Mind's Mirror: Distilling Self-Evaluation Capability and Comprehensive Thinking from Large Language Models
2311.09214
0
0
💬
Abstract
Large language models (LLMs) have achieved remarkable advancements in natural language processing. However, the massive scale and computational demands of these models present formidable challenges when considering their practical deployment in resource-constrained environments. While techniques such as chain-of-thought (CoT) distillation have displayed promise in distilling LLMs into small language models (SLMs), there is a risk that distilled SLMs may still inherit flawed reasoning and hallucinations from LLMs. To address these issues, we propose a twofold methodology: First, we introduce a novel method for distilling the self-evaluation capability from LLMs into SLMs, aiming to mitigate the adverse effects of flawed reasoning and hallucinations inherited from LLMs. Second, we advocate for distilling more comprehensive thinking by incorporating multiple distinct CoTs and self-evaluation outputs, to ensure a more thorough and robust knowledge transfer into SLMs. Experiments on three NLP benchmarks demonstrate that our method significantly improves the performance of distilled SLMs, offering a new perspective for developing more effective and efficient SLMs in resource-constrained environments.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Large language models (LLMs) have made significant advancements in natural language processing, but their massive scale and computational demands present challenges for practical deployment in resource-constrained environments.
- Techniques like chain-of-thought (CoT) distillation have shown promise in distilling LLMs into smaller language models (SLMs), but there is a risk that the distilled SLMs may inherit flawed reasoning and hallucinations from the LLMs.
- To address these issues, the researchers propose a two-part methodology: 1) Distilling the self-evaluation capability from LLMs into SLMs to mitigate the effects of flawed reasoning and hallucinations, and 2) Distilling more comprehensive thinking by incorporating multiple distinct CoTs and self-evaluation outputs.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. However, these models are often too big and complex to be easily deployed in real-world situations, especially where computing resources are limited.
The researchers wanted to find a way to take the knowledge and capabilities of these large models and "distill" them into smaller, more efficient language models (SLMs) that could be used in resource-constrained environments. This is like taking a large, complicated recipe and boiling it down into a simpler, easier-to-use version.
One challenge they identified is that the distilled SLMs might still inherit problems from the original LLMs, such as flawed reasoning or making up information (hallucinations). To address this, the researchers came up with two key ideas:
- Distill the LLM's ability to self-evaluate its own reasoning and outputs into the SLM. This helps the smaller model catch and correct its own mistakes.
- Distill multiple "chains of thought" (different ways of reasoning through a problem) and self-evaluation outputs into the SLM. This helps the smaller model develop more thorough and reliable knowledge.
By implementing these ideas, the researchers found that the distilled SLMs performed significantly better on various natural language processing tasks compared to SLMs created using other distillation methods. This suggests their approach could be a valuable way to create smaller, more efficient language models that can be used in real-world applications without sacrificing too much performance.
Technical Explanation
The researchers propose a two-part methodology to address the challenges of distilling large language models (LLMs) into smaller language models (SLMs) while mitigating the inherited flaws of the original LLMs.
First, they introduce a novel method for distilling the self-evaluation capability from LLMs into SLMs. This self-evaluation ability allows the distilled SLMs to better detect and correct flawed reasoning and hallucinations that may have been inherited from the original LLMs.
Second, the researchers advocate for distilling more comprehensive thinking into the SLMs by incorporating multiple distinct chain-of-thought (CoT) outputs and self-evaluation results. This ensures a more thorough and robust knowledge transfer from the LLMs to the SLMs.
To evaluate their approach, the researchers conducted experiments on three natural language processing (NLP) benchmarks. The results demonstrate that their method significantly improves the performance of the distilled SLMs compared to SLMs created using other distillation techniques. This offers a new perspective for developing more effective and efficient SLMs that can be deployed in resource-constrained environments.
Critical Analysis
The researchers' approach to distilling self-evaluation capabilities and multiple CoTs into SLMs is a promising step towards addressing the challenges of flawed reasoning and hallucinations that can be inherited from LLMs. By equipping the distilled SLMs with the ability to self-evaluate and draw from diverse reasoning paths, the researchers have taken an important step in enhancing the reliability and robustness of smaller language models.
