SED: Self-Evaluation Decoding Enhances Large Language Models for Better Generation
2405.16552
0
0

Abstract
Existing Large Language Models (LLMs) generate text through unidirectional autoregressive decoding methods to respond to various user queries. These methods tend to consider token selection in a simple sequential manner, making it easy to fall into suboptimal options when encountering uncertain tokens, referred to as chaotic points in our work. Many chaotic points exist in texts generated by LLMs, and they often significantly affect the quality of subsequently generated tokens, which can interfere with LLMs' generation. This paper proposes Self-Evaluation Decoding, SED, a decoding method for enhancing model generation. Analogous to the human decision-making process, SED integrates speculation and evaluation steps into the decoding process, allowing LLMs to make more careful decisions and thus optimize token selection at chaotic points. Experimental results across various tasks using different LLMs demonstrate SED's effectiveness.
Create account to get full access
Overview
- This paper introduces a novel decoding technique called "Self-Evaluation Decoding" (SED) that enhances the generation capabilities of large language models.
- SED allows language models to self-evaluate their own output during decoding, enabling them to generate higher-quality and more coherent text compared to standard decoding methods.
- The authors demonstrate the effectiveness of SED across various language generation tasks, including text summarization, open-ended dialogue, and creative writing.
Plain English Explanation
Large language models, such as GPT-3 and BERT, have become incredibly powerful at generating human-like text. However, the text they generate can sometimes lack coherence or fail to align with the intended meaning. The authors of this paper have developed a new decoding technique called "Self-Evaluation Decoding" (SED) that helps address this issue.
The key idea behind SED is to allow the language model to constantly evaluate its own output during the generation process. As the model generates each word, it also assesses how well that word fits with the overall meaning and flow of the text. This self-evaluation helps the model make more informed decisions about what to generate next, resulting in text that is more coherent and meaningful.
For example, imagine you're writing a story and you're trying to decide what the main character should say next. With a standard language model, the next line might be somewhat random or disconnected from the rest of the story. But with SED, the model would continuously assess whether the proposed line fits well with the overall narrative, allowing it to make more thoughtful and contextually appropriate choices.
The authors demonstrate the power of SED across a variety of language generation tasks, including summarizing key points, open-ended dialogue, and creative writing. They show that SED consistently outperforms standard decoding methods in terms of the quality, coherence, and meaningfulness of the generated text.
Technical Explanation
The core of the SED technique is a self-evaluation mechanism that the language model uses during the decoding process. As the model generates each token, it also computes a "self-evaluation score" that reflects how well the token fits with the overall context and meaning of the generated text so far.
This self-evaluation score is then used to guide the model's subsequent generation decisions. Tokens with higher self-evaluation scores are more likely to be selected, while those with lower scores are less likely to be chosen. This allows the model to focus on generating text that is coherent and meaningful, rather than simply the most statistically likely sequence of tokens.
The authors demonstrate the effectiveness of SED across a range of language generation tasks, including text summarization, open-ended dialogue, and creative writing. In each case, they show that SED-enhanced models outperform standard decoding approaches in terms of the quality, coherence, and meaningfulness of the generated text.
Critical Analysis
The authors provide a compelling demonstration of the benefits of SED, but there are a few potential limitations and areas for further research:
-
Computational Overhead: Incorporating the self-evaluation mechanism may add some computational overhead to the decoding process, which could impact the overall efficiency of the language model. The authors do not provide a detailed analysis of the computational cost of SED.
-
Generalizability: While the authors showcase the effectiveness of SED across a range of tasks, it would be valuable to see how the technique performs on an even broader set of language generation challenges, particularly those that may require more complex reasoning or understanding of context.
-
Interpretability: The self-evaluation mechanism is treated as a "black box" in this work, with little insight into how the model arrives at its self-assessment scores. Developing more interpretable and explainable approaches could further improve the understanding and trust in SED-enhanced language models.
Overall, this paper presents a promising new decoding technique that could significantly advance the state of the art in language generation. However, further research is needed to fully understand the limitations and potential of SED, as well as explore ways to make the technique even more robust and transparent.
