Schroedinger's Threshold: When the AUC doesn't predict Accuracy
2404.03344
0
0

Abstract
The Area Under Curve measure (AUC) seems apt to evaluate and compare diverse models, possibly without calibration. An important example of AUC application is the evaluation and benchmarking of models that predict faithfulness of generated text. But we show that the AUC yields an academic and optimistic notion of accuracy that can misalign with the actual accuracy observed in application, yielding significant changes in benchmark rankings. To paint a more realistic picture of downstream model performance (and prepare a model for actual application), we explore different calibration modes, testing calibration data and method.
Get summaries of the top AI research delivered straight to your inbox:
Overview
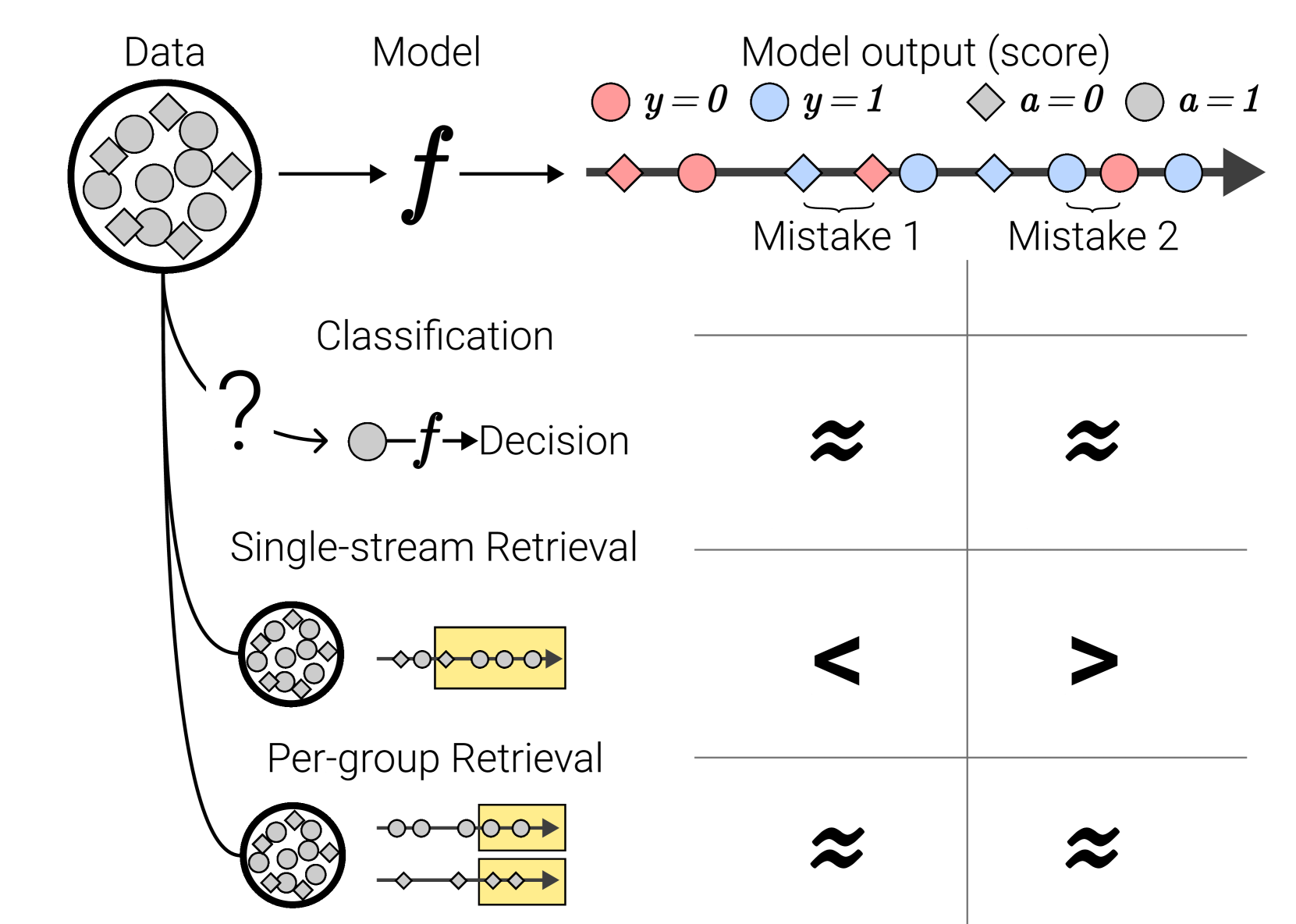
- The paper examines how the Area Under the Curve (AUC) metric, commonly used to evaluate the performance of binary classifiers, may not accurately predict classification accuracy in certain scenarios.
