A-SDM: Accelerating Stable Diffusion through Model Assembly and Feature Inheritance Strategies

0
Sign in to get full access
Overview
- The paper "A-SDM: Accelerating Stable Diffusion through Model Assembly and Feature Inheritance Strategies" proposes a method to speed up the popular Stable Diffusion text-to-image generation model.
- The key ideas are to assemble the model from smaller, pre-trained components and transfer features between them to reduce overall computation.
- Experiments show the proposed A-SDM method can significantly reduce inference time and memory usage compared to the original Stable Diffusion model.
Plain English Explanation
The paper describes a way to make the Stable Diffusion model, which can generate images from text prompts, run faster and use less memory. The key insight is that you don't need to train the entire Stable Diffusion model from scratch - you can take smaller, pre-trained model components and assemble them together. This "model assembly" approach allows the system to reuse features learned in the pre-trained components, reducing the overall computational cost.
Additionally, the researchers use a "feature inheritance" technique, where they transfer useful features from one part of the model to another. This further improves efficiency without sacrificing the model's performance on the image generation task.
The end result is a version of Stable Diffusion, called A-SDM, that runs significantly faster and uses less memory than the original, while still producing high-quality images. This could make Stable Diffusion more accessible on less powerful hardware, opening up the technology to a wider range of users and applications.
Technical Explanation
The paper proposes the "Accelerated Stable Diffusion Model" (A-SDM), which uses two key strategies to speed up the inference of the original Stable Diffusion model:
-
Model Assembly: Instead of training the entire Stable Diffusion model from scratch, A-SDM assembles the model from smaller, pre-trained components. This allows the system to reuse features learned by these pre-trained modules, reducing the overall computational cost.
-
Feature Inheritance: A-SDM also employs a "feature inheritance" technique, where useful features are transferred from one part of the model to another. This further enhances the efficiency of the model without compromising its image generation capabilities.
The paper presents experiments comparing the performance of A-SDM to the original Stable Diffusion model. The results show that A-SDM can significantly reduce inference time and memory usage, while maintaining comparable image quality. For example, A-SDM can generate images 2-3x faster and use up to 50% less memory than the original Stable Diffusion model.
Critical Analysis
The paper provides a compelling approach to accelerating the popular Stable Diffusion model, but it's worth noting a few potential caveats and areas for further research:
-
The performance improvements of A-SDM are heavily dependent on the quality and compatibility of the pre-trained model components used. If these components are not well-suited for the task, the benefits of the model assembly approach may be diminished.
-
The feature inheritance strategy relies on the assumption that transferring features between different parts of the model will be beneficial. In practice, this may not always be the case, and further research is needed to understand the optimal conditions for effective feature transfer.
-
The paper focuses on inference-time improvements, but does not address the training process for A-SDM. It's unclear how the model assembly and feature inheritance strategies would impact the training time and complexity, which could be an important consideration for real-world deployment.
-
The experiments in the paper are conducted on a limited set of text-to-image generation tasks. Further testing on a broader range of applications and datasets would help validate the generalizability of the A-SDM approach.
Despite these potential limitations, the core ideas presented in the paper, such as model assembly and feature inheritance, are promising and could inspire further research and development in the field of efficient deep learning model design.
Conclusion
The "A-SDM: Accelerating Stable Diffusion through Model Assembly and Feature Inheritance Strategies" paper introduces a novel approach to improving the efficiency of the popular Stable Diffusion text-to-image generation model. By assembling the model from smaller, pre-trained components and transferring features between them, the researchers were able to significantly reduce inference time and memory usage without compromising image quality.
