SEFraud: Graph-based Self-Explainable Fraud Detection via Interpretative Mask Learning

0

Sign in to get full access
Overview
• This paper presents SEFraud, a graph-based self-explainable fraud detection model that uses interpretative mask learning to provide explanations for its predictions.
• The key ideas are: 1) leveraging graph neural networks to capture the complex relationships between entities in fraud data, 2) learning an interpretative mask to highlight the most important factors contributing to the fraud detection, and 3) providing self-explanations for the model's decisions.
Plain English Explanation
Fraud detection is an important problem, especially in areas like banking and e-commerce. Detecting fraud can be challenging because fraudsters often try to hide their activities by creating complex networks of transactions and accounts. Traditional fraud detection models may struggle to capture these intricate relationships.
The researchers developed SEFraud, a new approach that uses graph neural networks to analyze the connections between entities in the fraud data. Graph neural networks are a type of machine learning model that can learn patterns from data organized as a graph, where the nodes represent entities and the edges represent the relationships between them.
In addition to detecting fraud, SEFraud also aims to explain its decisions. It learns an "interpretative mask" that highlights the most important factors contributing to its fraud predictions. This allows SEFraud to provide self-explanations for why it classified a particular transaction or account as fraudulent. [Link to RagFormer: Learning Semantic Attributes & Topological Structure for Fraud]
Providing explanations is important because it helps build trust in the model and allows users to understand the reasoning behind its decisions. This can be particularly useful in sensitive domains like finance, where transparency and accountability are crucial. [Link to X-CBA: Explainability-Aided CatBoost-Based Anomaly Detection]
Technical Explanation
The SEFraud model consists of two main components: a graph neural network for fraud detection and an interpretative mask learning module for generating explanations.
The graph neural network takes the fraud data, represented as a graph, and learns to detect fraudulent patterns by aggregating information from the neighboring nodes and edges. This allows the model to capture the complex relationships between entities that may be indicative of fraud. [Link to Credit Card Fraud Detection using Advanced Transformer]
The interpretative mask learning module then learns a set of masks that highlight the most important features and graph structures contributing to the fraud detection. These masks are used to provide self-explanations for the model's predictions, helping users understand the reasoning behind the fraud classifications. [Link to Graph Neural Network Explanations are Fragile]
The researchers evaluated SEFraud on several real-world fraud datasets and found that it outperformed baseline methods in terms of fraud detection performance while also providing meaningful explanations for its decisions. [Link to Explainable Malware Detection with Tailored Logic-Explained Networks]
Critical Analysis
The paper presents a novel and promising approach to fraud detection that leverages the power of graph neural networks and interpretability. The authors' focus on providing self-explanations is particularly valuable, as it can help build trust in the model and allow for more informed decision-making.
However, the paper does not fully address the potential fragility of the explanations generated by the interpretative mask learning module. Graph neural networks have been shown to be sensitive to small changes in the input graph structure, and the explanations generated by SEFraud may be similarly vulnerable. [Link to Graph Neural Network Explanations are Fragile]
Additionally, the paper does not explore the potential biases that may be introduced by the graph structure or the training data used for SEFraud. Fraud data can often reflect societal biases, and it's important to ensure that the model does not perpetuate or amplify these biases in its predictions and explanations.
Conclusion
SEFraud represents an important step forward in the field of graph-based fraud detection, demonstrating the potential of combining powerful graph neural networks with interpretability features. By providing self-explanations for its decisions, SEFraud can help build trust and enable more informed decision-making in fraud-sensitive domains.
However, the research community should continue to explore the limitations and potential biases of such models, as well as ways to further improve their robustness and transparency. Ongoing efforts in this direction will be crucial for developing fraud detection systems that are not only effective, but also fair and trustworthy.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SEFraud: Graph-based Self-Explainable Fraud Detection via Interpretative Mask Learning
Kaidi Li, Tianmeng Yang, Min Zhou, Jiahao Meng, Shendi Wang, Yihui Wu, Boshuai Tan, Hu Song, Lujia Pan, Fan Yu, Zhenli Sheng, Yunhai Tong
Graph-based fraud detection has widespread application in modern industry scenarios, such as spam review and malicious account detection. While considerable efforts have been devoted to designing adequate fraud detectors, the interpretability of their results has often been overlooked. Previous works have attempted to generate explanations for specific instances using post-hoc explaining methods such as a GNNExplainer. However, post-hoc explanations can not facilitate the model predictions and the computational cost of these methods cannot meet practical requirements, thus limiting their application in real-world scenarios. To address these issues, we propose SEFraud, a novel graph-based self-explainable fraud detection framework that simultaneously tackles fraud detection and result in interpretability. Concretely, SEFraud first leverages customized heterogeneous graph transformer networks with learnable feature masks and edge masks to learn expressive representations from the informative heterogeneously typed transactions. A new triplet loss is further designed to enhance the performance of mask learning. Empirical results on various datasets demonstrate the effectiveness of SEFraud as it shows considerable advantages in both the fraud detection performance and interpretability of prediction results. Moreover, SEFraud has been deployed and offers explainable fraud detection service for the largest bank in China, Industrial and Commercial Bank of China Limited (ICBC). Results collected from the production environment of ICBC show that SEFraud can provide accurate detection results and comprehensive explanations that align with the expert business understanding, confirming its efficiency and applicability in large-scale online services.
Read more6/18/2024

