Promises, Outlooks and Challenges of Diffusion Language Modeling
2406.11473
0
0
Abstract
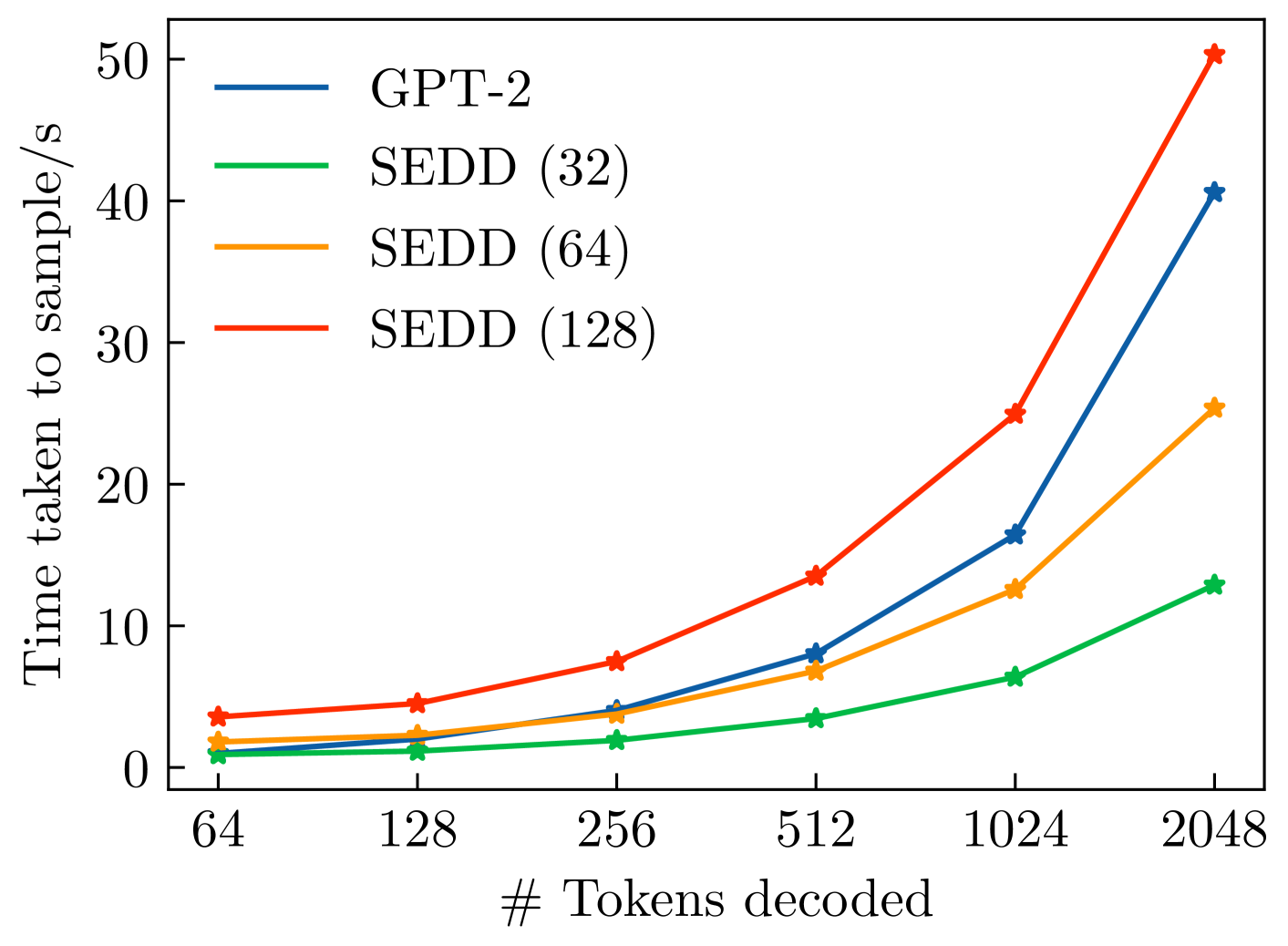
The modern autoregressive Large Language Models (LLMs) have achieved outstanding performance on NLP benchmarks, and they are deployed in the real world. However, they still suffer from limitations of the autoregressive training paradigm. For example, autoregressive token generation is notably slow and can be prone to textit{exposure bias}. The diffusion-based language models were proposed as an alternative to autoregressive generation to address some of these limitations. We evaluate the recently proposed Score Entropy Discrete Diffusion (SEDD) approach and show it is a promising alternative to autoregressive generation but it has some short-comings too. We empirically demonstrate the advantages and challenges of SEDD, and observe that SEDD generally matches autoregressive models in perplexity and on benchmarks such as HellaSwag, Arc or WinoGrande. Additionally, we show that in terms of inference latency, SEDD can be up to 4.5$times$ more efficient than GPT-2. While SEDD allows conditioning on tokens at abitrary positions, SEDD appears slightly weaker than GPT-2 for conditional generation given short prompts. Finally, we reproduced the main results from the original SEDD paper.
