Segmentation-Free Guidance for Text-to-Image Diffusion Models

0

Sign in to get full access
Overview
- This research paper proposes a new method for guiding text-to-image diffusion models without relying on image segmentation.
- The authors introduce a "segmentation-free guidance" approach that aims to improve the alignment between the generated images and the provided text descriptions.
- The proposed method does not require explicit image segmentation, which can be computationally expensive and challenging to obtain, especially for complex scenes.
- Instead, the authors leverage a "training-free" loss function to provide guidance to the diffusion model during the image generation process.
Plain English Explanation
The research paper presents a new way to help text-to-image diffusion models create images that better match the given text descriptions. Diffusion models are a type of machine learning model that can generate images from scratch by iteratively adding and removing "noise" from an image.
Traditional approaches to guiding these models often rely on segmenting the input image into different regions, such as the sky, buildings, and people. However, this segmentation process can be computationally complex and challenging, especially for more intricate scenes.
Instead, the researchers propose a "segmentation-free" approach that uses a "training-free" loss function to provide guidance to the diffusion model during the image generation process. This loss function helps the model create images that are more closely aligned with the provided text descriptions, without the need for explicit image segmentation.
The key idea is to use the text descriptions to directly guide the diffusion model, rather than relying on segmented image regions. This can make the overall process more efficient and potentially improve the quality of the generated images.
Technical Explanation
The paper introduces a "segmentation-free guidance" approach to improve the alignment between generated images and their corresponding text descriptions in text-to-image diffusion models.
Traditional methods often rely on image segmentation, which can be computationally expensive and challenging, especially for complex scenes. In contrast, the proposed approach does not require explicit segmentation. Instead, it leverages a "training-free" loss function to provide guidance to the diffusion model during the image generation process.
The authors draw inspiration from recent work on training-free loss functions for diffusion models and plug-and-play diffusion models. They introduce a new loss function that directly optimizes the alignment between the generated image and the text description, without the need for segmented image regions.
Experiments on several benchmark datasets, including COCO and Conceptual Captions, demonstrate the effectiveness of the proposed segmentation-free guidance approach. The authors show that their method can generate images that are more closely aligned with the provided text descriptions, compared to previous segmentation-based techniques.
Critical Analysis
The paper presents a promising approach to improving text-to-image diffusion models, but there are a few potential limitations and areas for further research:
-
Generalization to Complex Scenes: While the paper demonstrates the effectiveness of the segmentation-free guidance approach on benchmark datasets, it remains to be seen how well it will perform on more complex and diverse real-world scenes. Handling intricate compositions with multiple objects and interactions may require additional considerations.
-
Computational Efficiency: The authors do not provide a detailed analysis of the computational complexity and runtime of their proposed method compared to segmentation-based approaches. Ensuring the efficiency of the segmentation-free guidance process is crucial for practical deployment.
-
Interpretability and Explainability: The paper does not delve into the interpretability and explainability of the segmentation-free guidance approach. Understanding how the model aligns the generated images with the text descriptions could be valuable for users and researchers.
-
Potential Biases and Limitations: As with any machine learning system, the text-to-image diffusion models and the segmentation-free guidance approach may inherit or amplify biases present in the training data. Further research is needed to assess and mitigate these potential issues.
Despite these considerations, the paper represents an important step towards more efficient and effective text-to-image generation, which could have significant implications for various applications, such as creative content generation, visual storytelling, and assistive technologies.
Conclusion
The research paper introduces a novel "segmentation-free guidance" approach to improve the alignment between generated images and their corresponding text descriptions in text-to-image diffusion models. By leveraging a "training-free" loss function, the proposed method avoids the need for explicit image segmentation, which can be computationally expensive and challenging, especially for complex scenes.
The experimental results demonstrate the effectiveness of the segmentation-free guidance approach, suggesting that it can generate images that are more closely aligned with the provided text descriptions compared to previous segmentation-based techniques. This work represents an important advancement in the field of text-to-image generation, with potential applications in various domains, such as creative content creation, visual storytelling, and assistive technologies.
