DifFlow3D: Toward Robust Uncertainty-Aware Scene Flow Estimation with Diffusion Model
2311.17456
0
0
Abstract
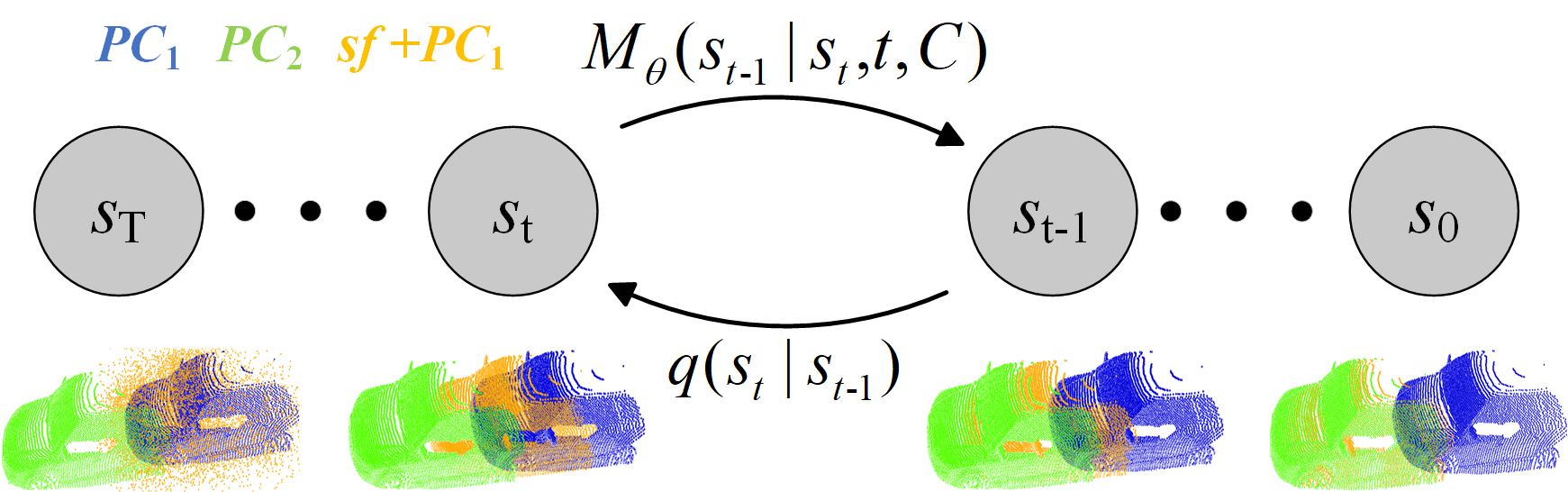
Scene flow estimation, which aims to predict per-point 3D displacements of dynamic scenes, is a fundamental task in the computer vision field. However, previous works commonly suffer from unreliable correlation caused by locally constrained searching ranges, and struggle with accumulated inaccuracy arising from the coarse-to-fine structure. To alleviate these problems, we propose a novel uncertainty-aware scene flow estimation network (DifFlow3D) with the diffusion probabilistic model. Iterative diffusion-based refinement is designed to enhance the correlation robustness and resilience to challenging cases, e.g. dynamics, noisy inputs, repetitive patterns, etc. To restrain the generation diversity, three key flow-related features are leveraged as conditions in our diffusion model. Furthermore, we also develop an uncertainty estimation module within diffusion to evaluate the reliability of estimated scene flow. Our DifFlow3D achieves state-of-the-art performance, with 24.0% and 29.1% EPE3D reduction respectively on FlyingThings3D and KITTI 2015 datasets. Notably, our method achieves an unprecedented millimeter-level accuracy (0.0078m in EPE3D) on the KITTI dataset. Additionally, our diffusion-based refinement paradigm can be readily integrated as a plug-and-play module into existing scene flow networks, significantly increasing their estimation accuracy. Codes are released at https://github.com/IRMVLab/DifFlow3D.
Create account to get full access
Overview
- This paper introduces DifFlow3D, a method for robust and uncertainty-aware scene flow estimation.
- The key innovations include an iterative diffusion-based refinement process and a tailored architecture to handle the unique challenges of scene flow estimation.
