Exploring Phrase-Level Grounding with Text-to-Image Diffusion Model

0

Sign in to get full access
Overview
- This paper explores the concept of phrase-level grounding, which aims to connect specific language phrases to their corresponding visual elements in an image.
- The researchers leverage a text-to-image diffusion model, a powerful machine learning technique, to investigate this problem.
- The paper presents several experiments and findings related to phrase-level grounding, including zero-shot learning and open-vocabulary segmentation.
Plain English Explanation
The paper looks at the idea of connecting specific words or phrases in text to the corresponding visual elements in an image. This is known as "phrase-level grounding." The researchers use a machine learning technique called a "text-to-image diffusion model" to explore this concept.
Diffusion models are a type of AI that can generate images from text descriptions. In this paper, the researchers investigate how well these models can ground individual phrases to specific visual elements in the generated images. This could be useful for applications like zero-shot learning, where the model can recognize and segment objects it hasn't seen before, or open-vocabulary segmentation, where the model can segment images based on arbitrary text phrases.
The paper presents several experiments and findings related to this phrase-level grounding task, exploring how well the diffusion models can perform and what the limitations might be. The results could have implications for text-guided image and video generation, as well as medical image segmentation and other applications where connecting language to visual content is important.
Technical Explanation
The paper investigates the concept of phrase-level grounding, which aims to connect specific language phrases to their corresponding visual elements in an image. The researchers leverage a text-to-image diffusion model, a powerful machine learning technique that can generate images from text descriptions.
Through a series of experiments, the authors explore how well these diffusion models can ground individual phrases to specific visual elements in the generated images. This includes evaluating the models' performance on zero-shot learning tasks, where the model can recognize and segment objects it hasn't seen before, as well as open-vocabulary segmentation tasks, where the model can segment images based on arbitrary text phrases.
The paper also investigates the models' ability to generate images that are coherent with the provided text prompts, and examines the types of visual elements that are most effectively grounded to the corresponding language. The researchers further explore the potential of these models for text-guided image and video generation and medical image segmentation tasks, where connecting language to visual content is critical.
Critical Analysis
The paper presents a thorough exploration of phrase-level grounding with text-to-image diffusion models, but there are a few potential limitations and areas for further research:
-
The experiments are primarily focused on generated images, which may not fully capture the models' ability to ground language to real-world visual content. Evaluating the models on tasks involving natural images could provide additional insights.
-
The paper does not delve deeply into the interpretability and explainability of the models' grounding mechanisms. Understanding how the models make these connections could lead to more robust and trustworthy systems.
-
The researchers note that the models' performance on phrase-level grounding tasks is still far from human-level, suggesting there is room for improvement. Exploring newer architectures, training strategies, or data sources could help advance the state of the art.
-
The paper does not address potential biases or ethical considerations that may arise from these types of language-to-vision models, which is an important area for future research and discussion.
Overall, the paper represents a valuable contribution to the field of multimodal AI and provides a solid foundation for further exploration of phrase-level grounding and its applications.
Conclusion
This paper presents an in-depth investigation of phrase-level grounding using text-to-image diffusion models. The researchers explore the models' ability to connect specific language phrases to corresponding visual elements in generated images, with a focus on tasks like zero-shot learning and open-vocabulary segmentation.
The findings suggest that these models can indeed ground language to visual content, but there is still room for improvement in terms of performance and interpretability. The research has implications for a range of applications, from text-guided image and video generation to medical image segmentation, where connecting language to visual content is crucial.
