Segment Any Text: A Universal Approach for Robust, Efficient and Adaptable Sentence Segmentation

0
Sign in to get full access
Overview
- Presents a novel approach for robust, efficient, and adaptable sentence segmentation that can handle a wide range of text types
- Introduces a universal model that outperforms existing state-of-the-art methods across multiple datasets and languages
- Demonstrates the model's ability to handle challenging cases, such as noisy or informal text, with high accuracy
Plain English Explanation
The paper describes a new way to automatically break up text into individual sentences, which is an important task for many language processing applications. Lightweight Audio Segmentation for Long-Form Speech Translation and Using Contextual Information for Sentence-Level Morpheme Segmentation are examples of other research in this area. The approach presented in this paper is designed to work well on a wide variety of text types, from formal writing to informal online discussions, without requiring extensive customization.
The key innovation is a universal model that can adapt to different styles of text. Rather than building separate models for different domains, the researchers developed a single model that can handle diverse inputs. This makes the system more robust and efficient, as it doesn't require retraining or fine-tuning for each new application. The model also outperforms current state-of-the-art methods, which is important for practical use cases like Automating Easy-Read Text Segmentation and Scaling Up Multi-Domain Semantic Segmentation at the Sentence Level.
Technical Explanation
The paper introduces a novel neural network architecture for sentence segmentation that leverages both local and global context. The model, called "Segment Any Text" (SAT), consists of a transformer-based encoder that captures long-range dependencies, followed by a sequence labeling layer that predicts whether each token is the start of a new sentence.
The key innovation is the use of a unified model that can handle a wide range of text types without requiring domain-specific fine-tuning. This is achieved through several techniques:
- Flexible Input Representation: The model accepts various input formats, including raw text, tokenized text, or text with additional features (e.g., part-of-speech tags).
- Multi-Task Learning: The model is trained on multiple sentence segmentation datasets simultaneously, allowing it to learn a more general, adaptable representation.
- Self-Supervised Pre-training: The model is first pre-trained on a large, diverse corpus of text using self-supervised objectives, such as masked language modeling. This provides a strong initial representation that can be fine-tuned for the sentence segmentation task.
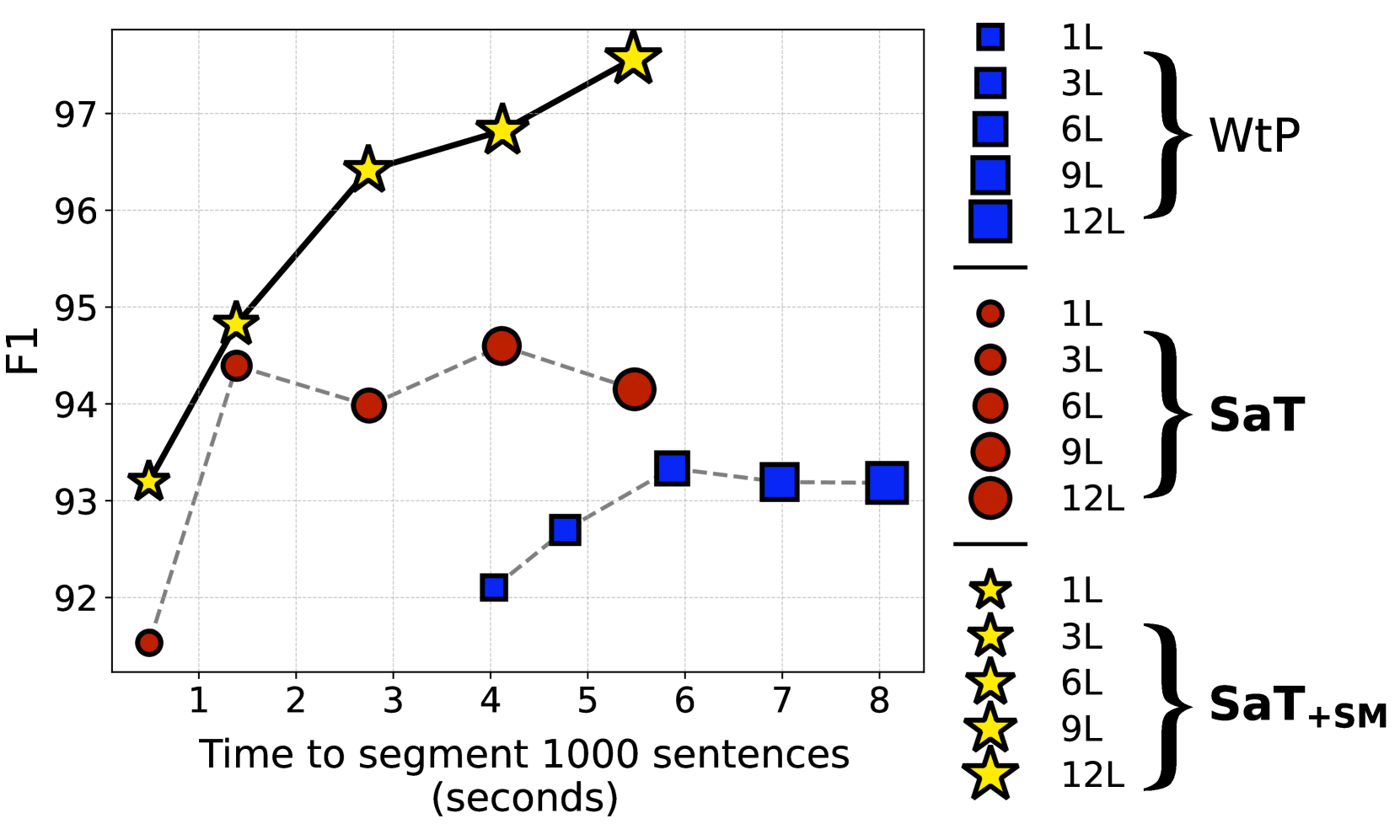
The researchers evaluate the SAT model on several benchmark datasets, including formal written text, informal social media posts, and noisy user-generated content. They demonstrate that the universal SAT model outperforms existing state-of-the-art methods, while also being more efficient and requiring less domain-specific tuning.
Critical Analysis
The paper presents a compelling approach to the problem of sentence segmentation, with several key strengths:
- Robustness and Adaptability: The ability to handle diverse text types without extensive fine-tuning is a significant advantage over existing methods, which often struggle with domain shifts.
- Efficiency and Scalability: The use of a single universal model, rather than multiple specialized models, makes the system more efficient and easier to deploy at scale.
- Strong Empirical Results: The SAT model demonstrates state-of-the-art performance across multiple benchmark datasets, suggesting the approach is truly effective.