- The proposed approach demonstrates improved robustness and accuracy compared to existing methods, particularly in handling challenging scenarios with occlusions and motion discontinuities.
Plain English Explanation
Scene flow estimation is the process of determining the 3D motion of objects in a video sequence. This information is crucial for applications like autonomous driving, robotics, and augmented reality. However, existing methods struggle with certain challenging scenarios, such as when objects are partially occluded or when there are abrupt changes in motion.
The researchers behind DifFlow3D have developed a new approach that aims to address these limitations. At the core of their method is an iterative refinement process inspired by diffusion models, which are a type of machine learning model that can generate realistic images by gradually transforming noise into structured data.
In the case of scene flow estimation, the diffusion-based refinement allows DifFlow3D to gradually improve its predictions, taking into account both the initial estimates and the underlying uncertainty in the data. This helps the model handle occlusions and motion discontinuities more effectively than previous techniques.
Additionally, the researchers have designed a tailored neural network architecture for DifFlow3D that is well-suited for the specific challenges of scene flow estimation. This architecture incorporates key insights from related work on dynamic 3D content generation, accelerated diffusion models, and multi-sensor fusion.
Technical Explanation
The core idea behind DifFlow3D is to leverage the strengths of diffusion models to address the unique challenges of scene flow estimation. Diffusion models have shown promise in generating high-quality images by gradually transforming noise into structured data, and the researchers hypothesized that a similar approach could be beneficial for scene flow estimation.
The DifFlow3D architecture consists of several key components:
- An initial scene flow estimation module that provides an initial set of predictions.
- An iterative diffusion-based refinement process that gradually improves the scene flow estimates by considering both the initial predictions and the underlying uncertainty in the data.
- A tailored neural network design that is optimized for the specific requirements of scene flow estimation, drawing insights from related work in areas like dynamic 3D content generation and multi-sensor fusion.
The researchers evaluated DifFlow3D on several standard benchmarks for scene flow estimation and demonstrated significant improvements in robustness and accuracy compared to existing methods, particularly in challenging scenarios involving occlusions and motion discontinuities.
Critical Analysis
The researchers have made a compelling case for the benefits of incorporating diffusion-based refinement into scene flow estimation. The iterative nature of the process and the way it handles uncertainty seem well-suited to the unique challenges of this task.
That said, the paper does not provide a detailed analysis of the computational or memory requirements of the DifFlow3D architecture. As scene flow estimation is often a time-critical application, the efficiency of the approach is an important consideration that could be explored further.
Additionally, while the results on benchmark datasets are promising, it would be valuable to see how DifFlow3D performs in real-world scenarios, such as in autonomous driving or robotics applications. Evaluating the method's robustness to sensor noise, varying environmental conditions, and real-time constraints would help demonstrate its practical utility.
Conclusion
The DifFlow3D method represents a promising advancement in the field of scene flow estimation. By leveraging diffusion-based refinement and a tailored neural network architecture, the researchers have developed an approach that demonstrates improved robustness and accuracy, particularly in challenging scenarios.
If the efficiency and real-world performance of DifFlow3D can be further validated, it could have significant implications for applications that rely on accurate and reliable 3D motion estimation, such as autonomous navigation, robotic manipulation, and immersive augmented reality experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Mixed Diffusion for 3D Indoor Scene Synthesis
Siyi Hu, Diego Martin Arroyo, Stephanie Debats, Fabian Manhardt, Luca Carlone, Federico Tombari
0
0
Realistic conditional 3D scene synthesis significantly enhances and accelerates the creation of virtual environments, which can also provide extensive training data for computer vision and robotics research among other applications. Diffusion models have shown great performance in related applications, e.g., making precise arrangements of unordered sets. However, these models have not been fully explored in floor-conditioned scene synthesis problems. We present MiDiffusion, a novel mixed discrete-continuous diffusion model architecture, designed to synthesize plausible 3D indoor scenes from given room types, floor plans, and potentially pre-existing objects. We represent a scene layout by a 2D floor plan and a set of objects, each defined by its category, location, size, and orientation. Our approach uniquely implements structured corruption across the mixed discrete semantic and continuous geometric domains, resulting in a better conditioned problem for the reverse denoising step. We evaluate our approach on the 3D-FRONT dataset. Our experimental results demonstrate that MiDiffusion substantially outperforms state-of-the-art autoregressive and diffusion models in floor-conditioned 3D scene synthesis. In addition, our models can handle partial object constraints via a corruption-and-masking strategy without task specific training. We show MiDiffusion maintains clear advantages over existing approaches in scene completion and furniture arrangement experiments.
