An Initial Investigation of Language Adaptation for TTS Systems under Low-resource Scenarios
2406.08911
0
0
Abstract
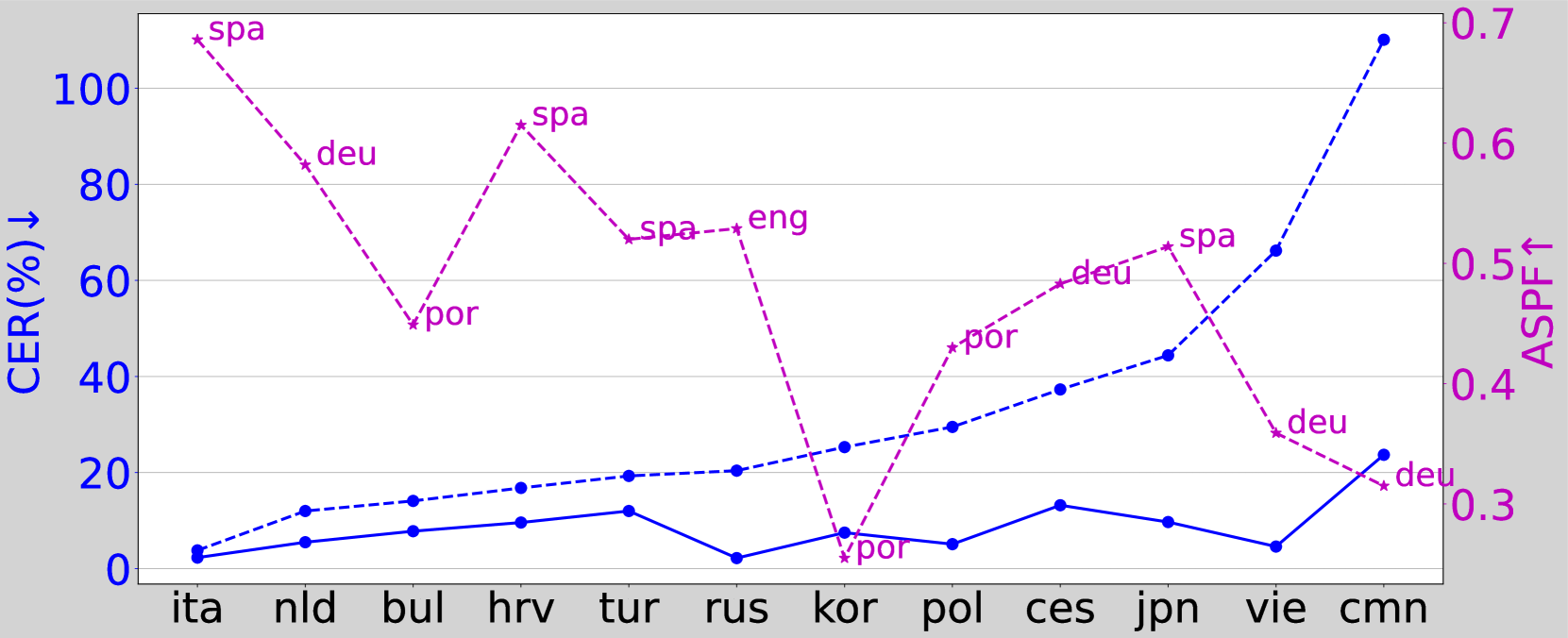
Self-supervised learning (SSL) representations from massively multilingual models offer a promising solution for low-resource language speech tasks. Despite advancements, language adaptation in TTS systems remains an open problem. This paper explores the language adaptation capability of ZMM-TTS, a recent SSL-based multilingual TTS system proposed in our previous work. We conducted experiments on 12 languages using limited data with various fine-tuning configurations. We demonstrate that the similarity in phonetics between the pre-training and target languages, as well as the language category, affects the target language's adaptation performance. Additionally, we find that the fine-tuning dataset size and number of speakers influence adaptability. Surprisingly, we also observed that using paired data for fine-tuning is not always optimal compared to audio-only data. Beyond speech intelligibility, our analysis covers speaker similarity, language identification, and predicted MOS.
Create account to get full access
Overview
- This paper investigates techniques for adapting text-to-speech (TTS) systems to low-resource languages, where limited data is available for training.
- The researchers explore multilingual TTS models that can be fine-tuned on small amounts of target language data, as well as self-supervised learning approaches to leverage untranscribed speech.