These strategies could have far-reaching implications, making high-performance text-to-image generation more accessible on a wider range of hardware, including resource-constrained devices. As the demand for such capabilities continues to grow, innovations like A-SDM could play a crucial role in democratizing and expanding the reach of this transformative technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A-SDM: Accelerating Stable Diffusion through Model Assembly and Feature Inheritance Strategies
Jinchao Zhu, Yuxuan Wang, Siyuan Pan, Pengfei Wan, Di Zhang, Gao Huang
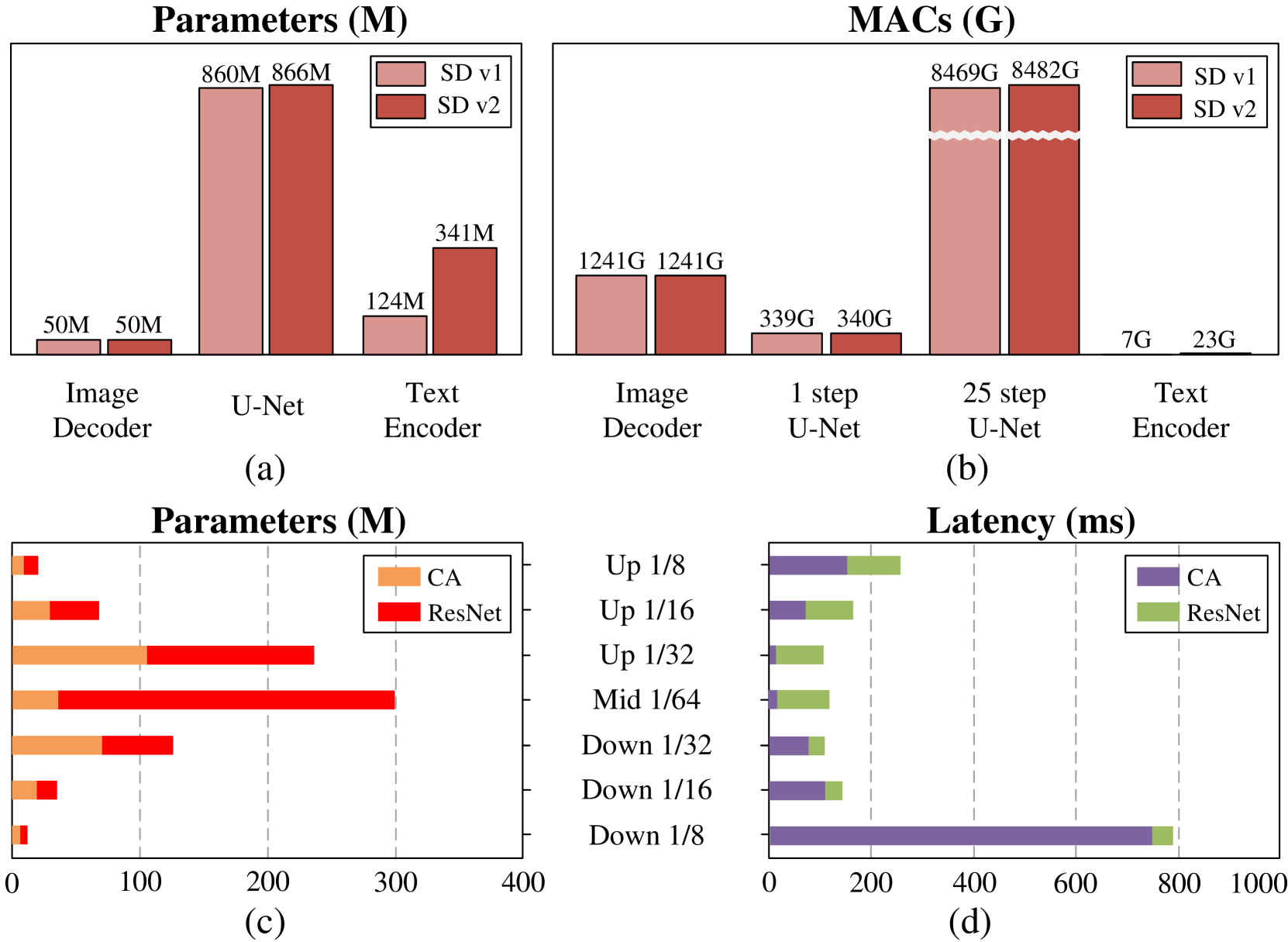
The Stable Diffusion Model (SDM) is a prevalent and effective model for text-to-image (T2I) and image-to-image (I2I) generation. Despite various attempts at sampler optimization, model distillation, and network quantification, these approaches typically maintain the original network architecture. The extensive parameter scale and substantial computational demands have limited research into adjusting the model architecture. This study focuses on reducing redundant computation in SDM and optimizes the model through both tuning and tuning-free methods. 1) For the tuning method, we design a model assembly strategy to reconstruct a lightweight model while preserving performance through distillation. Second, to mitigate performance loss due to pruning, we incorporate multi-expert conditional convolution (ME-CondConv) into compressed UNets to enhance network performance by increasing capacity without sacrificing speed. Third, we validate the effectiveness of the multi-UNet switching method for improving network speed. 2) For the tuning-free method, we propose a feature inheritance strategy to accelerate inference by skipping local computations at the block, layer, or unit level within the network structure. We also examine multiple sampling modes for feature inheritance at the time-step level. Experiments demonstrate that both the proposed tuning and the tuning-free methods can improve the speed and performance of the SDM. The lightweight model reconstructed by the model assembly strategy increases generation speed by $22.4%$, while the feature inheritance strategy enhances the SDM generation speed by $40.0%$.
