Scalable and Domain-General Abstractive Proposition Segmentation

0

Sign in to get full access
Overview
- This paper presents a scalable and domain-general approach for abstractive proposition segmentation, a task that involves breaking down text into its key propositions or claims.
- The proposed method is designed to be effective across a wide range of domains, without requiring domain-specific training or feature engineering.
- The authors demonstrate the versatility and performance of their approach through extensive experiments on diverse datasets, including news articles, scientific papers, and web pages.
Plain English Explanation
The paper introduces a new technique for segmenting text into its key propositions. Propositions are the core claims or ideas that a piece of text is trying to convey. Being able to automatically identify these propositions can be useful for summarizing long documents, analyzing the structure of arguments, and various other natural language processing tasks.
The key innovation of this work is that the proposed method is scalable and applicable to many different domains. Unlike previous approaches that required specialized training for each new type of text, this method can work well on a wide range of inputs, from news articles to academic papers to web pages. This makes it a more versatile and practical solution for real-world applications.
The authors demonstrate the effectiveness of their approach through extensive testing on diverse datasets. They show that it can match or exceed the performance of specialized, domain-specific models, while being more efficient and easier to apply to new scenarios. This flexibility and scalability are important advances that could unlock new use cases for this type of text analysis technology.
Technical Explanation
The core of the proposed method is a neural network model that can identify proposition boundaries in text. The authors use a transformer-based architecture, which allows the model to capture complex contextual relationships within the input text.
To make the approach domain-general, the model is trained on a diverse corpus of texts, spanning multiple genres and topics. This "meta-training" strategy enables the model to learn generic patterns of proposition structure, rather than relying on features specific to any one domain.
During inference, the model processes the input text in a sliding window fashion, predicting proposition boundaries at each step. This allows the method to scale to arbitrarily long documents without memory constraints.
The authors evaluate their approach on several benchmark datasets, including news articles, scientific papers, and web pages. They show that it outperforms previous state-of-the-art methods, both in terms of segmentation accuracy and computational efficiency. The flexible, domain-agnostic nature of the model is a key strength that enables these strong results across diverse text types.
Critical Analysis
The authors acknowledge that their approach, like any machine learning model, has certain limitations. The performance may degrade on highly specialized or idiosyncratic text genres that are underrepresented in the training data. Additionally, the model's predictions can be sensitive to the quality and consistency of the proposition annotations in the training corpus.
One potential area for further research would be to investigate ways to further improve the model's robustness and adaptability. This could involve techniques like few-shot learning or active learning, which could help the model quickly adapt to new domains with minimal additional training.
Another avenue for exploration is the integration of this proposition segmentation method with higher-level text understanding tasks, such as summarization, question answering, or argument mining. Leveraging the identified propositions could lead to significant performance gains in these applications.
Overall, this paper presents a compelling and practical solution for a fundamental text analysis problem. The authors' focus on scalability and domain-generalization is a valuable contribution that could have a meaningful impact on a wide range of natural language processing use cases.
Conclusion
This paper introduces a novel approach for automatically segmenting text into its core propositions, or key claims and ideas. The proposed method is designed to be scalable and applicable across a diverse range of domains, without requiring specialized training or feature engineering for each new type of text.
Through extensive experiments, the authors demonstrate that their approach can match or exceed the performance of specialized, domain-specific models, while being more efficient and easier to apply to new scenarios. This flexibility and generalization capability are important advancements that could unlock new applications for proposition-level text analysis in areas like document summarization, argument mining, and knowledge extraction.