- The paper also looks at targeted adaptation techniques for language families, and the use of large language models like LLaMA to enhance TTS for low-resource settings.
Plain English Explanation
The researchers in this paper are looking at ways to improve text-to-speech (TTS) systems for languages that don't have a lot of available data for training. TTS is the technology that allows computers to turn written text into spoken audio, but it usually requires a large dataset of audio recordings and transcripts to work well.
For languages with limited data, the researchers are exploring a few different approaches. One is to build multilingual TTS models that can be fine-tuned on small amounts of target language data. This means starting with a model trained on many languages, then doing additional training on the new, low-resource language to adapt it.
Another approach is to use self-supervised learning, which means finding ways to learn from speech audio even without written transcripts. This could help leverage untranscribed speech data that may be more available than fully labeled datasets.
The paper also looks at targeting adaptations for entire language families, rather than just individual languages. This could be more efficient than training completely separate models for each low-resource language.
Finally, the researchers explore using large language models like LLaMA to enhance the TTS systems for low-resource settings. These large models trained on huge amounts of text data might be able to provide helpful context and information to improve the TTS output.
The overall goal is to find ways to build high-quality TTS systems for languages that don't have a lot of data available, which could make speech technology more accessible to a wider range of users and communities.
Technical Explanation
The researchers in this paper explore several techniques for adapting text-to-speech (TTS) systems to low-resource language scenarios, where limited data is available for training.
One approach they investigate is the use of multilingual TTS models that can be fine-tuned on small amounts of target language data. By starting with a model trained on many languages, they can leverage this broader knowledge and then perform additional training on the new, low-resource language to adapt the system.
The paper also looks at leveraging self-supervised learning (SSL) techniques to learn from untranscribed speech data, which may be more readily available than fully labeled datasets for low-resource languages.
In addition, the researchers explore targeted adaptation approaches that focus on entire language families, rather than individual languages. This could be more efficient than training separate models for each low-resource language.
Finally, the paper investigates the use of large language models like LLaMA to enhance the TTS systems for low-resource settings. These large models trained on vast amounts of text data may be able to provide helpful context and information to improve the TTS output.
Through these various techniques, the researchers aim to develop high-quality TTS systems that can be effectively deployed for languages with limited available data, potentially making speech technology more accessible to a wider range of users and communities.
Critical Analysis
The paper presents a comprehensive exploration of techniques for adapting TTS systems to low-resource language scenarios, which is a crucial challenge for expanding the reach of speech technology. The researchers cover a range of promising approaches, including multilingual modeling, self-supervised learning, targeted adaptation, and the incorporation of large language models.
One potential limitation of the work is the lack of extensive real-world evaluations on diverse low-resource languages. While the paper includes some experiments, further testing on a broader range of target languages and language families would help validate the effectiveness of the proposed methods.
Additionally, the paper does not delve deeply into the ethical considerations of deploying TTS systems in low-resource settings. Issues around data privacy, fairness, and potential biases should be carefully examined, as these systems may be used in contexts with vulnerable populations.
Future research could also explore ways to better integrate the different techniques presented in the paper, potentially yielding synergistic benefits. For example, combining multilingual modeling with targeted adaptation and large language model integration could lead to more robust and efficient low-resource TTS solutions.
Overall, this paper represents an important step forward in addressing the critical challenge of enabling high-quality speech technology for a diverse range of languages and communities. By continuing to push the boundaries of low-resource TTS adaptation, the field can work towards making voice-based interfaces and services more accessible and inclusive.
Conclusion
This paper investigates a range of techniques for adapting text-to-speech (TTS) systems to low-resource language scenarios, where limited data is available for training. The researchers explore multilingual TTS models, self-supervised learning approaches, targeted adaptation for language families, and the use of large language models to enhance TTS performance in these challenging settings.
The proposed methods aim to enable the development of high-quality TTS systems that can be effectively deployed for a wider range of languages, potentially making speech technology more accessible to diverse users and communities. While the paper presents promising results, further real-world evaluations and considerations around ethical deployment will be important for realizing the full potential of these approaches.
