Seamless Language Expansion: Enhancing Multilingual Mastery in Self-Supervised Models
2406.14092
0
0
Abstract
Self-supervised (SSL) models have shown great performance in various downstream tasks. However, they are typically developed for limited languages, and may encounter new languages in real-world. Developing a SSL model for each new language is costly. Thus, it is vital to figure out how to efficiently adapt existed SSL models to a new language without impairing its original abilities. We propose adaptation methods which integrate LoRA to existed SSL models to extend new language. We also develop preservation strategies which include data combination and re-clustering to retain abilities on existed languages. Applied to mHuBERT, we investigate their effectiveness on speech re-synthesis task. Experiments show that our adaptation methods enable mHuBERT to be applied to a new language (Mandarin) with MOS value increased about 1.6 and the relative value of WER reduced up to 61.72%. Also, our preservation strategies ensure that the performance on both existed and new languages remains intact.
Create account to get full access
Overview
- This paper proposes a method for expanding the language capabilities of self-supervised models, enabling them to learn and master new languages seamlessly.
- The key idea is to leverage existing language knowledge in the model to facilitate the acquisition of new languages, rather than training each language independently.
- This approach aims to enhance the multilingual proficiency of self-supervised models, making them more versatile and applicable across a broader range of linguistic domains.
Plain English Explanation
The paper describes a way to help AI language models become better at understanding and using multiple languages. Typically, language models are trained on one language at a time, which can be time-consuming and inefficient. Instead, the researchers suggest using the knowledge the models already have about one language to help them learn new languages more easily.
For example, if a model is already good at English, it can use that knowledge to pick up new languages like Spanish or Mandarin Chinese faster. The model can identify similarities between the languages and transfer what it has learned, rather than starting from scratch each time. This is similar to how humans can leverage their knowledge of one language to more easily learn another related language.
By making language models more multilingual, they become more versatile and can be applied to a wider range of tasks and real-world scenarios that require understanding multiple languages. [This could be especially useful for applications like large language models for expansion of spoken language understanding or low-rank adaptation to new languages.]
Technical Explanation
The paper introduces a "Seamless Language Expansion" (SLE) method to enhance the multilingual capabilities of self-supervised models. SLE leverages the existing language knowledge in the model to facilitate the learning of new languages, rather than training each language independently.
The key elements of the SLE method include:
-
Language-Agnostic Representation Learning: The model is trained to learn language-agnostic representations that capture the underlying structure and semantics common across languages. This allows the model to transfer knowledge more effectively when learning new languages.
-
Language-Specific Adaptation: When a new language is introduced, the model adapts its language-specific components, such as the vocabulary and linguistic features, while preserving the shared language-agnostic knowledge. This enables the model to learn the new language more efficiently.
-
Seamless Language Switching: The model can fluidly switch between languages during inference, allowing it to handle multilingual inputs and outputs without the need for explicit language identification or specialized language models. [This is similar to how SambaLingo aims to teach large language models new languages.]
The researchers evaluate the SLE method on various multilingual benchmarks and demonstrate its effectiveness in enhancing the multilingual proficiency of self-supervised models, particularly in low-resource language settings. [This builds on prior work on leveraging self-supervised hierarchical representations for multilingualism.]
Critical Analysis
The paper presents a compelling approach for expanding the language capabilities of self-supervised models, but there are a few potential limitations and areas for further research:
-
Scalability: The authors focus on a relatively small number of languages in their experiments. It remains to be seen how well the SLE method scales to a larger and more diverse set of languages, especially those with more distant linguistic relationships.
-
Multimodal Integration: The paper primarily considers text-based language learning. Exploring ways to integrate multimodal information, such as speech or images, could further enhance the model's language understanding and generation abilities.
-
Ethical Considerations: As language models become more multilingual and widely used, it is crucial to consider the potential societal impact, including issues of language bias, fairness, and accessibility for underrepresented linguistic communities.
