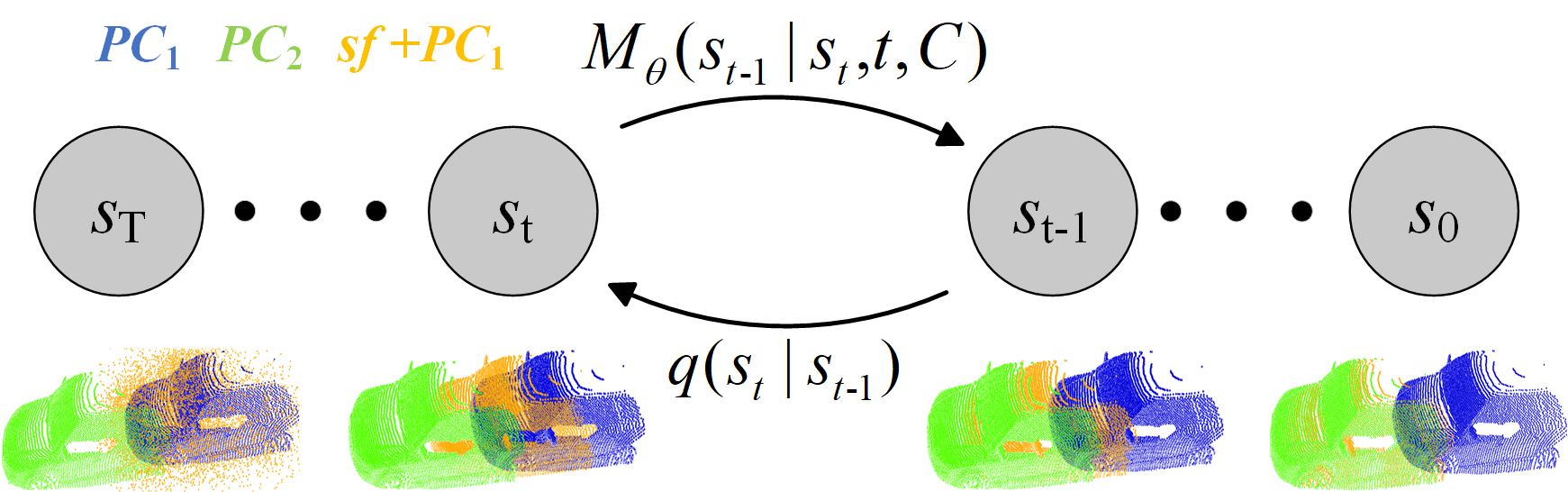
Scene flow estimation, which aims to predict per-point 3D displacements of dynamic scenes, is a fundamental task in the computer vision field. However, previous works commonly suffer from unreliable correlation caused by locally constrained searching ranges, and struggle with accumulated inaccuracy arising from the coarse-to-fine structure. To alleviate these problems, we propose a novel uncertainty-aware scene flow estimation network (DifFlow3D) with the diffusion probabilistic model. Iterative diffusion-based refinement is designed to enhance the correlation robustness and resilience to challenging cases, e.g. dynamics, noisy inputs, repetitive patterns, etc. To restrain the generation diversity, three key flow-related features are leveraged as conditions in our diffusion model. Furthermore, we also develop an uncertainty estimation module within diffusion to evaluate the reliability of estimated scene flow. Our DifFlow3D achieves state-of-the-art performance, with 24.0% and 29.1% EPE3D reduction respectively on FlyingThings3D and KITTI 2015 datasets. Notably, our method achieves an unprecedented millimeter-level accuracy (0.0078m in EPE3D) on the KITTI dataset. Additionally, our diffusion-based refinement paradigm can be readily integrated as a plug-and-play module into existing scene flow networks, significantly increasing their estimation accuracy. Codes are released at https://github.com/IRMVLab/DifFlow3D.