By continuing to advance the state of the art in low-resource TTS adaptation, the field can work towards a future where voice-based interfaces and services are truly inclusive and accessible to people around the world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Leveraging Parameter-Efficient Transfer Learning for Multi-Lingual Text-to-Speech Adaptation
Yingting Li, Ambuj Mehrish, Bryan Chew, Bo Cheng, Soujanya Poria
0
0
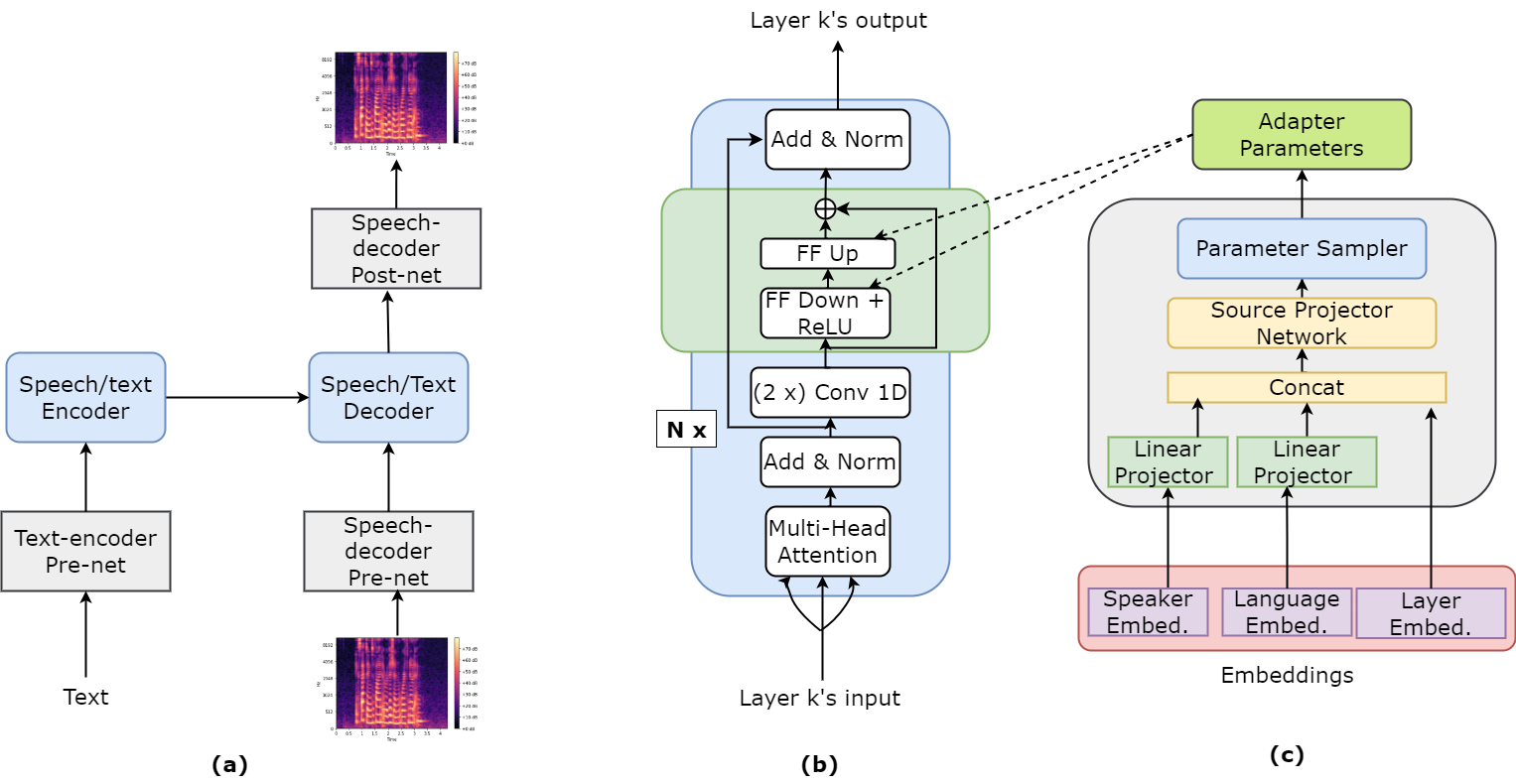
Different languages have distinct phonetic systems and vary in their prosodic features making it challenging to develop a Text-to-Speech (TTS) model that can effectively synthesise speech in multilingual settings. Furthermore, TTS architecture needs to be both efficient enough to capture nuances in multiple languages and efficient enough to be practical for deployment. The standard approach is to build transformer based model such as SpeechT5 and train it on large multilingual dataset. As the size of these models grow the conventional fine-tuning for adapting these model becomes impractical due to heavy computational cost. In this paper, we proposes to integrate parameter-efficient transfer learning (PETL) methods such as adapters and hypernetwork with TTS architecture for multilingual speech synthesis. Notably, in our experiments PETL methods able to achieve comparable or even better performance compared to full fine-tuning with only $sim$2.5% tunable parameters.The code and samples are available at: https://anonymous.4open.science/r/multilingualTTS-BA4C.