Read more6/18/2024
0
Diffusion Models Are Innate One-Step Generators
Bowen Zheng, Tianming Yang
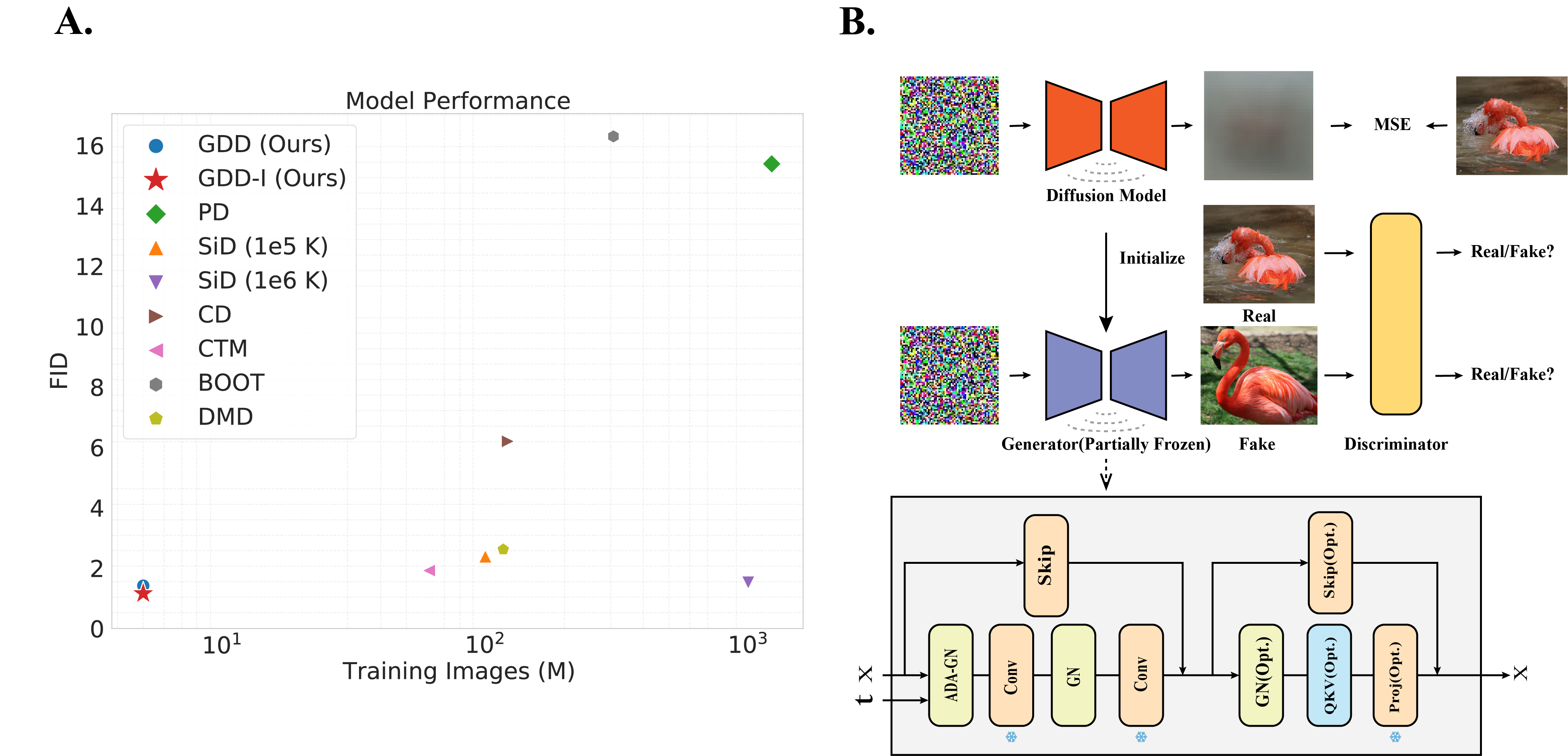
Diffusion Models (DMs) have achieved great success in image generation and other fields. By fine sampling through the trajectory defined by the SDE/ODE solver based on a well-trained score model, DMs can generate remarkable high-quality results. However, this precise sampling often requires multiple steps and is computationally demanding. To address this problem, instance-based distillation methods have been proposed to distill a one-step generator from a DM by having a simpler student model mimic a more complex teacher model. Yet, our research reveals an inherent limitations in these methods: the teacher model, with more steps and more parameters, occupies different local minima compared to the student model, leading to suboptimal performance when the student model attempts to replicate the teacher. To avoid this problem, we introduce a novel distributional distillation method, which uses an exclusive distributional loss. This method exceeds state-of-the-art (SOTA) results while requiring significantly fewer training images. Additionally, we show that DMs' layers are differentially activated at different time steps, leading to an inherent capability to generate images in a single step. Freezing most of the convolutional layers in a DM during distributional distillation enables this innate capability and leads to further performance improvements. Our method achieves the SOTA results on CIFAR-10 (FID 1.54), AFHQv2 64x64 (FID 1.23), FFHQ 64x64 (FID 0.85) and ImageNet 64x64 (FID 1.16) with great efficiency. Most of those results are obtained with only 5 million training images within 6 hours on 8 A100 GPUs.
Read more6/10/2024

0
SCott: Accelerating Diffusion Models with Stochastic Consistency Distillation
Hongjian Liu, Qingsong Xie, Zhijie Deng, Chen Chen, Shixiang Tang, Fueyang Fu, Zheng-jun Zha, Haonan Lu
The iterative sampling procedure employed by diffusion models (DMs) often leads to significant inference latency. To address this, we propose Stochastic Consistency Distillation (SCott) to enable accelerated text-to-image generation, where high-quality generations can be achieved with just 1-2 sampling steps, and further improvements can be obtained by adding additional steps. In contrast to vanilla consistency distillation (CD) which distills the ordinary differential equation solvers-based