As the research in this area continues to evolve, further exploration of the generalization, computational efficiency, interpretability, and potential biases of the segmentation-free guidance approach will be crucial to unlocking its full potential and ensuring responsible development of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Segmentation-Free Guidance for Text-to-Image Diffusion Models
Kambiz Azarian, Debasmit Das, Qiqi Hou, Fatih Porikli
We introduce segmentation-free guidance, a novel method designed for text-to-image diffusion models like Stable Diffusion. Our method does not require retraining of the diffusion model. At no additional compute cost, it uses the diffusion model itself as an implied segmentation network, hence named segmentation-free guidance, to dynamically adjust the negative prompt for each patch of the generated image, based on the patch's relevance to concepts in the prompt. We evaluate segmentation-free guidance both objectively, using FID, CLIP, IS, and PickScore, and subjectively, through human evaluators. For the subjective evaluation, we also propose a methodology for subsampling the prompts in a dataset like MS COCO-30K to keep the number of human evaluations manageable while ensuring that the selected subset is both representative in terms of content and fair in terms of model performance. The results demonstrate the superiority of our segmentation-free guidance to the widely used classifier-free method. Human evaluators preferred segmentation-free guidance over classifier-free 60% to 19%, with 18% of occasions showing a strong preference. Additionally, PickScore win-rate, a recently proposed metric mimicking human preference, also indicates a preference for our method over classifier-free.
Read more7/9/2024
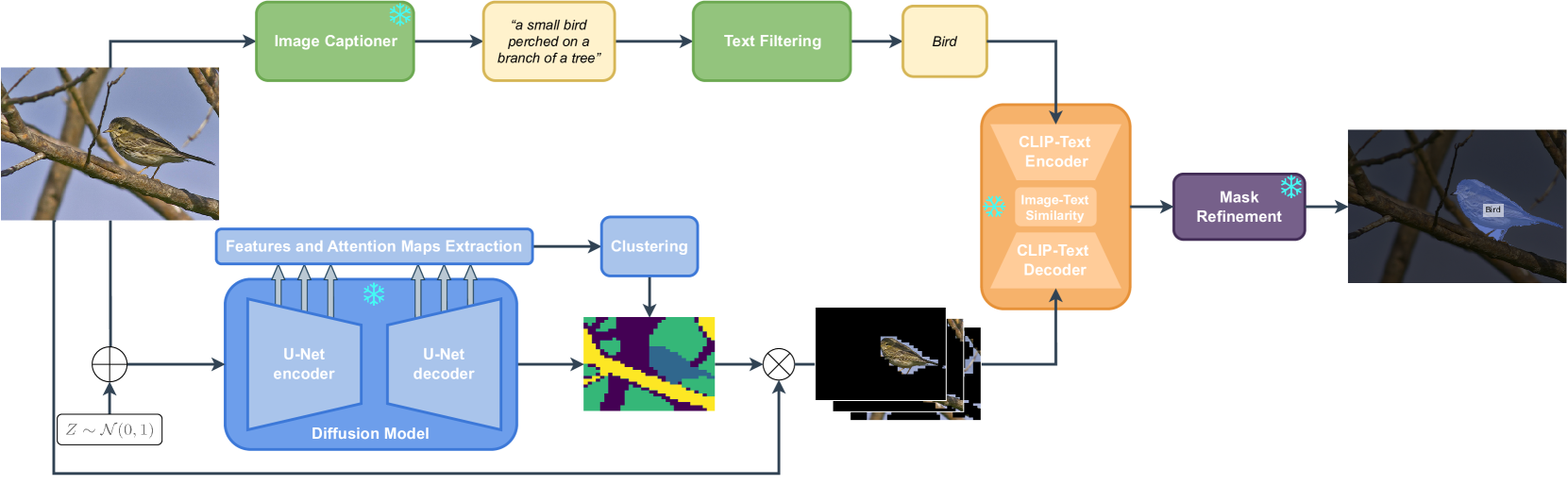
0
FreeSeg-Diff: Training-Free Open-Vocabulary Segmentation with Diffusion Models
Barbara Toniella Corradini, Mustafa Shukor, Paul Couairon, Guillaume Couairon, Franco Scarselli, Matthieu Cord
Foundation models have exhibited unprecedented capabilities in tackling many domains and tasks. Models such as CLIP are currently widely used to bridge cross-modal representations, and text-to-image diffusion models are arguably the leading models in terms of realistic image generation. Image generative models are trained on massive datasets that provide them with powerful internal spatial representations. In this work, we explore the potential benefits of such representations, beyond image generation, in particular, for dense visual prediction tasks. We focus on the task of image segmentation, which is traditionally solved by training models on closed-vocabulary datasets, with pixel-level annotations. To avoid the annotation cost or training large diffusion models, we constraint our setup to be zero-shot and training-free. In a nutshell, our pipeline leverages different and relatively small-sized, open-source foundation models for zero-shot open-vocabulary segmentation. The pipeline is as follows: the image is passed to both a captioner model (i.e. BLIP) and a diffusion model (i.e., Stable Diffusion Model) to generate a text description and visual representation, respectively. The features are clustered and binarized to obtain class agnostic masks for each object. These masks are then mapped to a textual