However, the paper also acknowledges some limitations and areas for future research:
- Interpretability: The transformer-based architecture used in the SAT model is relatively complex, making it difficult to interpret the model's decision-making process. Improving the interpretability of the model could be valuable for certain applications.
- Resource-Constrained Environments: While the universal model is efficient compared to domain-specific approaches, the paper does not explore the performance of the SAT model in resource-constrained environments, such as on mobile devices or embedded systems.
- Multilingual Capabilities: The paper focuses primarily on English-language text, and the researchers note that the model's performance on other languages requires further investigation.
Overall, the "Segment Any Text" approach represents an important step forward in sentence segmentation, with the potential to have significant impact on a wide range of language processing applications. The universal and adaptable nature of the model could be particularly valuable in One Model to Rule Them All: Towards Universal Multilingual Text Segmentation and other areas where flexibility and robustness are critical.
Conclusion
The paper presents a novel approach to sentence segmentation that addresses key limitations of existing methods. By introducing a universal model capable of handling diverse text types with high accuracy, the researchers have made an important contribution to the field of natural language processing.
The "Segment Any Text" model demonstrates strong empirical performance and the potential for significant real-world impact, particularly in applications where adaptability and efficiency are crucial. While the paper identifies some areas for further research, the core ideas and technical innovations presented here represent a significant step forward in the quest for robust and versatile language processing capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Segment Any Text: A Universal Approach for Robust, Efficient and Adaptable Sentence Segmentation
Markus Frohmann, Igor Sterner, Ivan Vuli'c, Benjamin Minixhofer, Markus Schedl
Segmenting text into sentences plays an early and crucial role in many NLP systems. This is commonly achieved by using rule-based or statistical methods relying on lexical features such as punctuation. Although some recent works no longer exclusively rely on punctuation, we find that no prior method achieves all of (i) robustness to missing punctuation, (ii) effective adaptability to new domains, and (iii) high efficiency. We introduce a new model - Segment any Text (SaT) - to solve this problem. To enhance robustness, we propose a new pretraining scheme that ensures less reliance on punctuation. To address adaptability, we introduce an extra stage of parameter-efficient fine-tuning, establishing state-of-the-art performance in distinct domains such as verses from lyrics and legal documents. Along the way, we introduce architectural modifications that result in a threefold gain in speed over the previous state of the art and solve spurious reliance on context far in the future. Finally, we introduce a variant of our model with fine-tuning on a diverse, multilingual mixture of sentence-segmented data, acting as a drop-in replacement and enhancement for existing segmentation tools. Overall, our contributions provide a universal approach for segmenting any text. Our method outperforms all baselines - including strong LLMs - across 8 corpora spanning diverse domains and languages, especially in practically relevant situations where text is poorly formatted. Our models and code, including documentation, are available at https://huggingface.co/segment-any-text under the MIT license.