While the method has some limitations, the authors have laid the groundwork for further research to improve its robustness and integration with higher-level natural language processing tasks. Overall, this work represents a significant step forward in developing scalable and versatile tools for understanding the structure and content of text at a deep, semantic level.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Scalable and Domain-General Abstractive Proposition Segmentation
Mohammad Javad Hosseini, Yang Gao, Tim Baumgartner, Alex Fabrikant, Reinald Kim Amplayo
Segmenting text into fine-grained units of meaning is important to a wide range of NLP applications. The default approach of segmenting text into sentences is often insufficient, especially since sentences are usually complex enough to include multiple units of meaning that merit separate treatment in the downstream task. We focus on the task of abstractive proposition segmentation: transforming text into simple, self-contained, well-formed sentences. Several recent works have demonstrated the utility of proposition segmentation with few-shot prompted LLMs for downstream tasks such as retrieval-augmented grounding and fact verification. However, this approach does not scale to large amounts of text and may not always extract all the facts from the input text. In this paper, we first introduce evaluation metrics for the task to measure several dimensions of quality. We then propose a scalable, yet accurate, proposition segmentation model. We model proposition segmentation as a supervised task by training LLMs on existing annotated datasets and show that training yields significantly improved results. We further show that by using the fine-tuned LLMs as teachers for annotating large amounts of multi-domain synthetic distillation data, we can train smaller student models with results similar to the teacher LLMs. We then demonstrate that our technique leads to effective domain generalization, by annotating data in two domains outside the original training data and evaluating on them. Finally, as a key contribution of the paper, we share an easy-to-use API for NLP practitioners to use.
Read more7/1/2024
0
Segment Any Text: A Universal Approach for Robust, Efficient and Adaptable Sentence Segmentation
Markus Frohmann, Igor Sterner, Ivan Vuli'c, Benjamin Minixhofer, Markus Schedl
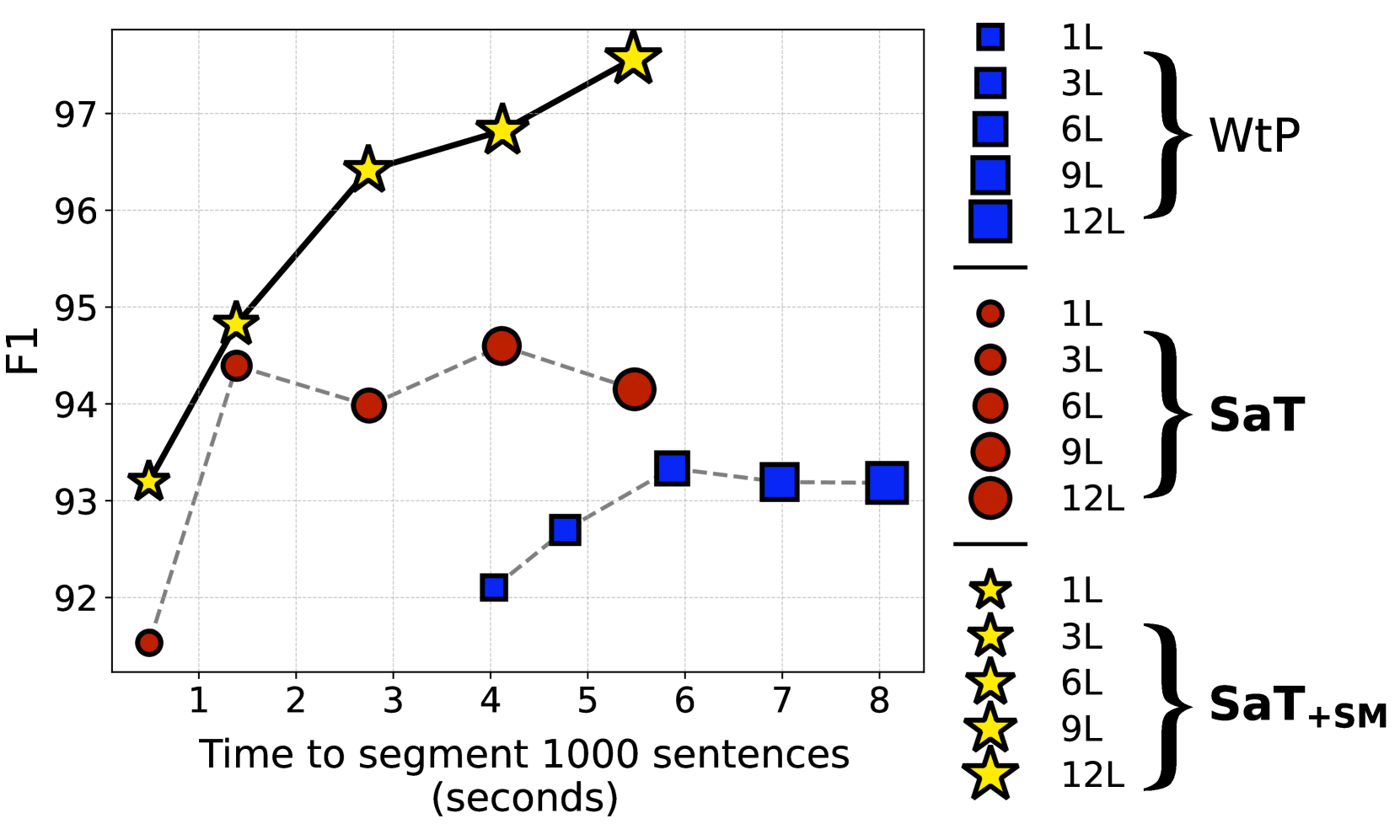