6/3/2024

MVDiff: Scalable and Flexible Multi-View Diffusion for 3D Object Reconstruction from Single-View
Emmanuelle Bourigault, Pauline Bourigault
0
0
Generating consistent multiple views for 3D reconstruction tasks is still a challenge to existing image-to-3D diffusion models. Generally, incorporating 3D representations into diffusion model decrease the model's speed as well as generalizability and quality. This paper proposes a general framework to generate consistent multi-view images from single image or leveraging scene representation transformer and view-conditioned diffusion model. In the model, we introduce epipolar geometry constraints and multi-view attention to enforce 3D consistency. From as few as one image input, our model is able to generate 3D meshes surpassing baselines methods in evaluation metrics, including PSNR, SSIM and LPIPS.
6/14/2024

Diffusion$^2$: Dynamic 3D Content Generation via Score Composition of Orthogonal Diffusion Models
Zeyu Yang, Zijie Pan, Chun Gu, Li Zhang
0
0
Recent advancements in 3D generation are predominantly propelled by improvements in 3D-aware image diffusion models which are pretrained on Internet-scale image data and fine-tuned on massive 3D data, offering the capability of producing highly consistent multi-view images. However, due to the scarcity of synchronized multi-view video data, it is impractical to adapt this paradigm to 4D generation directly. Despite that, the available video and 3D data are adequate for training video and multi-view diffusion models separately that can provide satisfactory dynamic and geometric priors respectively. To take advantage of both, this paper present Diffusion$^2$, a novel framework for dynamic 3D content creation that reconciles the knowledge about geometric consistency and temporal smoothness from these models to directly sample dense multi-view multi-frame images which can be employed to optimize continuous 4D representation. Specifically, we design a simple yet effective denoising strategy via score composition of pretrained video and multi-view diffusion models based on the probability structure of the target image array. Owing to the high parallelism of the proposed image generation process and the efficiency of the modern 4D reconstruction pipeline, our framework can generate 4D content within few minutes. Additionally, our method circumvents the reliance on 4D data, thereby having the potential to benefit from the scaling of the foundation video and multi-view diffusion models. Extensive experiments demonstrate the efficacy of our proposed framework and its ability to flexibly handle various types of prompts.
5/24/2024

4Diffusion: Multi-view Video Diffusion Model for 4D Generation
Haiyu Zhang, Xinyuan Chen, Yaohui Wang, Xihui Liu, Yunhong Wang, Yu Qiao
0
0
Current 4D generation methods have achieved noteworthy efficacy with the aid of advanced diffusion generative models. However, these methods lack multi-view spatial-temporal modeling and encounter challenges in integrating diverse prior knowledge from multiple diffusion models, resulting in inconsistent temporal appearance and flickers. In this paper, we propose a novel 4D generation pipeline, namely 4Diffusion aimed at generating spatial-temporally consistent 4D content from a monocular video. We first design a unified diffusion model tailored for multi-view video generation by incorporating a learnable motion module into a frozen 3D-aware diffusion model to capture multi-view spatial-temporal correlations. After training on a curated dataset, our diffusion model acquires reasonable temporal consistency and inherently preserves the generalizability and spatial consistency of the 3D-aware diffusion model. Subsequently, we propose 4D-aware Score Distillation Sampling loss, which is based on our multi-view video diffusion model, to optimize 4D representation parameterized by dynamic NeRF. This aims to eliminate discrepancies arising from multiple diffusion models, allowing for generating spatial-temporally consistent 4D content. Moreover, we devise an anchor loss to enhance the appearance details and facilitate the learning of dynamic NeRF. Extensive qualitative and quantitative experiments demonstrate that our method achieves superior performance compared to previous methods.
6/3/2024