Semantic Flow: Learning Semantic Field of Dynamic Scenes from Monocular Videos
2404.05163
0
0
Abstract
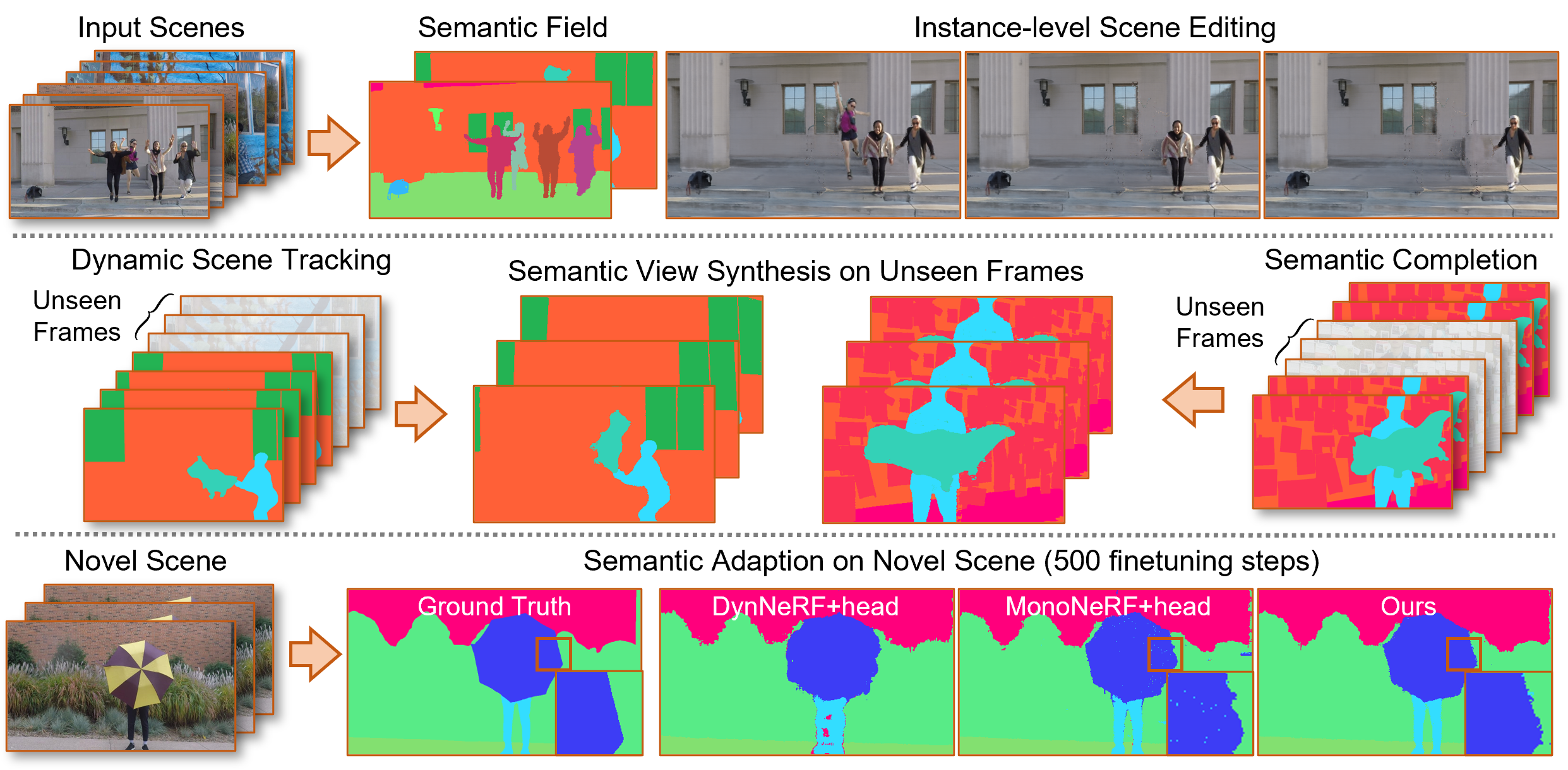
In this work, we pioneer Semantic Flow, a neural semantic representation of dynamic scenes from monocular videos. In contrast to previous NeRF methods that reconstruct dynamic scenes from the colors and volume densities of individual points, Semantic Flow learns semantics from continuous flows that contain rich 3D motion information. As there is 2D-to-3D ambiguity problem in the viewing direction when extracting 3D flow features from 2D video frames, we consider the volume densities as opacity priors that describe the contributions of flow features to the semantics on the frames. More specifically, we first learn a flow network to predict flows in the dynamic scene, and propose a flow feature aggregation module to extract flow features from video frames. Then, we propose a flow attention module to extract motion information from flow features, which is followed by a semantic network to output semantic logits of flows. We integrate the logits with volume densities in the viewing direction to supervise the flow features with semantic labels on video frames. Experimental results show that our model is able to learn from multiple dynamic scenes and supports a series of new tasks such as instance-level scene editing, semantic completions, dynamic scene tracking and semantic adaption on novel scenes. Codes are available at https://github.com/tianfr/Semantic-Flow/.