6/26/2024
🚀
Low-Resource Self-Supervised Learning with SSL-Enhanced TTS
Po-chun Hsu, Ali Elkahky, Wei-Ning Hsu, Yossi Adi, Tu Anh Nguyen, Jade Copet, Emmanuel Dupoux, Hung-yi Lee, Abdelrahman Mohamed
0
0
Self-supervised learning (SSL) techniques have achieved remarkable results in various speech processing tasks. Nonetheless, a significant challenge remains in reducing the reliance on vast amounts of speech data for pre-training. This paper proposes to address this challenge by leveraging synthetic speech to augment a low-resource pre-training corpus. We construct a high-quality text-to-speech (TTS) system with limited resources using SSL features and generate a large synthetic corpus for pre-training. Experimental results demonstrate that our proposed approach effectively reduces the demand for speech data by 90% with only slight performance degradation. To the best of our knowledge, this is the first work aiming to enhance low-resource self-supervised learning in speech processing.
6/5/2024
USAT: A Universal Speaker-Adaptive Text-to-Speech Approach
Wenbin Wang, Yang Song, Sanjay Jha
0
0
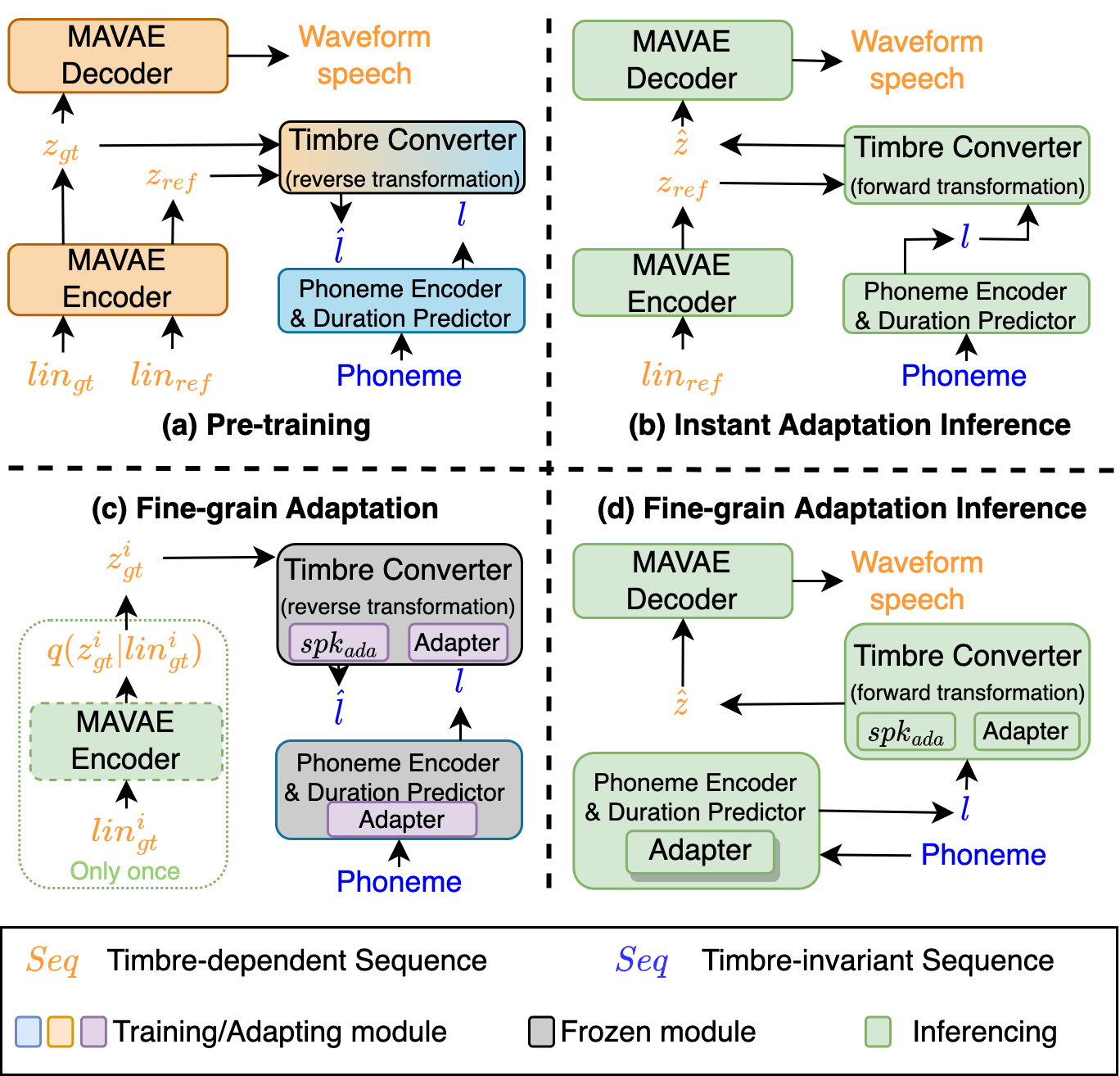
Conventional text-to-speech (TTS) research has predominantly focused on enhancing the quality of synthesized speech for speakers in the training dataset. The challenge of synthesizing lifelike speech for unseen, out-of-dataset speakers, especially those with limited reference data, remains a significant and unresolved problem. While zero-shot or few-shot speaker-adaptive TTS approaches have been explored, they have many limitations. Zero-shot approaches tend to suffer from insufficient generalization performance to reproduce the voice of speakers with heavy accents. While few-shot methods can reproduce highly varying accents, they bring a significant storage burden and the risk of overfitting and catastrophic forgetting. In addition, prior approaches only provide either zero-shot or few-shot adaptation, constraining their