See or Guess: Counterfactually Regularized Image Captioning

0

Sign in to get full access
Overview
- Examines the problem of "object hallucination" in image captioning models
- Proposes a counterfactually regularized approach to address this issue
- Focuses on improving the reliability and faithfulness of image captions
Plain English Explanation
Image captioning models are designed to generate textual descriptions of images. However, these models can sometimes "hallucinate" objects or details that are not actually present in the image. This can lead to inaccurate or misleading captions.
The researchers behind this paper developed a new approach to address this problem. Their method, called "counterfactually regularized image captioning," aims to make the captions generated by the model more faithful to the actual contents of the image.
The key idea is to use counterfactual reasoning, which involves considering what would happen if certain conditions were different. In this case, the model is trained to not only generate captions based on the given image, but also to predict what the caption would be if certain objects or details were removed from the image.
By incorporating this counterfactual perspective, the model becomes more aware of which elements in the image are actually important for the caption, and is less likely to hallucinate objects or details that are not there.
Technical Explanation
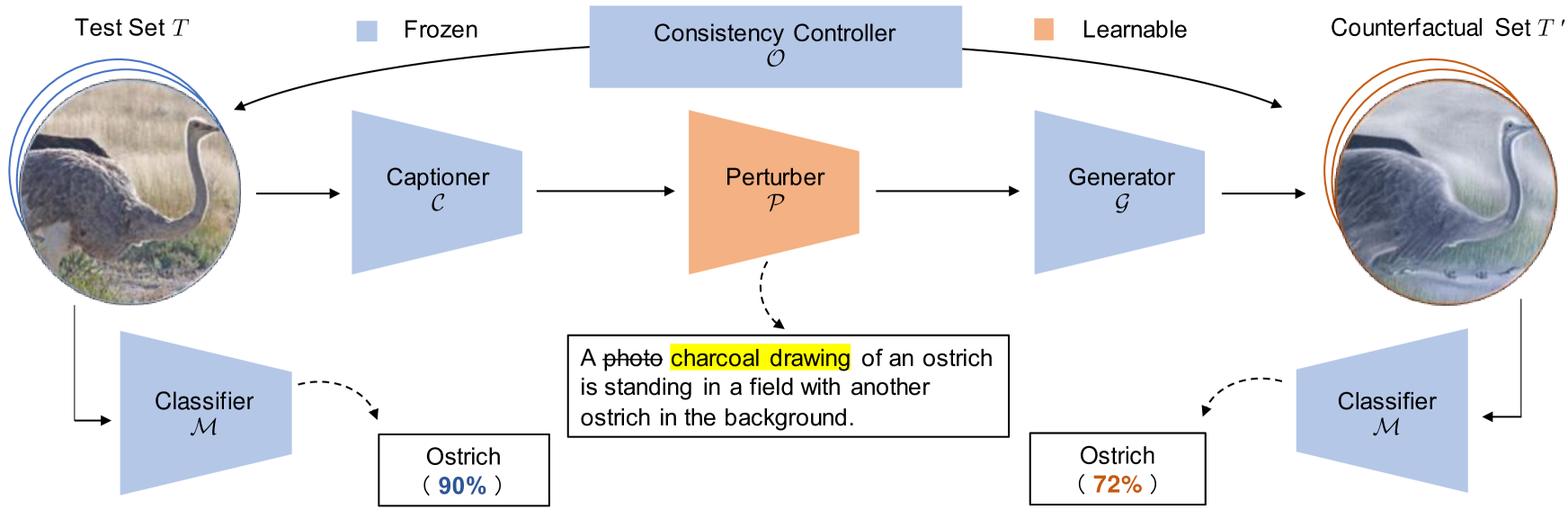
The researchers propose a novel image captioning framework that incorporates counterfactual reasoning to address the problem of object hallucination. Their approach, called See or Guess, consists of two key components:
-
Counterfactual Caption Prediction: The model is trained not only to generate captions based on the given image, but also to predict what the caption would be if certain objects or details were removed from the image. This counterfactual perspective helps the model better understand which elements in the image are truly important for the caption.
-
Counterfactual Regularization: The model is trained to minimize the difference between the captions generated for the original image and the counterfactual versions. This encourages the model to focus on the relevant details in the image and avoid hallucinating objects or details that are not actually present.
The researchers evaluate their approach on several benchmark image captioning datasets and find that it outperforms various state-of-the-art methods in terms of caption accuracy and faithfulness to the image content.
Critical Analysis
The researchers acknowledge that their approach has some limitations. For example, the counterfactual caption prediction process can be computationally expensive, as it requires generating multiple captions for each image.
Additionally, the researchers note that their method may not be as effective in scenarios where the image contains many salient objects, as the model may still struggle to determine which elements are truly essential for the caption.
Further research could explore ways to make the counterfactual caption prediction process more efficient, or to incorporate additional cues or constraints to help the model better distinguish between important and irrelevant image elements.
Conclusion
The "See or Guess" approach proposed in this paper represents an important step forward in improving the reliability and faithfulness of image captioning models. By incorporating counterfactual reasoning, the model becomes better able to distinguish between what it actually sees in the image and what it might be tempted to "guess" or hallucinate.
This work has implications for a wide range of applications that rely on image captioning, such as assistive technologies, visual search, and image-based content moderation. By reducing the risk of object hallucination, the proposed approach can help ensure that the textual descriptions generated by these systems are more accurate and trustworthy.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
See or Guess: Counterfactually Regularized Image Captioning
Qian Cao, Xu Chen, Ruihua Song, Xiting Wang, Xinting Huang, Yuchen Ren
Image captioning, which generates natural language descriptions of the visual information in an image, is a crucial task in vision-language research. Previous models have typically addressed this task by aligning the generative capabilities of machines with human intelligence through statistical fitting of existing datasets. While effective for normal images, they may struggle to accurately describe those where certain parts of the image are obscured or edited, unlike humans who excel in such cases. These weaknesses they exhibit, including hallucinations and limited interpretability, often hinder performance in scenarios with shifted association patterns. In this paper, we present a generic image captioning framework that employs causal inference to make existing models more capable of interventional tasks, and counterfactually explainable. Our approach includes two variants leveraging either total effect or natural direct effect. Integrating them into the training process enables models to handle counterfactual scenarios, increasing their generalizability. Extensive experiments on various datasets show that our method effectively reduces hallucinations and improves the model's faithfulness to images, demonstrating high portability across both small-scale and large-scale image-to-text models. The code is available at https://github.com/Aman-4-Real/See-or-Guess.
Read more9/2/2024
0
Reinforcing Pre-trained Models Using Counterfactual Images
Xiang Li, Ren Togo, Keisuke Maeda, Takahiro Ogawa, Miki Haseyama
This paper proposes a novel framework to reinforce classification models using language-guided generated counterfactual images. Deep learning classification models are often trained using datasets that mirror real-world scenarios. In this training process, because learning is based solely on correlations with labels, there is a risk that models may learn spurious relationships, such as an overreliance on features not central to the subject, like background elements in images. However, due to the black-box nature of the decision-making process in deep learning models, identifying and addressing these vulnerabilities has been particularly challenging. We introduce a novel framework for reinforcing the classification models, which consists of a two-stage process. First, we identify model weaknesses by testing the model using the counterfactual image dataset, which is generated by perturbed image captions. Subsequently, we employ the counterfactual images as an augmented dataset to fine-tune and reinforce the classification model. Through extensive experiments on several classification models across various datasets, we revealed that fine-tuning with a small set of counterfactual images effectively strengthens the model.
Read more6/21/2024