Create account to get full access
Overview
- This paper presents a novel approach called "Semantic Flow" for learning semantic fields of dynamic scenes from monocular videos.
- The proposed method aims to capture the semantic understanding of a scene, including the relationships between objects and their motion, by leveraging video data.
- The authors demonstrate the effectiveness of their approach on various downstream tasks, such as scene flow estimation, novel view synthesis, and long-term scene understanding.
Plain English Explanation
The paper introduces a new technique called "Semantic Flow" that can analyze videos to understand the relationships between objects and how they move in a scene. Instead of just focusing on the raw visual information, the method tries to capture the semantic meaning behind what's happening.
For example, if you had a video of a person walking across a room, the Semantic Flow approach would not only track the person's movement, but also understand that the person is an agent that is moving independently, while the background environment is a static scene. This deeper understanding of the scene could then be used to help with tasks like predicting future movement, generating new views of the scene, or maintaining long-term knowledge of what's happening.
The key innovation is the way the method learns to extract this semantic information directly from the video data, without requiring additional annotations or external knowledge. By learning the relationships between objects and their motion, the Semantic Flow approach aims to provide a more holistic and meaningful representation of dynamic scenes compared to traditional computer vision techniques.
Technical Explanation
The core of the Semantic Flow approach is a neural network architecture that takes a monocular video as input and produces a set of learned 'semantic fields' as output. These semantic fields capture the relationships between different semantic entities (e.g. objects, agents, background) and their motion in the scene.
The network consists of several key components:
- A video encoder that extracts visual features from the input frames.
- A 'semantic segmentation' module that identifies the different semantic entities present in the scene.
- A 'semantic flow' module that predicts how these semantic entities move and interact over time.
- A 'scene graph' module that models the high-level relationships between the semantic entities.
By jointly training these components end-to-end on video data, the network learns to build a rich, structured representation of the dynamic scene that goes beyond just tracking low-level visual features. The authors demonstrate how this semantic understanding can be leveraged for tasks like scene flow estimation, novel view synthesis, and long-term scene understanding.
Critical Analysis
The Semantic Flow approach represents an interesting step forward in video understanding, as it moves beyond just tracking visual motion to also capturing the semantic relationships between objects and agents in a scene. This richer representation could lead to more robust and capable computer vision systems, with applications in areas like autonomous driving, robotics, and augmented reality.
However, the paper also raises some questions and limitations that warrant further investigation. For example, the performance of the method is demonstrated on relatively simple indoor scenes, and it's unclear how well it would scale to more complex, real-world environments. Additionally, the paper does not discuss how the semantic understanding could be made more interpretable or explainable to human users.
Another potential concern is the reliance on monocular video data, which can be challenging to acquire and may limit the accuracy of the learned representations compared to methods that leverage additional sensor modalities, such as depth or stereo information. Incorporating such complementary data sources could be an interesting direction for future research.
Overall, the Semantic Flow approach is a promising step forward in video understanding, but additional work is needed to fully realize its potential and address its current limitations.
Conclusion
The Semantic Flow paper presents a novel approach for learning semantic representations of dynamic scenes from monocular video data. By capturing the relationships between objects, agents, and their motion, the method aims to provide a more holistic and meaningful understanding of the scene compared to traditional computer vision techniques.
The authors demonstrate the effectiveness of their approach on several downstream tasks, showcasing the potential of this semantic understanding for applications in areas like autonomous navigation, robotics, and augmented reality. While the current implementation has some limitations, the Semantic Flow concept represents an exciting direction for advancing video-based scene understanding and paves the way for future research in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

SemFlow: Binding Semantic Segmentation and Image Synthesis via Rectified Flow
Chaoyang Wang, Xiangtai Li, Lu Qi, Henghui Ding, Yunhai Tong, Ming-Hsuan Yang
0
0
Semantic segmentation and semantic image synthesis are two representative tasks in visual perception and generation. While existing methods consider them as two distinct tasks, we propose a unified diffusion-based framework (SemFlow) and model them as a pair of reverse problems. Specifically, motivated by rectified flow theory, we train an ordinary differential equation (ODE) model to transport between the distributions of real images and semantic masks. As the training object is symmetric, samples belonging to the two distributions, images and semantic masks, can be effortlessly transferred reversibly. For semantic segmentation, our approach solves the contradiction between the randomness of diffusion outputs and the uniqueness of segmentation results. For image synthesis, we propose a finite perturbation approach to enhance the diversity of generated results without changing the semantic categories. Experiments show that our SemFlow achieves competitive results on semantic segmentation and semantic image synthesis tasks. We hope this simple framework will motivate people to rethink the unification of low-level and high-level vision. Project page: https://github.com/wang-chaoyang/SemFlow.