sampling process of a pretrained teacher model into a student, SCott explores the possibility and validates the efficacy of integrating stochastic differential equation (SDE) solvers into CD to fully unleash the potential of the teacher. SCott is augmented with elaborate strategies to control the noise strength and sampling process of the SDE solver. An adversarial loss is further incorporated to strengthen the sample quality with rare sampling steps. Empirically, on the MSCOCO-2017 5K dataset with a Stable Diffusion-V1.5 teacher, SCott achieves an FID (Frechet Inceptio Distance) of 22.1, surpassing that (23.4) of the 1-step InstaFlow (Liu et al., 2023) and matching that of 4-step UFOGen (Xue et al., 2023b). Moreover, SCott can yield more diverse samples than other consistency models for high-resolution image generation (Luo et al., 2023a), with up to 16% improvement in a qualified metric. The code and checkpoints are coming soon.
Read more4/16/2024

0
Hybrid SD: Edge-Cloud Collaborative Inference for Stable Diffusion Models
Chenqian Yan, Songwei Liu, Hongjian Liu, Xurui Peng, Xiaojian Wang, Fangming Chen, Lean Fu, Xing Mei
Stable Diffusion Models (SDMs) have shown remarkable proficiency in image synthesis. However, their broad application is impeded by their large model sizes and intensive computational requirements, which typically require expensive cloud servers for deployment. On the flip side, while there are many compact models tailored for edge devices that can reduce these demands, they often compromise on semantic integrity and visual quality when compared to full-sized SDMs. To bridge this gap, we introduce Hybrid SD, an innovative, training-free SDMs inference framework designed for edge-cloud collaborative inference. Hybrid SD distributes the early steps of the diffusion process to the large models deployed on cloud servers, enhancing semantic planning. Furthermore, small efficient models deployed on edge devices can be integrated for refining visual details in the later stages. Acknowledging the diversity of edge devices with differing computational and storage capacities, we employ structural pruning to the SDMs U-Net and train a lightweight VAE. Empirical evaluations demonstrate that our compressed models achieve state-of-the-art parameter efficiency (225.8M) on edge devices with competitive image quality. Additionally, Hybrid SD reduces the cloud cost by 66% with edge-cloud collaborative inference.
Read more8/14/2024