- The authors introduce the concept of "Schroedinger's Threshold," where the optimal decision threshold for maximizing accuracy can differ significantly from the threshold that optimizes the AUC.
- The research provides insights into the limitations of using AUC as the sole performance metric and highlights the importance of considering alternative metrics, such as accuracy, when assessing the real-world applicability of binary classification models.
Plain English Explanation
Imagine you're trying to build a model that can predict whether a customer will buy a product or not. The typical way to evaluate the model's performance is to look at the Area Under the Curve (AUC) metric. This metric tells you how well the model can distinguish between customers who will buy and those who won't.
However, the authors of this paper found that the AUC might not always be the best way to judge a model's real-world performance. They introduced the concept of "Schroedinger's Threshold," which means that the best decision threshold for maximizing the model's accuracy (correctly predicting who will buy and who won't) might be different from the threshold that gives the highest AUC.
Imagine a scenario where the model is really good at identifying the customers who will buy, but not as good at identifying the ones who won't. The AUC might still be high, but the actual accuracy of the model might not be as good as you'd expect. This is where the "Schroedinger's Threshold" comes into play - the threshold that gives the best accuracy might be different from the one that maximizes the AUC.
The key takeaway is that relying solely on the AUC metric might not always give you the full picture of a model's real-world performance. It's important to also consider other metrics, like accuracy, to make sure the model is actually useful in practical applications.
Technical Explanation
The paper investigates the relationship between the Area Under the Curve (AUC) metric and the accuracy of binary classification models. The authors demonstrate that in certain scenarios, the decision threshold that optimizes the AUC can differ significantly from the threshold that maximizes the model's accuracy.
The researchers introduce the concept of "Schroedinger's Threshold," which describes situations where the optimal decision threshold for maximizing accuracy is not the same as the threshold that maximizes the AUC. This can occur when the model's performance is imbalanced, meaning it is better at identifying one class (e.g., customers who will buy) than the other (customers who won't buy).
To illustrate this phenomenon, the paper presents several theoretical and empirical examples. The authors analyze the mathematical relationship between AUC and accuracy, and show how the optimal decision threshold can vary depending on the underlying data distribution and the model's performance characteristics.
The findings of this research highlight the limitations of using AUC as the sole metric for evaluating binary classification models. The paper emphasizes the importance of considering alternative performance metrics, such as accuracy, to better assess the real-world applicability of these models.
Critical Analysis
The paper provides a valuable contribution to the understanding of the limitations of the AUC metric in evaluating binary classification models. The authors' introduction of the "Schroedinger's Threshold" concept offers a compelling explanation for why the AUC may not always be a reliable predictor of a model's practical accuracy.
One potential limitation of the research is the reliance on theoretical and simplified examples to illustrate the "Schroedinger's Threshold" phenomenon. While these examples effectively demonstrate the underlying principles, it would be beneficial to see the authors apply their analysis to more complex, real-world datasets and models to further validate their findings.
Additionally, the paper could have explored the implications of the "Schroedinger's Threshold" concept in greater depth, particularly in the context of specific application domains where the discrepancy between AUC and accuracy could have significant consequences, such as in medical diagnosis or credit risk assessment.
Nevertheless, the paper makes a compelling case for the need to consider a more nuanced approach to model evaluation, one that goes beyond the AUC metric and incorporates a range of performance measures, including accuracy, to ensure the practical viability of binary classification models.
Conclusion
The research presented in this paper highlights an important limitation in the use of the AUC metric for evaluating the performance of binary classification models. The authors introduce the concept of "Schroedinger's Threshold," which demonstrates that the decision threshold that maximizes the AUC may not necessarily be the same as the threshold that optimizes the model's accuracy.
This finding has significant implications for the practical deployment of binary classification models, as it suggests that relying solely on the AUC metric may not provide a complete picture of a model's real-world performance. The paper emphasizes the need for a more holistic approach to model evaluation, one that considers a range of performance measures, including accuracy, to ensure the practical viability of these models.