Overall, the SLE method represents an important step forward in improving the multilingual capabilities of self-supervised models, with promising applications across a range of language-related tasks and domains.
Conclusion
The paper introduces a "Seamless Language Expansion" (SLE) method that enables self-supervised models to learn and master new languages more efficiently by leveraging their existing language knowledge. This approach aims to enhance the multilingual proficiency of these models, making them more versatile and applicable across a broader range of linguistic domains.
The key innovations of the SLE method include language-agnostic representation learning, language-specific adaptation, and seamless language switching, all of which contribute to the model's ability to acquire new languages more effectively. While the paper demonstrates the effectiveness of the SLE method on various benchmarks, further research is needed to address potential scalability and ethical challenges as these models become more widely adopted.
Overall, the work presented in this paper represents an important step forward in advancing the multilingual capabilities of self-supervised models, with promising implications for a wide range of language-related applications and services.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
An Initial Investigation of Language Adaptation for TTS Systems under Low-resource Scenarios
Cheng Gong, Erica Cooper, Xin Wang, Chunyu Qiang, Mengzhe Geng, Dan Wells, Longbiao Wang, Jianwu Dang, Marc Tessier, Aidan Pine, Korin Richmond, Junichi Yamagishi
0
0
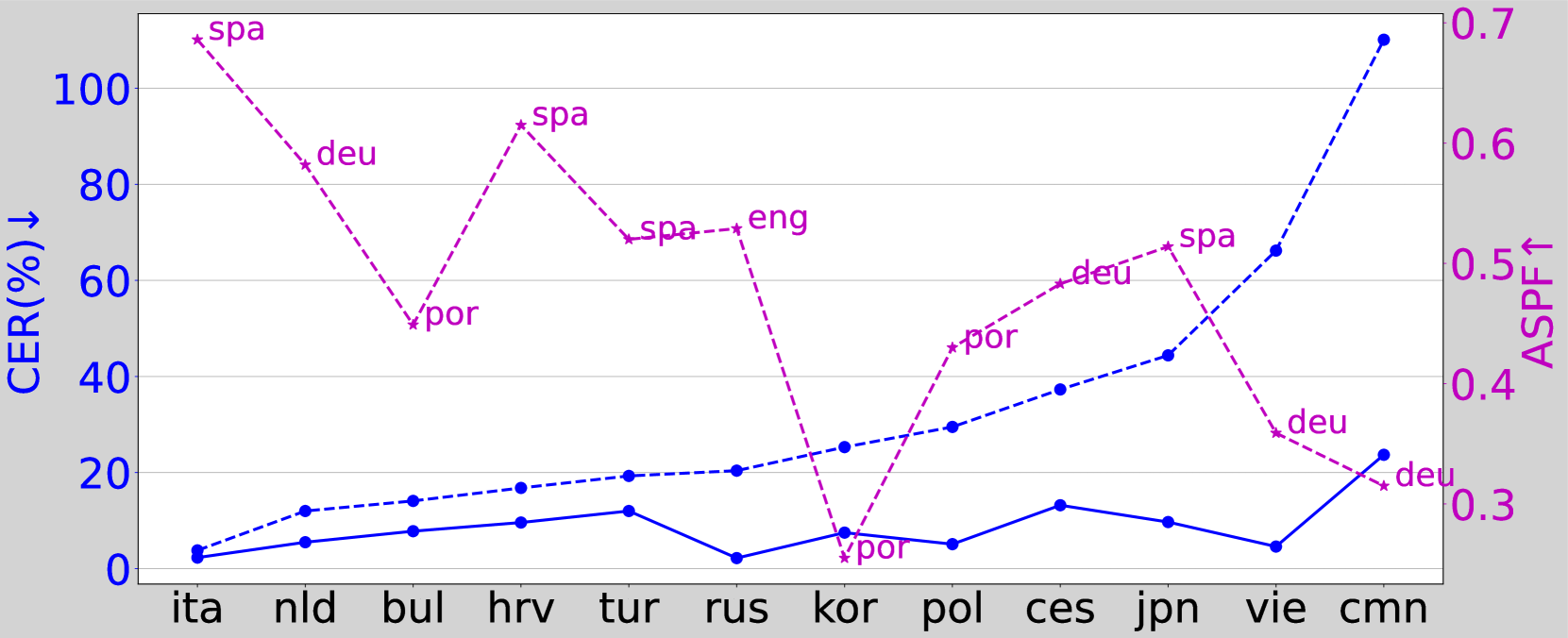
Self-supervised learning (SSL) representations from massively multilingual models offer a promising solution for low-resource language speech tasks. Despite advancements, language adaptation in TTS systems remains an open problem. This paper explores the language adaptation capability of ZMM-TTS, a recent SSL-based multilingual TTS system proposed in our previous work. We conducted experiments on 12 languages using limited data with various fine-tuning configurations. We demonstrate that the similarity in phonetics between the pre-training and target languages, as well as the language category, affects the target language's adaptation performance. Additionally, we find that the fine-tuning dataset size and number of speakers influence adaptability. Surprisingly, we also observed that using paired data for fine-tuning is not always optimal compared to audio-only data. Beyond speech intelligibility, our analysis covers speaker similarity, language identification, and predicted MOS.