Segmenting text into sentences plays an early and crucial role in many NLP systems. This is commonly achieved by using rule-based or statistical methods relying on lexical features such as punctuation. Although some recent works no longer exclusively rely on punctuation, we find that no prior method achieves all of (i) robustness to missing punctuation, (ii) effective adaptability to new domains, and (iii) high efficiency. We introduce a new model - Segment any Text (SaT) - to solve this problem. To enhance robustness, we propose a new pretraining scheme that ensures less reliance on punctuation. To address adaptability, we introduce an extra stage of parameter-efficient fine-tuning, establishing state-of-the-art performance in distinct domains such as verses from lyrics and legal documents. Along the way, we introduce architectural modifications that result in a threefold gain in speed over the previous state of the art and solve spurious reliance on context far in the future. Finally, we introduce a variant of our model with fine-tuning on a diverse, multilingual mixture of sentence-segmented data, acting as a drop-in replacement and enhancement for existing segmentation tools. Overall, our contributions provide a universal approach for segmenting any text. Our method outperforms all baselines - including strong LLMs - across 8 corpora spanning diverse domains and languages, especially in practically relevant situations where text is poorly formatted. Our models and code, including documentation, are available at https://huggingface.co/segment-any-text under the MIT license.
Read more6/26/2024
0
FRACTAL: Fine-Grained Scoring from Aggregate Text Labels
Yukti Makhija, Priyanka Agrawal, Rishi Saket, Aravindan Raghuveer
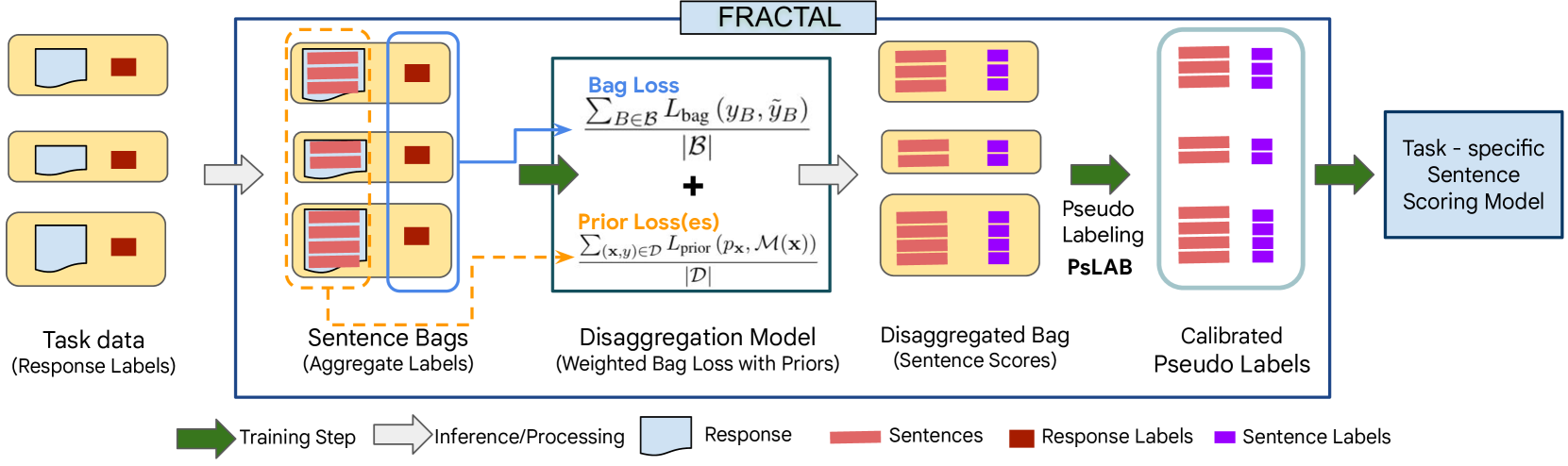
Large language models (LLMs) are being increasingly tuned to power complex generation tasks such as writing, fact-seeking, querying and reasoning. Traditionally, human or model feedback for evaluating and further tuning LLM performance has been provided at the response level, enabling faster and more cost-effective assessments. However, recent works (Amplayo et al. [2022], Wu et al. [2023]) indicate that sentence-level labels may provide more accurate and interpretable feedback for LLM optimization. In this work, we introduce methods to disaggregate response-level labels into sentence-level (pseudo-)labels. Our approach leverages multiple instance learning (MIL) and learning from label proportions (LLP) techniques in conjunction with prior information (e.g., document-sentence cosine similarity) to train a specialized model for sentence-level scoring. We also employ techniques which use model predictions to pseudo-label the train-set at the sentence-level for model training to further improve performance. We conduct extensive evaluations of our methods across six datasets and four tasks: retrieval, question answering, summarization, and math reasoning. Our results demonstrate improved performance compared to multiple baselines across most of these tasks. Our work is the first to develop response-level feedback to sentence-level scoring techniques, leveraging sentence-level prior information, along with comprehensive evaluations on multiple tasks as well as end-to-end finetuning evaluation showing performance comparable to a model trained on fine-grained human annotated labels.
Read more4/9/2024
📶
0
Scaling up Multi-domain Semantic Segmentation with Sentence Embeddings
Wei Yin, Yifan Liu, Chunhua Shen, Baichuan Sun, Anton van den Hengel
We propose an approach to semantic segmentation that achieves state-of-the-art supervised performance when applied in a zero-shot setting. It thus achieves results equivalent to those of the supervised methods, on each of the major semantic segmentation datasets, without training on those datasets. This is achieved by replacing each class label with a vector-valued embedding of a short paragraph that describes the class. The generality and simplicity of this approach enables merging multiple datasets from different domains, each with varying class labels and semantics. The resulting merged semantic segmentation dataset of over 2 Million images enables training a model that achieves performance equal to that of state-of-the-art supervised methods on 7 benchmark datasets, despite not using any images therefrom. By fine-tuning the model on standard semantic segmentation datasets, we also achieve a significant improvement over the state-of-the-art supervised segmentation on NYUD-V2 and PASCAL-context at 60% and 65% mIoU, respectively. Based on the closeness of language embeddings, our method can even segment unseen labels. Extensive experiments demonstrate strong generalization to unseen image domains and unseen labels, and that the method enables impressive performance improvements in downstream applications, including depth estimation and instance segmentation.
Read more5/1/2024