By drawing attention to this potential pitfall, the research encourages the machine learning community to think critically about the choice and interpretation of performance metrics, ultimately leading to the development of more robust and reliable binary classification models that can be effectively deployed in a variety of application domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
On Fixing the Right Problems in Predictive Analytics: AUC Is Not the Problem
Ryan S. Baker, Nigel Bosch, Stephen Hutt, Andres F. Zambrano, Alex J. Bowers
0
0
Recently, ACM FAccT published an article by Kwegyir-Aggrey and colleagues (2023), critiquing the use of AUC ROC in predictive analytics in several domains. In this article, we offer a critique of that article. Specifically, we highlight technical inaccuracies in that paper's comparison of metrics, mis-specification of the interpretation and goals of AUC ROC, the article's use of the accuracy metric as a gold standard for comparison to AUC ROC, and the article's application of critiques solely to AUC ROC for concerns that would apply to the use of any metric. We conclude with a re-framing of the very valid concerns raised in that article, and discuss how the use of AUC ROC can remain a valid and appropriate practice in a well-informed predictive analytics approach taking those concerns into account. We conclude by discussing the combined use of multiple metrics, including machine learning bias metrics, and AUC ROC's place in such an approach. Like broccoli, AUC ROC is healthy, but also like broccoli, researchers and practitioners in our field shouldn't eat a diet of only AUC ROC.
4/11/2024
A Closer Look at AUROC and AUPRC under Class Imbalance
Matthew B. A. McDermott (Harvard Medical School), Lasse Hyldig Hansen (Aarhus University), Haoran Zhang (Massachusetts Institute of Technology), Giovanni Angelotti (IRCCS Humanitas Research Hospital), Jack Gallifant (Massachusetts Institute of Technology)
0
0
In machine learning (ML), a widespread adage is that the area under the precision-recall curve (AUPRC) is a superior metric for model comparison to the area under the receiver operating characteristic (AUROC) for binary classification tasks with class imbalance. This paper challenges this notion through novel mathematical analysis, illustrating that AUROC and AUPRC can be concisely related in probabilistic terms. We demonstrate that AUPRC, contrary to popular belief, is not superior in cases of class imbalance and might even be a harmful metric, given its inclination to unduly favor model improvements in subpopulations with more frequent positive labels. This bias can inadvertently heighten algorithmic disparities. Prompted by these insights, a thorough review of existing ML literature was conducted, utilizing large language models to analyze over 1.5 million papers from arXiv. Our investigation focused on the prevalence and substantiation of the purported AUPRC superiority. The results expose a significant deficit in empirical backing and a trend of misattributions that have fuelled the widespread acceptance of AUPRC's supposed advantages. Our findings represent a dual contribution: a significant technical advancement in understanding metric behaviors and a stark warning about unchecked assumptions in the ML community. All experiments are accessible at https://github.com/mmcdermott/AUC_is_all_you_need.
4/19/2024
Multiclass ROC
Liang Wang, Luis Carvalho
0
0
Model evaluation is of crucial importance in modern statistics application. The construction of ROC and calculation of AUC have been widely used for binary classification evaluation. Recent research generalizing the ROC/AUC analysis to multi-class classification has problems in at least one of the four areas: 1. failure to provide sensible plots 2. being sensitive to imbalanced data 3. unable to specify mis-classification cost and 4. unable to provide evaluation uncertainty quantification. Borrowing from a binomial matrix factorization model, we provide an evaluation metric summarizing the pair-wise multi-class True Positive Rate (TPR) and False Positive Rate (FPR) with one-dimensional vector representation. Visualization on the representation vector measures the relative speed of increment between TPR and FPR across all the classes pairs, which in turns provides a ROC plot for the multi-class counterpart. An integration over those factorized vector provides a binary AUC-equivalent summary on the classifier performance. Mis-clasification weights specification and bootstrapped confidence interval are also enabled to accommodate a variety of of evaluation criteria. To support our findings, we conducted extensive simulation studies and compared our method to the pair-wise averaged AUC statistics on benchmark datasets.
4/23/2024
Cryptographic Hardness of Score Estimation
Min Jae Song
0
0
We show that $L^2$-accurate score estimation, in the absence of strong assumptions on the data distribution, is computationally hard even when sample complexity is polynomial in the relevant problem parameters. Our reduction builds on the result of Chen et al. (ICLR 2023), who showed that the problem of generating samples from an unknown data distribution reduces to $L^2$-accurate score estimation. Our hard-to-estimate distributions are the Gaussian pancakes distributions, originally due to Diakonikolas et al. (FOCS 2017), which have been shown to be computationally indistinguishable from the standard Gaussian under widely believed hardness assumptions from lattice-based cryptography (Bruna et al., STOC 2021; Gupte et al., FOCS 2022).
4/5/2024