6/14/2024
💬
Large Language Models for Expansion of Spoken Language Understanding Systems to New Languages
Jakub Hoscilowicz, Pawel Pawlowski, Marcin Skorupa, Marcin Sowa'nski, Artur Janicki
0
0
Spoken Language Understanding (SLU) models are a core component of voice assistants (VA), such as Alexa, Bixby, and Google Assistant. In this paper, we introduce a pipeline designed to extend SLU systems to new languages, utilizing Large Language Models (LLMs) that we fine-tune for machine translation of slot-annotated SLU training data. Our approach improved on the MultiATIS++ benchmark, a primary multi-language SLU dataset, in the cloud scenario using an mBERT model. Specifically, we saw an improvement in the Overall Accuracy metric: from 53% to 62.18%, compared to the existing state-of-the-art method, Fine and Coarse-grained Multi-Task Learning Framework (FC-MTLF). In the on-device scenario (tiny and not pretrained SLU), our method improved the Overall Accuracy from 5.31% to 22.06% over the baseline Global-Local Contrastive Learning Framework (GL-CLeF) method. Contrary to both FC-MTLF and GL-CLeF, our LLM-based machine translation does not require changes in the production architecture of SLU. Additionally, our pipeline is slot-type independent: it does not require any slot definitions or examples.
4/4/2024

SambaLingo: Teaching Large Language Models New Languages
Zoltan Csaki, Bo Li, Jonathan Li, Qiantong Xu, Pian Pawakapan, Leon Zhang, Yun Du, Hengyu Zhao, Changran Hu, Urmish Thakker
0
0
Despite the widespread availability of LLMs, there remains a substantial gap in their capabilities and availability across diverse languages. One approach to address these issues has been to take an existing pre-trained LLM and continue to train it on new languages. While prior works have experimented with language adaptation, many questions around best practices and methodology have not been covered. In this paper, we present a comprehensive investigation into the adaptation of LLMs to new languages. Our study covers the key components in this process, including vocabulary extension, direct preference optimization and the data scarcity problem for human alignment in low-resource languages. We scale these experiments across 9 languages and 2 parameter scales (7B and 70B). We compare our models against Llama 2, Aya-101, XGLM, BLOOM and existing language experts, outperforming all prior published baselines. Additionally, all evaluation code and checkpoints are made public to facilitate future research.