Create account to get full access
Overview
- This paper discusses the promises, outlooks, and challenges of diffusion language modeling, a recent approach to language modeling that has shown promising results.
- Diffusion language models work by gradually adding noise to text, then learning to reverse the process to generate new text.
- The paper explores the potential benefits of diffusion models compared to other language modeling techniques, as well as the technical challenges that need to be addressed.
Plain English Explanation
Diffusion language models are a new way of generating human-like text using computers. Instead of directly predicting the next word in a sentence, these models work by gradually adding "noise" or randomness to a piece of text, then learning how to undo that process and generate new coherent text.
This approach has some potential advantages over more traditional language models. For example, diffusion models can produce more diverse and creative text compared to models that simply predict the next word. They may also be better at handling long-range dependencies in language.
However, diffusion models also face some technical challenges. For instance, efficiently training and running these models can be computationally intensive. Researchers are exploring ways to improve the efficiency and performance of diffusion language models to make them more practical for real-world applications.
Overall, this paper provides an overview of the current state of diffusion language modeling, highlighting both the potential benefits and the technical hurdles that need to be overcome. As the field continues to evolve, diffusion models may become an increasingly important tool for natural language processing and generation.
Technical Explanation
The paper begins by introducing diffusion language models, which work by gradually adding noise to a piece of text and then learning to reverse that process to generate new coherent text. This contrasts with more traditional language models that directly predict the next word in a sequence.
The authors argue that diffusion models have several potential advantages over other approaches. For example, the noise-adding and removal process can lead to more diverse and creative text generation. Diffusion models may also be better at capturing long-range dependencies in language compared to models that focus more on local context.
However, the paper also discusses the technical challenges involved in training and deploying diffusion language models. Efficiently computing the required probability distributions can be computationally intensive, and the authors explore techniques to improve the efficiency and performance of these models.
Overall, the paper provides a comprehensive overview of the current state of diffusion language modeling, highlighting both the promises and the challenges of this emerging approach to natural language processing and generation.
Critical Analysis
The paper provides a thorough and balanced analysis of diffusion language modeling, acknowledging both the potential benefits and the technical obstacles that need to be addressed.
One area that could be explored further is the specific tradeoffs between diffusion models and other language modeling approaches. For example, while diffusion models may excel at generating diverse and creative text, it's unclear how their performance compares to other state-of-the-art models on more standard language tasks.
Additionally, the paper focuses primarily on the technical challenges of training and deploying diffusion language models, but does not delve deeply into the potential ethical or societal implications of this technology. As these models become more capable, it will be important to consider how they might be used and their potential impact on areas like misinformation, bias, and privacy.
Despite these minor limitations, the paper provides a valuable contribution to the ongoing discussion around diffusion language modeling and its role in the broader field of natural language processing.
Conclusion
This paper offers a comprehensive overview of the promises, outlooks, and challenges of diffusion language modeling, a novel approach to generating human-like text using computers. The authors highlight the potential benefits of diffusion models, such as their ability to produce more diverse and creative text, as well as the technical hurdles that need to be overcome, such as improving the computational efficiency of these models.
As the field of natural language processing continues to evolve, diffusion language models may become an increasingly important tool for a wide range of applications. However, the paper also underscores the need for further research and development to fully realize the potential of this approach, as well as the importance of considering the ethical implications of these powerful language generation systems.
