scRDiT: Generating single-cell RNA-seq data by diffusion transformers and accelerating sampling

0

Sign in to get full access
Overview
- This paper introduces scRDiT, a method for generating single-cell RNA sequencing (scRNA-seq) data using diffusion transformers and accelerating sampling.
- The researchers developed a novel deep learning approach to simulate scRNA-seq data, which can be useful for testing algorithms and generating synthetic data for benchmarking.
- The proposed method outperforms existing generative models for scRNA-seq data in terms of sample quality and computational efficiency.
Plain English Explanation
scRDiT: Generating single-cell RNA-seq data by diffusion transformers and accelerating sampling is a research paper that describes a new way to generate artificial single-cell RNA sequencing (scRNA-seq) data. scRNA-seq is a powerful technique that allows researchers to study the gene expression patterns of individual cells, but generating enough real-world data for testing and development can be challenging.
The researchers behind scRDiT developed a deep learning model that can create realistic-looking scRNA-seq datasets. Their approach uses a type of neural network called a "diffusion transformer" to learn the patterns in real scRNA-seq data and then generate new samples that mimic those patterns. Importantly, the researchers also found a way to speed up the process of generating new samples, making it more efficient and practical to use.
This advance could be very helpful for researchers working on new algorithms and tools for analyzing scRNA-seq data. By having access to high-quality synthetic data, they can test their methods without needing to collect large amounts of real data, which can be time-consuming and expensive. Additionally, the generated data can be used to benchmark the performance of different analysis techniques, helping to identify the most effective approaches.
Overall, the scRDiT method represents an important step forward in the field of single-cell genomics, providing a powerful new tool for advancing research and understanding in this rapidly evolving area of biology.
Technical Explanation
The researchers behind scRDiT: Generating single-cell RNA-seq data by diffusion transformers and accelerating sampling developed a novel deep learning approach for generating synthetic single-cell RNA sequencing (scRNA-seq) data. Their method, called scRDiT, uses a diffusion transformer model to learn the underlying patterns in real scRNA-seq datasets and then generate new samples that capture those patterns.
Diffusion models are a type of generative AI that work by iteratively adding noise to data and then learning to reverse the process, allowing them to generate new samples that resemble the original. The researchers combined this diffusion approach with a transformer architecture, which is well-suited for modeling the complex dependencies and structures present in scRNA-seq data.
To accelerate the sampling process and make the model more efficient, the researchers also developed a novel sampling strategy that leverages the structure of the diffusion process. This allows the model to generate new samples more quickly, without sacrificing the quality or fidelity of the generated data.
The researchers evaluated scRDiT on several real-world scRNA-seq datasets and found that it outperformed existing generative models in terms of sample quality and computational efficiency. The generated samples were shown to closely match the statistical properties and biological signatures of the real data, demonstrating the effectiveness of the approach.
Critical Analysis
The scRDiT paper presents a promising new method for generating synthetic scRNA-seq data, but it's important to consider some potential limitations and areas for further research.
One key question is the extent to which the generated samples truly capture the full complexity and diversity of real-world scRNA-seq data. While the researchers demonstrate that scRDiT can match certain statistical properties, there may be more nuanced biological signatures or rare cell types that are not faithfully represented. Additional validation and comparison to other generative models would help to better understand the strengths and weaknesses of the approach.
Additionally, the researchers mention that the current implementation of scRDiT is still computationally intensive, despite the improvements in sampling efficiency. Further advancements in model architecture or training techniques could help to make the method even more practical and scalable for real-world applications.
It would also be valuable to see the scRDiT approach applied to a wider range of scRNA-seq datasets, including those with different cellular compositions, experimental protocols, and biological contexts. This could help to ensure the robustness and generalizability of the method.
Overall, the scRDiT paper represents an exciting development in the field of single-cell genomics, and the researchers have demonstrated the potential of diffusion transformers for generating high-quality synthetic scRNA-seq data. With further refinement and validation, this approach could become a powerful tool for accelerating research and development in this rapidly evolving area of biology.