0
CounterCurate: Enhancing Physical and Semantic Visio-Linguistic Compositional Reasoning via Counterfactual Examples
Jianrui Zhang, Mu Cai, Tengyang Xie, Yong Jae Lee
We propose CounterCurate, a framework to comprehensively improve the visio-linguistic compositional reasoning capability for both contrastive and generative multimodal models. In particular, we identify two critical under-explored problems: the neglect of the physically grounded reasoning (counting and position understanding) and the potential of using highly capable text and image generation models for semantic counterfactual fine-tuning. Our work pioneers an approach that addresses these gaps. We first spotlight the near-chance performance of multimodal models like CLIP and LLaVA in physically grounded compositional reasoning. We then apply simple data augmentation using grounded image generation model GLIGEN to generate fine-tuning data, resulting in significant performance improvements: +33% and +37% for CLIP and LLaVA, respectively, on our newly curated Flickr30k-Positions benchmark. Moreover, we exploit the capabilities of high-performing text generation and image generation models, specifically GPT-4V and DALLE-3, to curate challenging semantic counterfactuals, thereby further enhancing compositional reasoning capabilities on benchmarks such as SugarCrepe, where CounterCurate outperforms GPT-4V. To facilitate future research, we release our code, dataset, benchmark, and checkpoints at https://countercurate.github.io.
Read more6/13/2024
0
Improving face generation quality and prompt following with synthetic captions
Michail Tarasiou, Stylianos Moschoglou, Jiankang Deng, Stefanos Zafeiriou
Recent advancements in text-to-image generation using diffusion models have significantly improved the quality of generated images and expanded the ability to depict a wide range of objects. However, ensuring that these models adhere closely to the text prompts remains a considerable challenge. This issue is particularly pronounced when trying to generate photorealistic images of humans. Without significant prompt engineering efforts models often produce unrealistic images and typically fail to incorporate the full extent of the prompt information. This limitation can be largely attributed to the nature of captions accompanying the images used in training large scale diffusion models, which typically prioritize contextual information over details related to the person's appearance. In this paper we address this issue by introducing a training-free pipeline designed to generate accurate appearance descriptions from images of people. We apply this method to create approximately 250,000 captions for publicly available face datasets. We then use these synthetic captions to fine-tune a text-to-image diffusion model. Our results demonstrate that this approach significantly improves the model's ability to generate high-quality, realistic human faces and enhances adherence to the given prompts, compared to the baseline model. We share our synthetic captions, pretrained checkpoints and training code.
Read more5/20/2024