5/31/2024

SSFlowNet: Semi-supervised Scene Flow Estimation On Point Clouds With Pseudo Label
Jingze Chen, Junfeng Yao, Qiqin Lin, Rongzhou Zhou, Lei Li
0
0
In the domain of supervised scene flow estimation, the process of manual labeling is both time-intensive and financially demanding. This paper introduces SSFlowNet, a semi-supervised approach for scene flow estimation, that utilizes a blend of labeled and unlabeled data, optimizing the balance between the cost of labeling and the precision of model training. SSFlowNet stands out through its innovative use of pseudo-labels, mainly reducing the dependency on extensively labeled datasets while maintaining high model accuracy. The core of our model is its emphasis on the intricate geometric structures of point clouds, both locally and globally, coupled with a novel spatial memory feature. This feature is adept at learning the geometric relationships between points over sequential time frames. By identifying similarities between labeled and unlabeled points, SSFlowNet dynamically constructs a correlation matrix to evaluate scene flow dependencies at individual point level. Furthermore, the integration of a flow consistency module within SSFlowNet enhances its capability to consistently estimate flow, an essential aspect for analyzing dynamic scenes. Empirical results demonstrate that SSFlowNet surpasses existing methods in pseudo-label generation and shows adaptability across varying data volumes. Moreover, our semi-supervised training technique yields promising outcomes even with different smaller ratio labeled data, marking a substantial advancement in the field of scene flow estimation.
6/5/2024
🔮
SemanticFormer: Holistic and Semantic Traffic Scene Representation for Trajectory Prediction using Knowledge Graphs
Zhigang Sun, Zixu Wang, Lavdim Halilaj, Juergen Luettin
0
0
Trajectory prediction in autonomous driving relies on accurate representation of all relevant contexts of the driving scene, including traffic participants, road topology, traffic signs, as well as their semantic relations to each other. Despite increased attention to this issue, most approaches in trajectory prediction do not consider all of these factors sufficiently. We present SemanticFormer, an approach for predicting multimodal trajectories by reasoning over a semantic traffic scene graph using a hybrid approach. It utilizes high-level information in the form of meta-paths, i.e. trajectories on which an agent is allowed to drive from a knowledge graph which is then processed by a novel pipeline based on multiple attention mechanisms to predict accurate trajectories. SemanticFormer comprises a hierarchical heterogeneous graph encoder to capture spatio-temporal and relational information across agents as well as between agents and road elements. Further, it includes a predictor to fuse different encodings and decode trajectories with probabilities. Finally, a refinement module assesses permitted meta-paths of trajectories and speed profiles to obtain final predicted trajectories. Evaluation of the nuScenes benchmark demonstrates improved performance compared to several SOTA methods. In addition, we demonstrate that our knowledge graph can be easily added to two graph-based existing SOTA methods, namely VectorNet and Laformer, replacing their original homogeneous graphs. The evaluation results suggest that by adding our knowledge graph the performance of the original methods is enhanced by 5% and 4%, respectively.
5/28/2024
DGD: Dynamic 3D Gaussians Distillation
Isaac Labe, Noam Issachar, Itai Lang, Sagie Benaim
0
0
We tackle the task of learning dynamic 3D semantic radiance fields given a single monocular video as input. Our learned semantic radiance field captures per-point semantics as well as color and geometric properties for a dynamic 3D scene, enabling the generation of novel views and their corresponding semantics. This enables the segmentation and tracking of a diverse set of 3D semantic entities, specified using a simple and intuitive interface that includes a user click or a text prompt. To this end, we present DGD, a unified 3D representation for both the appearance and semantics of a dynamic 3D scene, building upon the recently proposed dynamic 3D Gaussians representation. Our representation is optimized over time with both color and semantic information. Key to our method is the joint optimization of the appearance and semantic attributes, which jointly affect the geometric properties of the scene. We evaluate our approach in its ability to enable dense semantic 3D object tracking and demonstrate high-quality results that are fast to render, for a diverse set of scenes. Our project webpage is available on https://isaaclabe.github.io/DGD-Website/
5/30/2024