0
GraphGuard: Contrastive Self-Supervised Learning for Credit-Card Fraud Detection in Multi-Relational Dynamic Graphs
Krist'ofer Reynisson, Marco Schreyer, Damian Borth
Credit card fraud has significant implications at both an individual and societal level, making effective prevention essential. Current methods rely heavily on feature engineering and labeled information, both of which have significant limitations. In this work, we present GraphGuard, a novel contrastive self-supervised graph-based framework for detecting fraudulent credit card transactions. We conduct experiments on a real-world dataset and a synthetic dataset. Our results provide a promising initial direction for exploring the effectiveness of graph-based self-supervised approaches for credit card fraud detection.
Read more7/18/2024
0
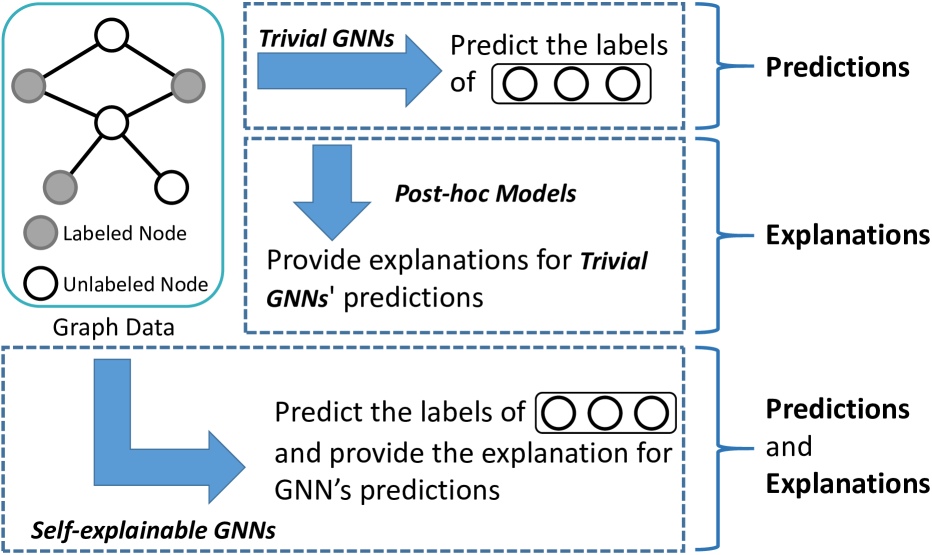
SES: Bridging the Gap Between Explainability and Prediction of Graph Neural Networks
Zhenhua Huang, Kunhao Li, Shaojie Wang, Zhaohong Jia, Wentao Zhu, Sharad Mehrotra
Despite the Graph Neural Networks' (GNNs) proficiency in analyzing graph data, achieving high-accuracy and interpretable predictions remains challenging. Existing GNN interpreters typically provide post-hoc explanations disjointed from GNNs' predictions, resulting in misrepresentations. Self-explainable GNNs offer built-in explanations during the training process. However, they cannot exploit the explanatory outcomes to augment prediction performance, and they fail to provide high-quality explanations of node features and require additional processes to generate explainable subgraphs, which is costly. To address the aforementioned limitations, we propose a self-explained and self-supervised graph neural network (SES) to bridge the gap between explainability and prediction. SES comprises two processes: explainable training and enhanced predictive learning. During explainable training, SES employs a global mask generator co-trained with a graph encoder and directly produces crucial structure and feature masks, reducing time consumption and providing node feature and subgraph explanations. In the enhanced predictive learning phase, mask-based positive-negative pairs are constructed utilizing the explanations to compute a triplet loss and enhance the node representations by contrastive learning.
Read more7/26/2024

0
SE-SGformer: A Self-Explainable Signed Graph Transformer for Link Sign Prediction
Lu Li, Jiale Liu, Xingyu Ji, Maojun Wang, Zeyu Zhang
Signed Graph Neural Networks (SGNNs) have been shown to be effective in analyzing complex patterns in real-world situations where positive and negative links coexist. However, SGNN models suffer from poor explainability, which limit their adoptions in critical scenarios that require understanding the rationale behind predictions. To the best of our knowledge, there is currently no research work on the explainability of the SGNN models. Our goal is to address the explainability of decision-making for the downstream task of link sign prediction specific to signed graph neural networks. Since post-hoc explanations are not derived directly from the models, they may be biased and misrepresent the true explanations. Therefore, in this paper we introduce a Self-Explainable Signed Graph transformer (SE-SGformer) framework, which can not only outputs explainable information while ensuring high prediction accuracy. Specifically, We propose a new Transformer architecture for signed graphs and theoretically demonstrate that using positional encoding based on signed random walks has greater expressive power than current SGNN methods and other positional encoding graph Transformer-based approaches. We constructs a novel explainable decision process by discovering the $K$-nearest (farthest) positive (negative) neighbors of a node to replace the neural network-based decoder for predicting edge signs. These $K$ positive (negative) neighbors represent crucial information about the formation of positive (negative) edges between nodes and thus can serve as important explanatory information in the decision-making process. We conducted experiments on several real-world datasets to validate the effectiveness of SE-SGformer, which outperforms the state-of-the-art methods by improving 2.2% prediction accuracy and 73.1% explainablity accuracy in the best-case scenario.
Read more8/19/2024