Conclusion
scRDiT: Generating single-cell RNA-seq data by diffusion transformers and accelerating sampling introduces a novel deep learning method for generating realistic synthetic single-cell RNA sequencing (scRNA-seq) data. The researchers leveraged diffusion transformers, a cutting-edge generative AI technique, to capture the complex patterns and structures present in real-world scRNA-seq datasets.
Importantly, the team also developed an accelerated sampling strategy that allows the scRDiT model to generate new samples more efficiently, without compromising the quality or fidelity of the output. This could make the method a valuable tool for researchers working on scRNA-seq data analysis, as they can use the generated samples to test new algorithms and benchmark performance without the need for large amounts of real-world data.
Overall, the scRDiT paper represents an exciting advancement in the field of single-cell genomics, demonstrating the potential of deep learning to unlock new capabilities for data generation and simulation. As the research in this area continues to evolve, methods like scRDiT are likely to play an increasingly important role in accelerating scientific discovery and driving progress in our understanding of complex biological systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
scRDiT: Generating single-cell RNA-seq data by diffusion transformers and accelerating sampling
Shengze Dong, Zhuorui Cui, Ding Liu, Jinzhi Lei
Motivation: Single-cell RNA sequencing (scRNA-seq) is a groundbreaking technology extensively utilized in biological research, facilitating the examination of gene expression at the individual cell level within a given tissue sample. While numerous tools have been developed for scRNA-seq data analysis, the challenge persists in capturing the distinct features of such data and replicating virtual datasets that share analogous statistical properties. Results: Our study introduces a generative approach termed scRNA-seq Diffusion Transformer (scRDiT). This method generates virtual scRNA-seq data by leveraging a real dataset. The method is a neural network constructed based on Denoising Diffusion Probabilistic Models (DDPMs) and Diffusion Transformers (DiTs). This involves subjecting Gaussian noises to the real dataset through iterative noise-adding steps and ultimately restoring the noises to form scRNA-seq samples. This scheme allows us to learn data features from actual scRNA-seq samples during model training. Our experiments, conducted on two distinct scRNA-seq datasets, demonstrate superior performance. Additionally, the model sampling process is expedited by incorporating Denoising Diffusion Implicit Models (DDIM). scRDiT presents a unified methodology empowering users to train neural network models with their unique scRNA-seq datasets, enabling the generation of numerous high-quality scRNA-seq samples. Availability and implementation: https://github.com/DongShengze/scRDiT
Read more4/10/2024

0
SpaDiT: Diffusion Transformer for Spatial Gene Expression Prediction using scRNA-seq
Xiaoyu Li, Fangfang Zhu, Wenwen Min
The rapid development of spatial transcriptomics (ST) technologies is revolutionizing our understanding of the spatial organization of biological tissues. Current ST methods, categorized into next-generation sequencing-based (seq-based) and fluorescence in situ hybridization-based (image-based) methods, offer innovative insights into the functional dynamics of biological tissues. However, these methods are limited by their cellular resolution and the quantity of genes they can detect. To address these limitations, we propose SpaDiT, a deep learning method that utilizes a diffusion generative model to integrate scRNA-seq and ST data for the prediction of undetected genes. By employing a Transformer-based diffusion model, SpaDiT not only accurately predicts unknown genes but also effectively generates the spatial structure of ST genes. We have demonstrated the effectiveness of SpaDiT through extensive experiments on both seq-based and image-based ST data. SpaDiT significantly contributes to ST gene prediction methods with its innovative approach. Compared to eight leading baseline methods, SpaDiT achieved state-of-the-art performance across multiple metrics, highlighting its substantial bioinformatics contribution.