Overall, this paper provides a valuable contribution to the ongoing discussion around the future of language modeling and the role of emerging techniques like diffusion modeling in shaping the next generation of natural language processing technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
Aaron Lou, Chenlin Meng, Stefano Ermon
0
0
Despite their groundbreaking performance for many generative modeling tasks, diffusion models have fallen short on discrete data domains such as natural language. Crucially, standard diffusion models rely on the well-established theory of score matching, but efforts to generalize this to discrete structures have not yielded the same empirical gains. In this work, we bridge this gap by proposing score entropy, a novel loss that naturally extends score matching to discrete spaces, integrates seamlessly to build discrete diffusion models, and significantly boosts performance. Experimentally, we test our Score Entropy Discrete Diffusion models (SEDD) on standard language modeling tasks. For comparable model sizes, SEDD beats existing language diffusion paradigms (reducing perplexity by $25$-$75$%) and is competitive with autoregressive models, in particular outperforming GPT-2. Furthermore, compared to autoregressive mdoels, SEDD generates faithful text without requiring distribution annealing techniques like temperature scaling (around $6$-$8times$ better generative perplexity than un-annealed GPT-2), can trade compute and quality (similar quality with $32times$ fewer network evaluations), and enables controllable infilling (matching nucleus sampling quality while enabling other strategies besides left to right prompting).
6/10/2024
💬
Simple and Effective Masked Diffusion Language Models
Subham Sekhar Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin T Chiu, Alexander Rush, Volodymyr Kuleshov
0
0
While diffusion models excel at generating high-quality images, prior work reports a significant performance gap between diffusion and autoregressive (AR) methods in language modeling. In this work, we show that simple masked discrete diffusion is more performant than previously thought. We apply an effective training recipe that improves the performance of masked diffusion models and derive a simplified, Rao-Blackwellized objective that results in additional improvements. Our objective has a simple form -- it is a mixture of classical masked language modeling losses -- and can be used to train encoder-only language models that admit efficient samplers, including ones that can generate arbitrary lengths of text semi-autoregressively like a traditional language model. On language modeling benchmarks, a range of masked diffusion models trained with modern engineering practices achieves a new state-of-the-art among diffusion models, and approaches AR perplexity. We release our code at: https://github.com/kuleshov-group/mdlm
6/12/2024

SED: Self-Evaluation Decoding Enhances Large Language Models for Better Generation
Ziqin Luo, Haixia Han, Haokun Zhao, Guochao Jiang, Chengyu Du, Tingyun Li, Jiaqing Liang, Deqing Yang, Yanghua Xiao
0
0
Existing Large Language Models (LLMs) generate text through unidirectional autoregressive decoding methods to respond to various user queries. These methods tend to consider token selection in a simple sequential manner, making it easy to fall into suboptimal options when encountering uncertain tokens, referred to as chaotic points in our work. Many chaotic points exist in texts generated by LLMs, and they often significantly affect the quality of subsequently generated tokens, which can interfere with LLMs' generation. This paper proposes Self-Evaluation Decoding, SED, a decoding method for enhancing model generation. Analogous to the human decision-making process, SED integrates speculation and evaluation steps into the decoding process, allowing LLMs to make more careful decisions and thus optimize token selection at chaotic points. Experimental results across various tasks using different LLMs demonstrate SED's effectiveness.
5/28/2024
📈
Boosting Diffusion Model for Spectrogram Up-sampling in Text-to-speech: An Empirical Study
Chong Zhang, Yanqing Liu, Yang Zheng, Sheng Zhao
0
0
Scaling text-to-speech (TTS) with autoregressive language model (LM) to large-scale datasets by quantizing waveform into discrete speech tokens is making great progress to capture the diversity and expressiveness in human speech, but the speech reconstruction quality from discrete speech token is far from satisfaction depending on the compressed speech token compression ratio. Generative diffusion models trained with score-matching loss and continuous normalized flow trained with flow-matching loss have become prominent in generation of images as well as speech. LM based TTS systems usually quantize speech into discrete tokens and generate these tokens autoregressively, and finally use a diffusion model to up sample coarse-grained speech tokens into fine-grained codec features or mel-spectrograms before reconstructing into waveforms with vocoder, which has a high latency and is not realistic for real time speech applications. In this paper, we systematically investigate varied diffusion models for up sampling stage, which is the main bottleneck for streaming synthesis of LM and diffusion-based architecture, we present the model architecture, objective and subjective metrics to show quality and efficiency improvement.
6/10/2024