However, the paper does not fully explore the potential limitations of this approach. For example, it is unclear how the distilled SLMs would perform in more complex, multi-agent coordination tasks or in general agent capabilities beyond the specific NLP benchmarks tested. Additionally, the paper does not address potential scalability issues as the number of distinct CoTs and self-evaluation outputs increases.
Further research is needed to fully understand the capabilities and limitations of this approach, as well as its applicability to a wider range of real-world scenarios. Nonetheless, the researchers have made a valuable contribution to the field of efficient and reliable language model development.
Conclusion
The researchers have proposed a novel approach to distilling large language models (LLMs) into smaller language models (SLMs) that can be more effectively deployed in resource-constrained environments. By distilling the self-evaluation capability and multiple distinct chains of thought from the LLMs into the SLMs, the researchers have found a way to mitigate the adverse effects of flawed reasoning and hallucinations that can be inherited from the original large models.
The promising results demonstrated on NLP benchmarks suggest that this methodology could be a significant step towards developing more reliable and efficient small language models that can be used in a variety of practical applications. As the field of natural language processing continues to advance, this research offers a valuable perspective on how to harness the power of large language models while overcoming their limitations.
Related Papers

When Hindsight is Not 20/20: Testing Limits on Reflective Thinking in Large Language Models
Yanhong Li, Chenghao Yang, Allyson Ettinger
0
0