As the field of multimodal AI continues to advance, this paper offers valuable insights and lays the groundwork for further exploration of phrase-level grounding and its practical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Exploring Phrase-Level Grounding with Text-to-Image Diffusion Model
Danni Yang, Ruohan Dong, Jiayi Ji, Yiwei Ma, Haowei Wang, Xiaoshuai Sun, Rongrong Ji
Recently, diffusion models have increasingly demonstrated their capabilities in vision understanding. By leveraging prompt-based learning to construct sentences, these models have shown proficiency in classification and visual grounding tasks. However, existing approaches primarily showcase their ability to perform sentence-level localization, leaving the potential for leveraging contextual information for phrase-level understanding largely unexplored. In this paper, we utilize Panoptic Narrative Grounding (PNG) as a proxy task to investigate this capability further. PNG aims to segment object instances mentioned by multiple noun phrases within a given narrative text. Specifically, we introduce the DiffPNG framework, a straightforward yet effective approach that fully capitalizes on the diffusion's architecture for segmentation by decomposing the process into a sequence of localization, segmentation, and refinement steps. The framework initially identifies anchor points using cross-attention mechanisms and subsequently performs segmentation with self-attention to achieve zero-shot PNG. Moreover, we introduce a refinement module based on SAM to enhance the quality of the segmentation masks. Our extensive experiments on the PNG dataset demonstrate that DiffPNG achieves strong performance in the zero-shot PNG task setting, conclusively proving the diffusion model's capability for context-aware, phrase-level understanding. Source code is available at url{https://github.com/nini0919/DiffPNG}.
Read more7/9/2024
🚀
0
Dynamic Prompting of Frozen Text-to-Image Diffusion Models for Panoptic Narrative Grounding
Hongyu Li, Tianrui Hui, Zihan Ding, Jing Zhang, Bin Ma, Xiaoming Wei, Jizhong Han, Si Liu
Panoptic narrative grounding (PNG), whose core target is fine-grained image-text alignment, requires a panoptic segmentation of referred objects given a narrative caption. Previous discriminative methods achieve only weak or coarse-grained alignment by panoptic segmentation pretraining or CLIP model adaptation. Given the recent progress of text-to-image Diffusion models, several works have shown their capability to achieve fine-grained image-text alignment through cross-attention maps and improved general segmentation performance. However, the direct use of phrase features as static prompts to apply frozen Diffusion models to the PNG task still suffers from a large task gap and insufficient vision-language interaction, yielding inferior performance. Therefore, we propose an Extractive-Injective Phrase Adapter (EIPA) bypass within the Diffusion UNet to dynamically update phrase prompts with image features and inject the multimodal cues back, which leverages the fine-grained image-text alignment capability of Diffusion models more sufficiently. In addition, we also design a Multi-Level Mutual Aggregation (MLMA) module to reciprocally fuse multi-level image and phrase features for segmentation refinement. Extensive experiments on the PNG benchmark show that our method achieves new state-of-the-art performance.