utility across varied real-world scenarios with different demands. Besides, most current evaluations of speaker-adaptive TTS are conducted only on datasets of native speakers, inadvertently neglecting a vast portion of non-native speakers with diverse accents. Our proposed framework unifies both zero-shot and few-shot speaker adaptation strategies, which we term as instant and fine-grained adaptations based on their merits. To alleviate the insufficient generalization performance observed in zero-shot speaker adaptation, we designed two innovative discriminators and introduced a memory mechanism for the speech decoder. To prevent catastrophic forgetting and reduce storage implications for few-shot speaker adaptation, we designed two adapters and a unique adaptation procedure.
4/30/2024
Seamless Language Expansion: Enhancing Multilingual Mastery in Self-Supervised Models
Jing Xu, Minglin Wu, Xixin Wu, Helen Meng
0
0
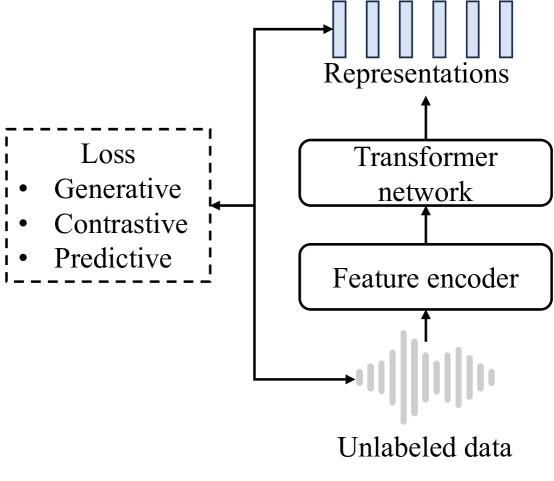
Self-supervised (SSL) models have shown great performance in various downstream tasks. However, they are typically developed for limited languages, and may encounter new languages in real-world. Developing a SSL model for each new language is costly. Thus, it is vital to figure out how to efficiently adapt existed SSL models to a new language without impairing its original abilities. We propose adaptation methods which integrate LoRA to existed SSL models to extend new language. We also develop preservation strategies which include data combination and re-clustering to retain abilities on existed languages. Applied to mHuBERT, we investigate their effectiveness on speech re-synthesis task. Experiments show that our adaptation methods enable mHuBERT to be applied to a new language (Mandarin) with MOS value increased about 1.6 and the relative value of WER reduced up to 61.72%. Also, our preservation strategies ensure that the performance on both existed and new languages remains intact.
6/21/2024