Recent studies suggest that self-reflective prompting can significantly enhance the reasoning capabilities of Large Language Models (LLMs). However, the use of external feedback as a stop criterion raises doubts about the true extent of LLMs' ability to emulate human-like self-reflection. In this paper, we set out to clarify these capabilities under a more stringent evaluation setting in which we disallow any kind of external feedback. Our findings under this setting show a split: while self-reflection enhances performance in TruthfulQA, it adversely affects results in HotpotQA. We conduct follow-up analyses to clarify the contributing factors in these patterns, and find that the influence of self-reflection is impacted both by reliability of accuracy in models' initial responses, and by overall question difficulty: specifically, self-reflection shows the most benefit when models are less likely to be correct initially, and when overall question difficulty is higher. We also find that self-reflection reduces tendency toward majority voting. Based on our findings, we propose guidelines for decisions on when to implement self-reflection. We release the codebase for reproducing our experiments at https://github.com/yanhong-lbh/LLM-SelfReflection-Eval.
4/16/2024
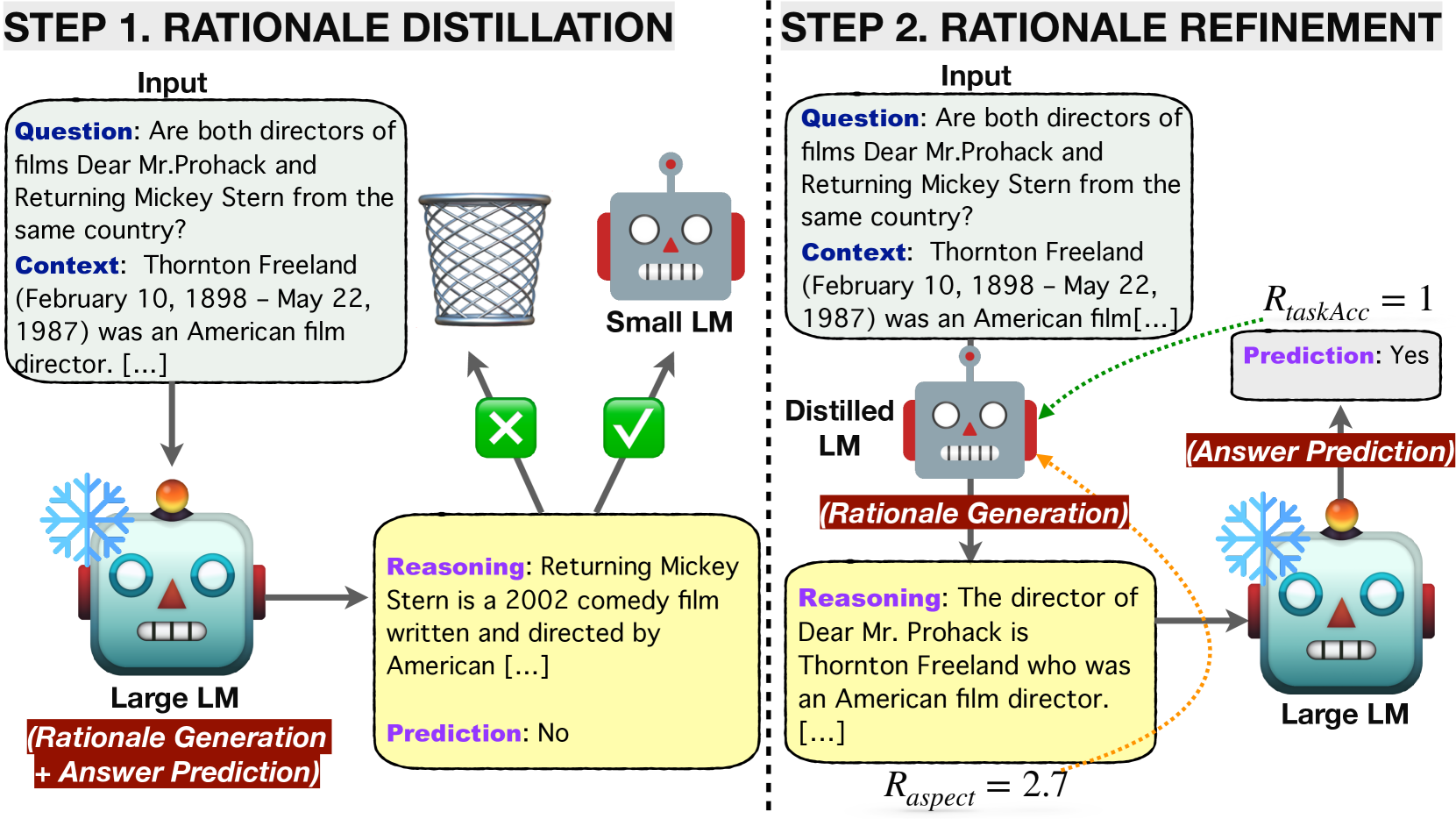
Can Small Language Models Help Large Language Models Reason Better?: LM-Guided Chain-of-Thought
Jooyoung Lee, Fan Yang, Thanh Tran, Qian Hu, Emre Barut, Kai-Wei Chang, Chengwei Su
0
0
We introduce a novel framework, LM-Guided CoT, that leverages a lightweight (i.e., 10B) LM in reasoning tasks. Specifically, the lightweight LM first generates a rationale for each input instance. The Frozen large LM is then prompted to predict a task output based on the rationale generated by the lightweight LM. Our approach is resource-efficient in the sense that it only requires training the lightweight LM. We optimize the model through 1) knowledge distillation and 2) reinforcement learning from rationale-oriented and task-oriented reward signals. We assess our method with multi-hop extractive question answering (QA) benchmarks, HotpotQA, and 2WikiMultiHopQA. Experimental results show that our approach outperforms all baselines regarding answer prediction accuracy. We also find that reinforcement learning helps the model to produce higher-quality rationales with improved QA performance.