Read more7/19/2024
0
Latent Diffusion Models for Controllable RNA Sequence Generation
Kaixuan Huang, Yukang Yang, Kaidi Fu, Yanyi Chu, Le Cong, Mengdi Wang
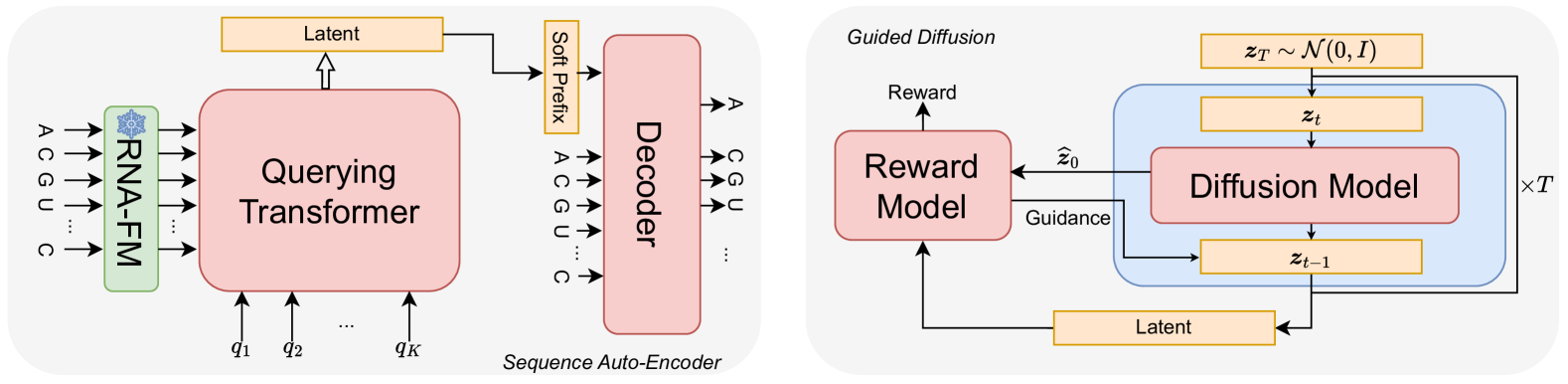
This paper presents RNAdiffusion, a latent diffusion model for generating and optimizing discrete RNA sequences. RNA is a particularly dynamic and versatile molecule in biological processes. RNA sequences exhibit high variability and diversity, characterized by their variable lengths, flexible three-dimensional structures, and diverse functions. We utilize pretrained BERT-type models to encode raw RNAs into token-level biologically meaningful representations. A Q-Former is employed to compress these representations into a fixed-length set of latent vectors, with an autoregressive decoder trained to reconstruct RNA sequences from these latent variables. We then develop a continuous diffusion model within this latent space. To enable optimization, we train reward networks to estimate functional properties of RNA from the latent variables. We employ gradient-based guidance during the backward diffusion process, aiming to generate RNA sequences that are optimized for higher rewards. Empirical experiments confirm that RNAdiffusion generates non-coding RNAs that align with natural distributions across various biological indicators. We fine-tuned the diffusion model on untranslated regions (UTRs) of mRNA and optimize sample sequences for protein translation efficiencies. Our guided diffusion model effectively generates diverse UTR sequences with high Mean Ribosome Loading (MRL) and Translation Efficiency (TE), surpassing baselines. These results hold promise for studies on RNA sequence-function relationships, protein synthesis, and enhancing therapeutic RNA design.
Read more9/17/2024
✨
0
Multi-Resolution Diffusion for Privacy-Sensitive Recommender Systems
Derek Lilienthal, Paul Mello, Magdalini Eirinaki, Stas Tiomkin
While recommender systems have become an integral component of the Web experience, their heavy reliance on user data raises privacy and security concerns. Substituting user data with synthetic data can address these concerns, but accurately replicating these real-world datasets has been a notoriously challenging problem. Recent advancements in generative AI have demonstrated the impressive capabilities of diffusion models in generating realistic data across various domains. In this work we introduce a Score-based Diffusion Recommendation Module (SDRM), which captures the intricate patterns of real-world datasets required for training highly accurate recommender systems. SDRM allows for the generation of synthetic data that can replace existing datasets to preserve user privacy, or augment existing datasets to address excessive data sparsity. Our method outperforms competing baselines such as generative adversarial networks, variational autoencoders, and recently proposed diffusion models in synthesizing various datasets to replace or augment the original data by an average improvement of 4.30% in Recall@k and 4.65% in NDCG@k.
Read more6/21/2024