Read more9/14/2024
0
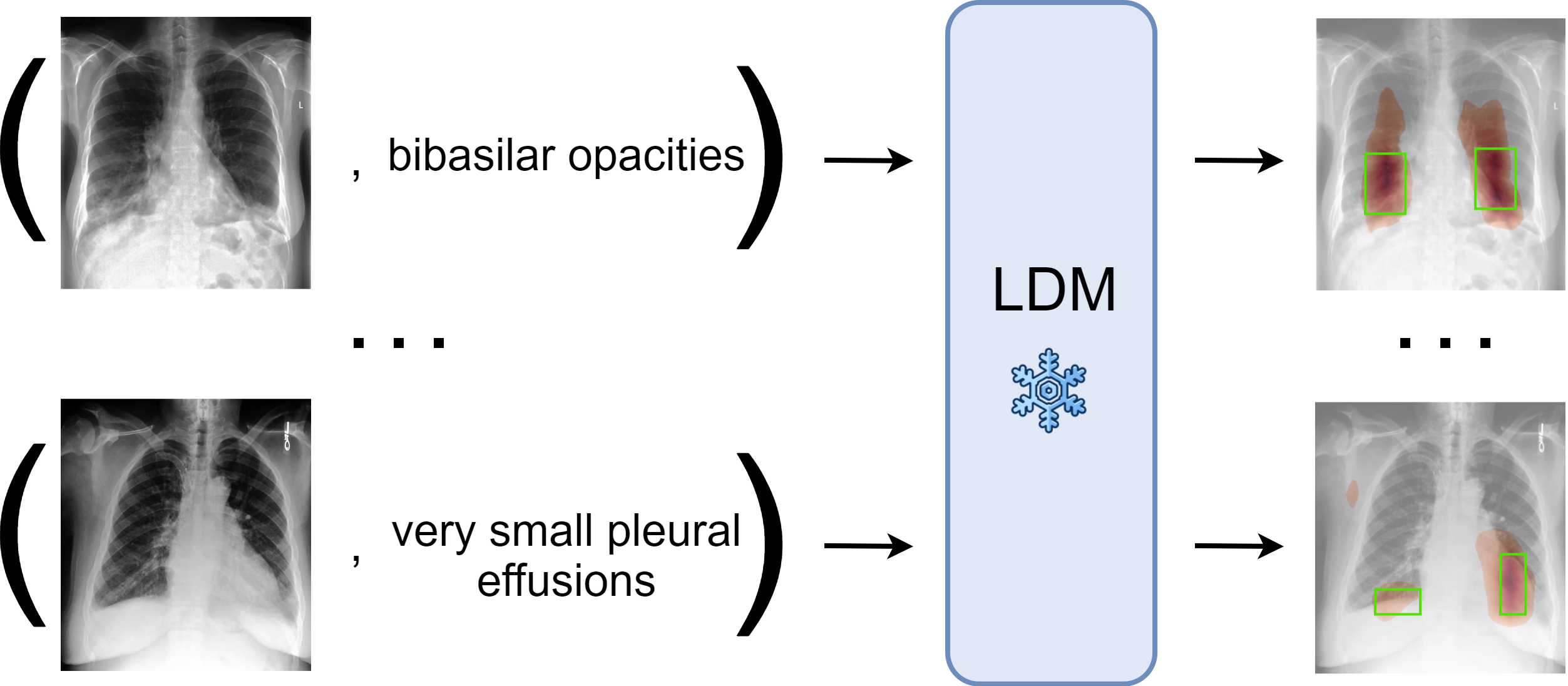
Zero-Shot Medical Phrase Grounding with Off-the-shelf Diffusion Models
Konstantinos Vilouras, Pedro Sanchez, Alison Q. O'Neil, Sotirios A. Tsaftaris
Localizing the exact pathological regions in a given medical scan is an important imaging problem that requires a large amount of bounding box ground truth annotations to be accurately solved. However, there exist alternative, potentially weaker, forms of supervision, such as accompanying free-text reports, which are readily available. The task of performing localization with textual guidance is commonly referred to as phrase grounding. In this work, we use a publicly available Foundation Model, namely the Latent Diffusion Model, to solve this challenging task. This choice is supported by the fact that the Latent Diffusion Model, despite being generative in nature, contains mechanisms (cross-attention) that implicitly align visual and textual features, thus leading to intermediate representations that are suitable for the task at hand. In addition, we aim to perform this task in a zero-shot manner, i.e., without any further training on target data, meaning that the model's weights remain frozen. To this end, we devise strategies to select features and also refine them via post-processing without extra learnable parameters. We compare our proposed method with state-of-the-art approaches which explicitly enforce image-text alignment in a joint embedding space via contrastive learning. Results on a popular chest X-ray benchmark indicate that our method is competitive wih SOTA on different types of pathology, and even outperforms them on average in terms of two metrics (mean IoU and AUC-ROC). Source code will be released upon acceptance.
Read more7/18/2024

0
Contextualized Diffusion Models for Text-Guided Image and Video Generation
Ling Yang, Zhilong Zhang, Zhaochen Yu, Jingwei Liu, Minkai Xu, Stefano Ermon, Bin Cui
Conditional diffusion models have exhibited superior performance in high-fidelity text-guided visual generation and editing. Nevertheless, prevailing text-guided visual diffusion models primarily focus on incorporating text-visual relationships exclusively into the reverse process, often disregarding their relevance in the forward process. This inconsistency between forward and reverse processes may limit the precise conveyance of textual semantics in visual synthesis results. To address this issue, we propose a novel and general contextualized diffusion model (ContextDiff) by incorporating the cross-modal context encompassing interactions and alignments between text condition and visual sample into forward and reverse processes. We propagate this context to all timesteps in the two processes to adapt their trajectories, thereby facilitating cross-modal conditional modeling. We generalize our contextualized diffusion to both DDPMs and DDIMs with theoretical derivations, and demonstrate the effectiveness of our model in evaluations with two challenging tasks: text-to-image generation, and text-to-video editing. In each task, our ContextDiff achieves new state-of-the-art performance, significantly enhancing the semantic alignment between text condition and generated samples, as evidenced by quantitative and qualitative evaluations. Our code is available at https://github.com/YangLing0818/ContextDiff
Read more6/5/2024