4/5/2024
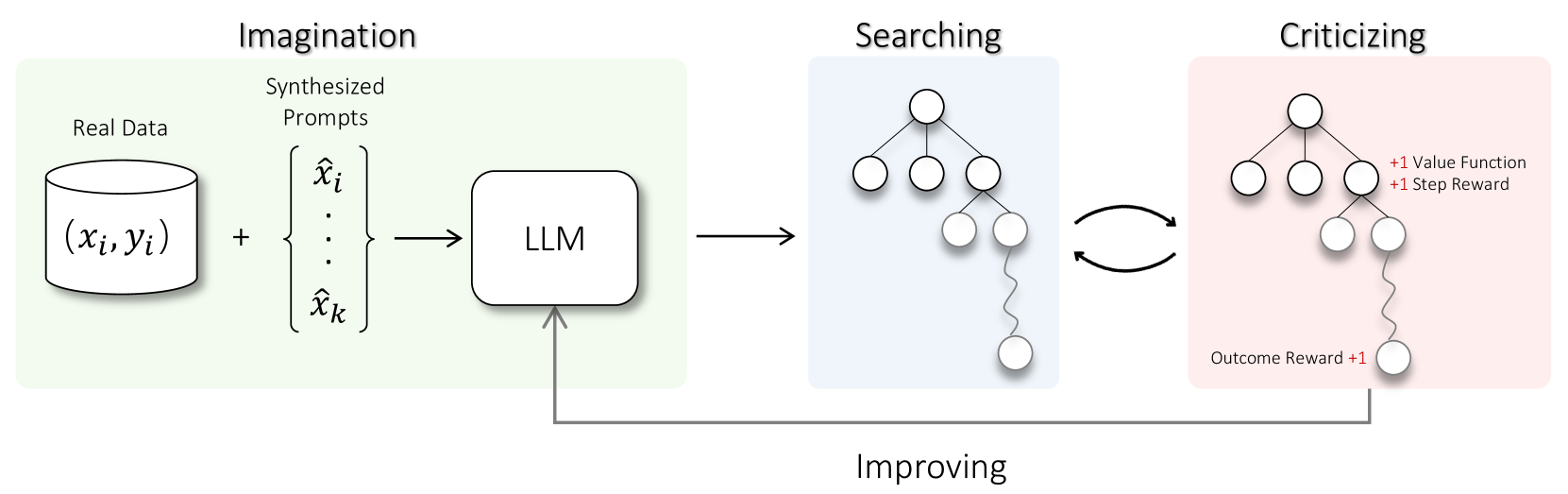
Toward Self-Improvement of LLMs via Imagination, Searching, and Criticizing
Ye Tian, Baolin Peng, Linfeng Song, Lifeng Jin, Dian Yu, Haitao Mi, Dong Yu
0
0
Despite the impressive capabilities of Large Language Models (LLMs) on various tasks, they still struggle with scenarios that involves complex reasoning and planning. Recent work proposed advanced prompting techniques and the necessity of fine-tuning with high-quality data to augment LLMs' reasoning abilities. However, these approaches are inherently constrained by data availability and quality. In light of this, self-correction and self-learning emerge as viable solutions, employing strategies that allow LLMs to refine their outputs and learn from self-assessed rewards. Yet, the efficacy of LLMs in self-refining its response, particularly in complex reasoning and planning task, remains dubious. In this paper, we introduce AlphaLLM for the self-improvements of LLMs, which integrates Monte Carlo Tree Search (MCTS) with LLMs to establish a self-improving loop, thereby enhancing the capabilities of LLMs without additional annotations. Drawing inspiration from the success of AlphaGo, AlphaLLM addresses the unique challenges of combining MCTS with LLM for self-improvement, including data scarcity, the vastness search spaces of language tasks, and the subjective nature of feedback in language tasks. AlphaLLM is comprised of prompt synthesis component, an efficient MCTS approach tailored for language tasks, and a trio of critic models for precise feedback. Our experimental results in mathematical reasoning tasks demonstrate that AlphaLLM significantly enhances the performance of LLMs without additional annotations, showing the potential for self-improvement in LLMs.
4/19/2024
💬
Evaluating the Deductive Competence of Large Language Models
Spencer M. Seals, Valerie L. Shalin
0
0
The development of highly fluent large language models (LLMs) has prompted increased interest in assessing their reasoning and problem-solving capabilities. We investigate whether several LLMs can solve a classic type of deductive reasoning problem from the cognitive science literature. The tested LLMs have limited abilities to solve these problems in their conventional form. We performed follow up experiments to investigate if changes to the presentation format and content improve model performance. We do find performance differences between conditions; however, they do not improve overall performance. Moreover, we find that performance interacts with presentation format and content in unexpected ways that differ from human performance. Overall, our results suggest that LLMs have unique reasoning biases that are only partially predicted from human reasoning performance and the human-generated language corpora that informs them.
4/16/2024