Conclusion
The "Self-Evaluation Decoding" (SED) technique introduced in this paper represents a significant step forward in enhancing the generation capabilities of large language models. By allowing the model to constantly evaluate and refine its own output during the decoding process, SED enables the generation of more coherent, meaningful, and task-relevant text across a variety of applications.
As language models continue to become more powerful and widely deployed, techniques like SED will be increasingly important to ensure their outputs are aligned with user intent and societal norms. While further research is needed to fully understand the limitations and potential of SED, this work represents an important contribution to the field of natural language processing and generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Promises, Outlooks and Challenges of Diffusion Language Modeling
Justin Deschenaux, Caglar Gulcehre
0
0
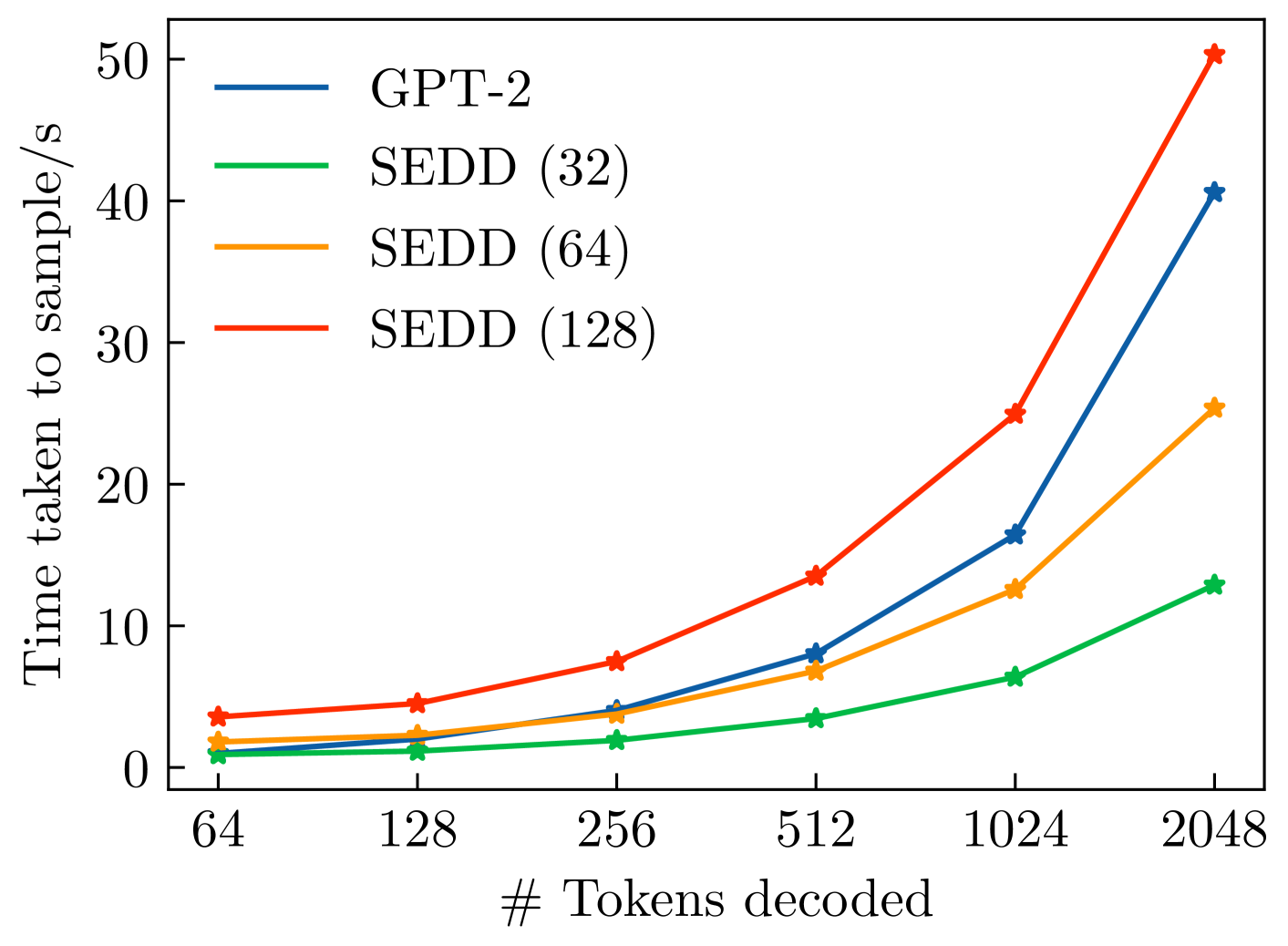
The modern autoregressive Large Language Models (LLMs) have achieved outstanding performance on NLP benchmarks, and they are deployed in the real world. However, they still suffer from limitations of the autoregressive training paradigm. For example, autoregressive token generation is notably slow and can be prone to textit{exposure bias}. The diffusion-based language models were proposed as an alternative to autoregressive generation to address some of these limitations. We evaluate the recently proposed Score Entropy Discrete Diffusion (SEDD) approach and show it is a promising alternative to autoregressive generation but it has some short-comings too. We empirically demonstrate the advantages and challenges of SEDD, and observe that SEDD generally matches autoregressive models in perplexity and on benchmarks such as HellaSwag, Arc or WinoGrande. Additionally, we show that in terms of inference latency, SEDD can be up to 4.5$times$ more efficient than GPT-2. While SEDD allows conditioning on tokens at abitrary positions, SEDD appears slightly weaker than GPT-2 for conditional generation given short prompts. Finally, we reproduced the main results from the original SEDD paper.