4/10/2024
Dual-Pipeline with Low-Rank Adaptation for New Language Integration in Multilingual ASR
Yerbolat Khassanov, Zhipeng Chen, Tianfeng Chen, Tze Yuang Chong, Wei Li, Jun Zhang, Lu Lu, Yuxuan Wang
0
0
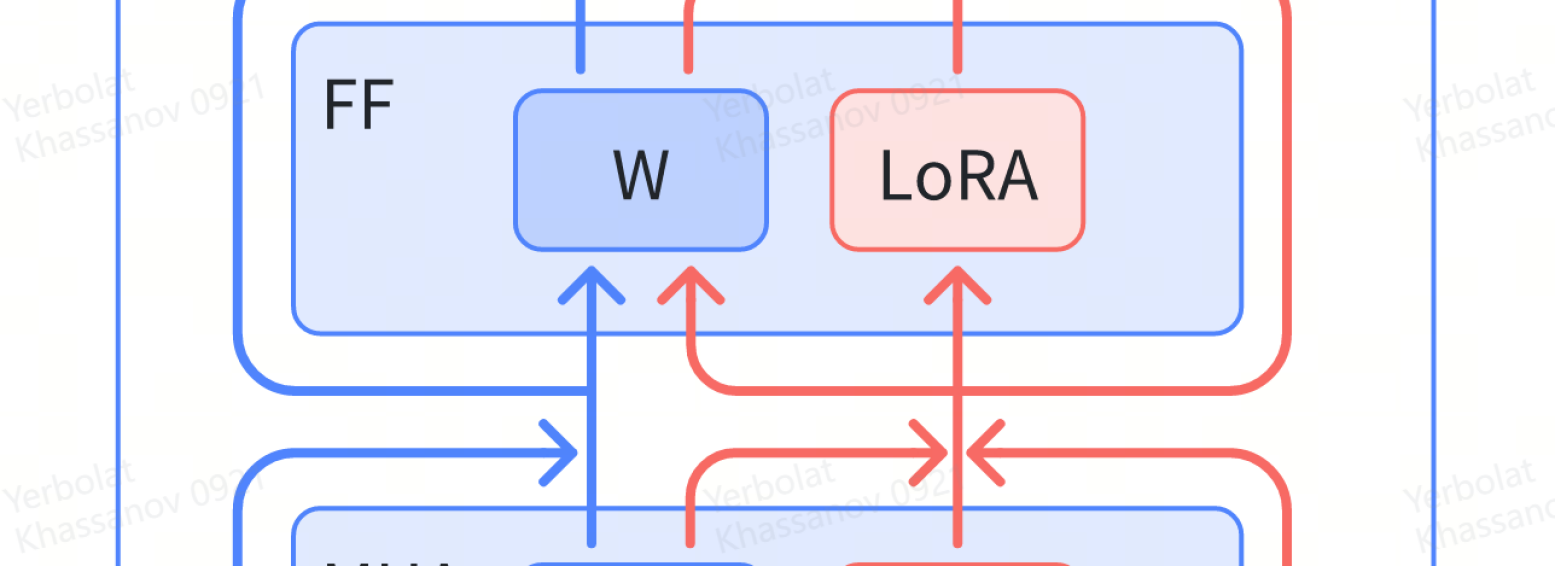
This paper addresses challenges in integrating new languages into a pre-trained multilingual automatic speech recognition (mASR) system, particularly in scenarios where training data for existing languages is limited or unavailable. The proposed method employs a dual-pipeline with low-rank adaptation (LoRA). It maintains two data flow pipelines-one for existing languages and another for new languages. The primary pipeline follows the standard flow through the pre-trained parameters of mASR, while the secondary pipeline additionally utilizes language-specific parameters represented by LoRA and a separate output decoder module. Importantly, the proposed approach minimizes the performance degradation of existing languages and enables a language-agnostic operation mode, facilitated by a decoder selection strategy. We validate the effectiveness of the proposed method by extending the pre-trained Whisper model to 19 new languages from the FLEURS dataset
6/13/2024