5/13/2024
Long-term Frame-Event Visual Tracking: Benchmark Dataset and Baseline
Xiao Wang, Ju Huang, Shiao Wang, Chuanming Tang, Bo Jiang, Yonghong Tian, Jin Tang, Bin Luo
0
0
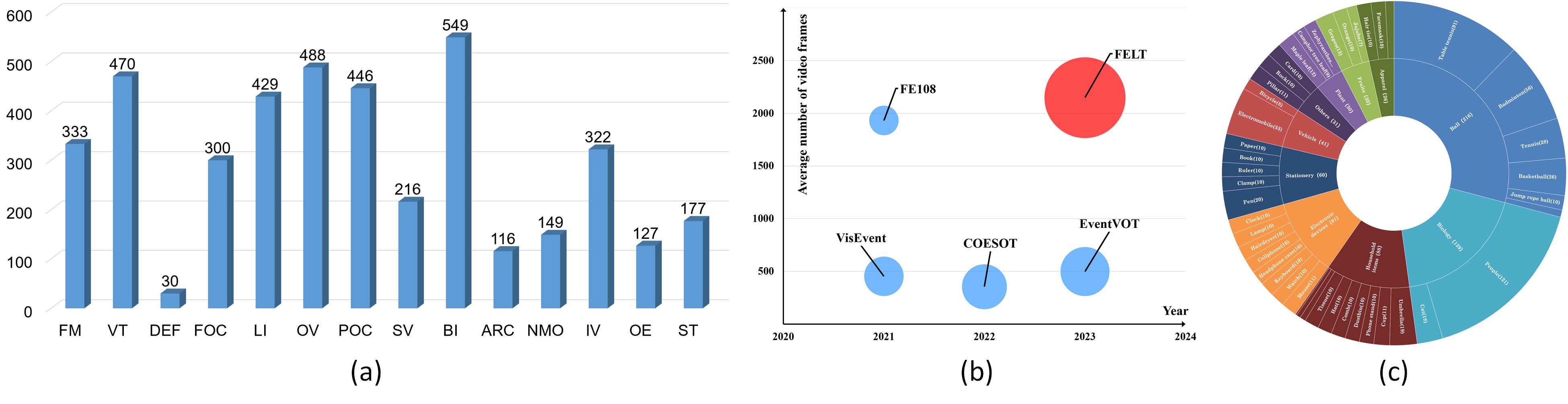
Current event-/frame-event based trackers undergo evaluation on short-term tracking datasets, however, the tracking of real-world scenarios involves long-term tracking, and the performance of existing tracking algorithms in these scenarios remains unclear. In this paper, we first propose a new long-term and large-scale frame-event single object tracking dataset, termed FELT. It contains 742 videos and 1,594,474 RGB frames and event stream pairs and has become the largest frame-event tracking dataset to date. We re-train and evaluate 15 baseline trackers on our dataset for future works to compare. More importantly, we find that the RGB frames and event streams are naturally incomplete due to the influence of challenging factors and spatially sparse event flow. In response to this, we propose a novel associative memory Transformer network as a unified backbone by introducing modern Hopfield layers into multi-head self-attention blocks to fuse both RGB and event data. Extensive experiments on RGB-Event (FELT), RGB-Thermal (RGBT234, LasHeR), and RGB-Depth (DepthTrack) datasets fully validated the effectiveness of our model. The dataset and source code can be found at url{https://github.com/Event-AHU/FELT_SOT_Benchmark}.