6/18/2024
💬
Unlocking Efficiency in Large Language Model Inference: A Comprehensive Survey of Speculative Decoding
Heming Xia, Zhe Yang, Qingxiu Dong, Peiyi Wang, Yongqi Li, Tao Ge, Tianyu Liu, Wenjie Li, Zhifang Sui
0
0
To mitigate the high inference latency stemming from autoregressive decoding in Large Language Models (LLMs), Speculative Decoding has emerged as a novel decoding paradigm for LLM inference. In each decoding step, this method first drafts several future tokens efficiently and then verifies them in parallel. Unlike autoregressive decoding, Speculative Decoding facilitates the simultaneous decoding of multiple tokens per step, thereby accelerating inference. This paper presents a comprehensive overview and analysis of this promising decoding paradigm. We begin by providing a formal definition and formulation of Speculative Decoding. Then, we organize in-depth discussions on its key facets, such as drafter selection and verification strategies. Furthermore, we present a comparative analysis of leading methods under third-party testing environments. We aim for this work to serve as a catalyst for further research on Speculative Decoding, ultimately contributing to more efficient LLM inference.
6/5/2024

Improving Open-Ended Text Generation via Adaptive Decoding
Wenhong Zhu, Hongkun Hao, Zhiwei He, Yiming Ai, Rui Wang
0
0
Current language models decode text token by token according to probabilistic distribution, and determining the appropriate candidates for the next token is crucial to ensure generation quality. This study introduces adaptive decoding, a mechanism that dynamically empowers language models to ascertain a sensible candidate set during generation. Specifically, we introduce an entropy-based metric called confidence and conceptualize determining the optimal candidate set as a confidence-increasing process. The rationality of including a token in the candidate set is assessed by leveraging the increment of confidence. Experimental results reveal that our method balances diversity and coherence well. The human evaluation shows that our method can generate human-preferred text. Additionally, our method can potentially improve the reasoning ability of language models.
6/4/2024
🛸
SEED: Accelerating Reasoning Tree Construction via Scheduled Speculative Decoding
Zhenglin Wang, Jialong Wu, Yilong Lai, Congzhi Zhang, Deyu Zhou
0
0
Large Language Models (LLMs) demonstrate remarkable emergent abilities across various tasks, yet fall short of complex reasoning and planning tasks. The tree-search-based reasoning methods address this by surpassing the capabilities of chain-of-thought prompting, encouraging exploration of intermediate steps. However, such methods introduce significant inference latency due to the systematic exploration and evaluation of multiple thought paths. This paper introduces SeeD, a novel and efficient inference framework to optimize runtime speed and GPU memory management concurrently. By employing a scheduled speculative execution, SeeD efficiently handles multiple iterations for the thought generation and the state evaluation, leveraging a rounds-scheduled strategy to manage draft model dispatching. Extensive experimental evaluations on three reasoning datasets demonstrate superior speedup performance of SeeD, providing a viable path for batched inference in training-free speculative decoding.
6/27/2024