class, using the CLIP model to support open-vocabulary. Finally, we add a refinement step that allows to obtain a more precise segmentation mask. Our approach (dubbed FreeSeg-Diff), which does not rely on any training, outperforms many training-based approaches on both Pascal VOC and COCO datasets. In addition, we show very competitive results compared to the recent weakly-supervised segmentation approaches. We provide comprehensive experiments showing the superiority of diffusion model features compared to other pretrained models. Project page: https://bcorrad.github.io/freesegdiff/
Read more4/1/2024
🛸
0
Scribble-Guided Diffusion for Training-free Text-to-Image Generation
Seonho Lee, Jiho Choi, Seohyun Lim, Jiwook Kim, Hyunjung Shim
Recent advancements in text-to-image diffusion models have demonstrated remarkable success, yet they often struggle to fully capture the user's intent. Existing approaches using textual inputs combined with bounding boxes or region masks fall short in providing precise spatial guidance, often leading to misaligned or unintended object orientation. To address these limitations, we propose Scribble-Guided Diffusion (ScribbleDiff), a training-free approach that utilizes simple user-provided scribbles as visual prompts to guide image generation. However, incorporating scribbles into diffusion models presents challenges due to their sparse and thin nature, making it difficult to ensure accurate orientation alignment. To overcome these challenges, we introduce moment alignment and scribble propagation, which allow for more effective and flexible alignment between generated images and scribble inputs. Experimental results on the PASCAL-Scribble dataset demonstrate significant improvements in spatial control and consistency, showcasing the effectiveness of scribble-based guidance in diffusion models. Our code is available at https://github.com/kaist-cvml-lab/scribble-diffusion.
Read more9/14/2024

0
Understanding and Improving Training-free Loss-based Diffusion Guidance
Yifei Shen, Xinyang Jiang, Yezhen Wang, Yifan Yang, Dongqi Han, Dongsheng Li
Adding additional control to pretrained diffusion models has become an increasingly popular research area, with extensive applications in computer vision, reinforcement learning, and AI for science. Recently, several studies have proposed training-free loss-based guidance by using off-the-shelf networks pretrained on clean images. This approach enables zero-shot conditional generation for universal control formats, which appears to offer a free lunch in diffusion guidance. In this paper, we aim to develop a deeper understanding of training-free guidance, as well as overcome its limitations. We offer a theoretical analysis that supports training-free guidance from the perspective of optimization, distinguishing it from classifier-based (or classifier-free) guidance. To elucidate their drawbacks, we theoretically demonstrate that training-free guidance is more susceptible to adversarial gradients and exhibits slower convergence rates compared to classifier guidance. We then introduce a collection of techniques designed to overcome the limitations, accompanied by theoretical rationale and empirical evidence. Our experiments in image and motion generation confirm the efficacy of these techniques.
Read more5/30/2024