4/4/2024
Semantic Flow: Learning Semantic Field of Dynamic Scenes from Monocular Videos
Fengrui Tian, Yueqi Duan, Angtian Wang, Jianfei Guo, Shaoyi Du
0
0
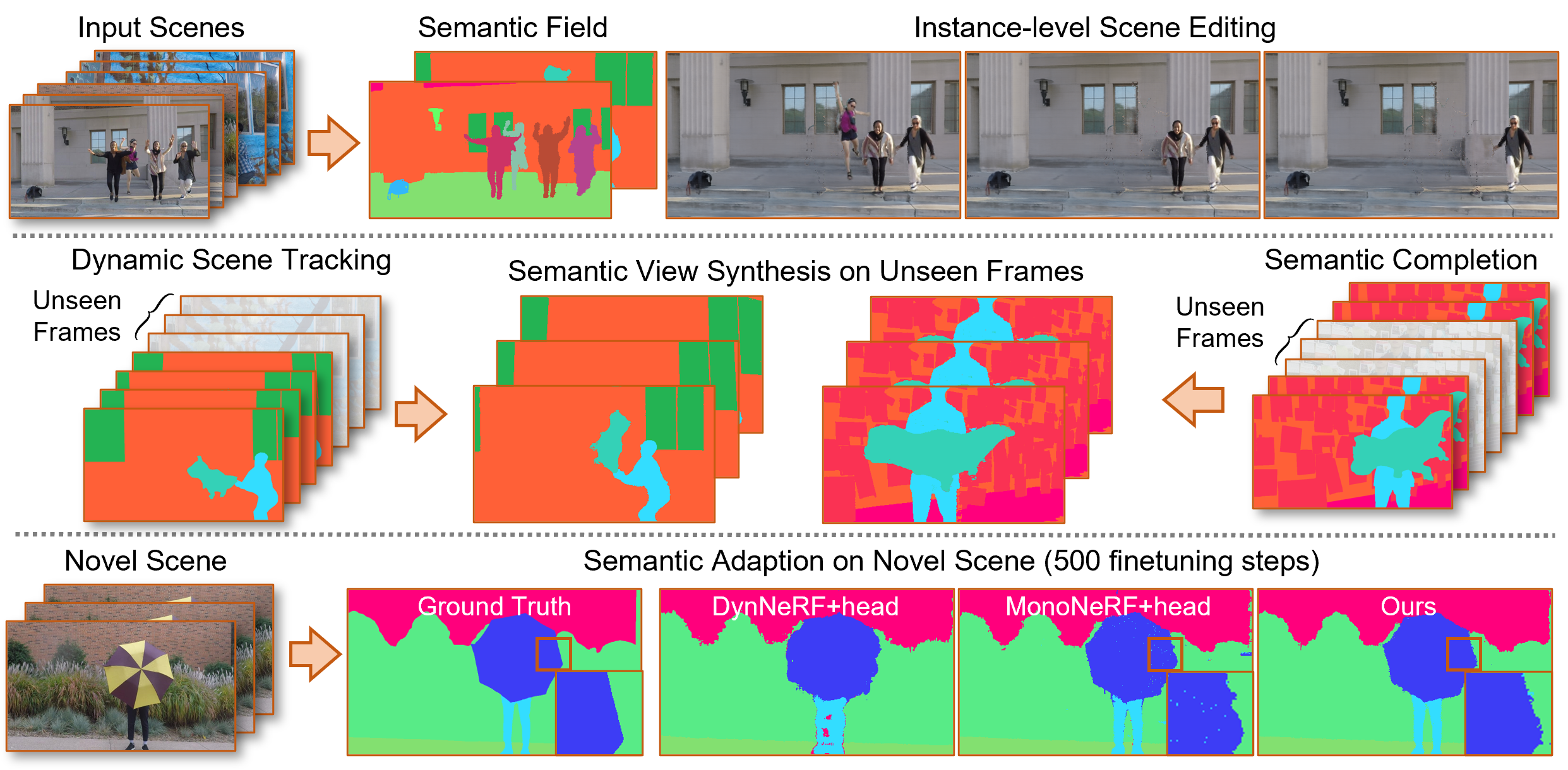
In this work, we pioneer Semantic Flow, a neural semantic representation of dynamic scenes from monocular videos. In contrast to previous NeRF methods that reconstruct dynamic scenes from the colors and volume densities of individual points, Semantic Flow learns semantics from continuous flows that contain rich 3D motion information. As there is 2D-to-3D ambiguity problem in the viewing direction when extracting 3D flow features from 2D video frames, we consider the volume densities as opacity priors that describe the contributions of flow features to the semantics on the frames. More specifically, we first learn a flow network to predict flows in the dynamic scene, and propose a flow feature aggregation module to extract flow features from video frames. Then, we propose a flow attention module to extract motion information from flow features, which is followed by a semantic network to output semantic logits of flows. We integrate the logits with volume densities in the viewing direction to supervise the flow features with semantic labels on video frames. Experimental results show that our model is able to learn from multiple dynamic scenes and supports a series of new tasks such as instance-level scene editing, semantic completions, dynamic scene tracking and semantic adaption on novel scenes. Codes are available at https://github.com/tianfr/Semantic-Flow/.
4/9/2024