Read more6/26/2024

0
Scalable and Domain-General Abstractive Proposition Segmentation
Mohammad Javad Hosseini, Yang Gao, Tim Baumgartner, Alex Fabrikant, Reinald Kim Amplayo
Segmenting text into fine-grained units of meaning is important to a wide range of NLP applications. The default approach of segmenting text into sentences is often insufficient, especially since sentences are usually complex enough to include multiple units of meaning that merit separate treatment in the downstream task. We focus on the task of abstractive proposition segmentation: transforming text into simple, self-contained, well-formed sentences. Several recent works have demonstrated the utility of proposition segmentation with few-shot prompted LLMs for downstream tasks such as retrieval-augmented grounding and fact verification. However, this approach does not scale to large amounts of text and may not always extract all the facts from the input text. In this paper, we first introduce evaluation metrics for the task to measure several dimensions of quality. We then propose a scalable, yet accurate, proposition segmentation model. We model proposition segmentation as a supervised task by training LLMs on existing annotated datasets and show that training yields significantly improved results. We further show that by using the fine-tuned LLMs as teachers for annotating large amounts of multi-domain synthetic distillation data, we can train smaller student models with results similar to the teacher LLMs. We then demonstrate that our technique leads to effective domain generalization, by annotating data in two domains outside the original training data and evaluating on them. Finally, as a key contribution of the paper, we share an easy-to-use API for NLP practitioners to use.
Read more7/1/2024
📈
0
One Model to Rule them All: Towards Universal Segmentation for Medical Images with Text Prompts
Ziheng Zhao, Yao Zhang, Chaoyi Wu, Xiaoman Zhang, Ya Zhang, Yanfeng Wang, Weidi Xie
In this study, we aim to build up a model that can Segment Anything in radiology scans, driven by Text prompts, termed as SAT. Our main contributions are three folds: (i) for dataset construction, we construct the first multi-modal knowledge tree on human anatomy, including 6502 anatomical terminologies; Then we build up the largest and most comprehensive segmentation dataset for training, by collecting over 22K 3D medical image scans from 72 segmentation datasets, across 497 classes, with careful standardization on both image scans and label space; (ii) for architecture design, we propose to inject medical knowledge into a text encoder via contrastive learning, and then formulate a universal segmentation model, that can be prompted by feeding in medical terminologies in text form; (iii) As a result, we have trained SAT-Nano (110M parameters) and SAT-Pro (447M parameters), demonstrating comparable performance to 72 specialist nnU-Nets trained on each dataset/subsets. We validate SAT as a foundational segmentation model, with better generalization ability on external (unseen) datasets, and can be further improved on specific tasks after fine-tuning adaptation. Comparing with interactive segmentation model, for example, MedSAM, segmentation model prompted by text enables superior performance, scalability and robustness. As a use case, we demonstrate that SAT can act as a powerful out-of-the-box agent for large language models, enabling visual grounding in clinical procedures such as report generation. All the data, codes, and models in this work have been released.
Read more7/12/2024

0
Lightweight Audio Segmentation for Long-form Speech Translation
Jaesong Lee, Soyoon Kim, Hanbyul Kim, Joon Son Chung
Speech segmentation is an essential part of speech translation (ST) systems in real-world scenarios. Since most ST models are designed to process speech segments, long-form audio must be partitioned into shorter segments before translation. Recently, data-driven approaches for the speech segmentation task have been developed. Although the approaches improve overall translation quality, a performance gap exists due to a mismatch between the models and ST systems. In addition, the prior works require large self-supervised speech models, which consume significant computational resources. In this work, we propose a segmentation model that achieves better speech translation quality with a small model size. We propose an ASR-with-punctuation task as an effective pre-training strategy for the segmentation model. We also show that proper integration of the speech segmentation model into the underlying ST system is critical to improve overall translation quality at inference time.
Read more6/18/2024