SegNet4D: Effective and Efficient 4D LiDAR Semantic Segmentation in Autonomous Driving Environments

0

Sign in to get full access
Overview
- This research paper proposes a novel 4D LiDAR semantic segmentation model called SegNet4D, which is designed for autonomous driving environments.
- The model leverages spatio-temporal information to effectively and efficiently segment dynamic 3D scenes, including moving objects.
- Key contributions include a 4D feature encoding module, a dynamic instance head, and a lightweight backbone network.
Plain English Explanation
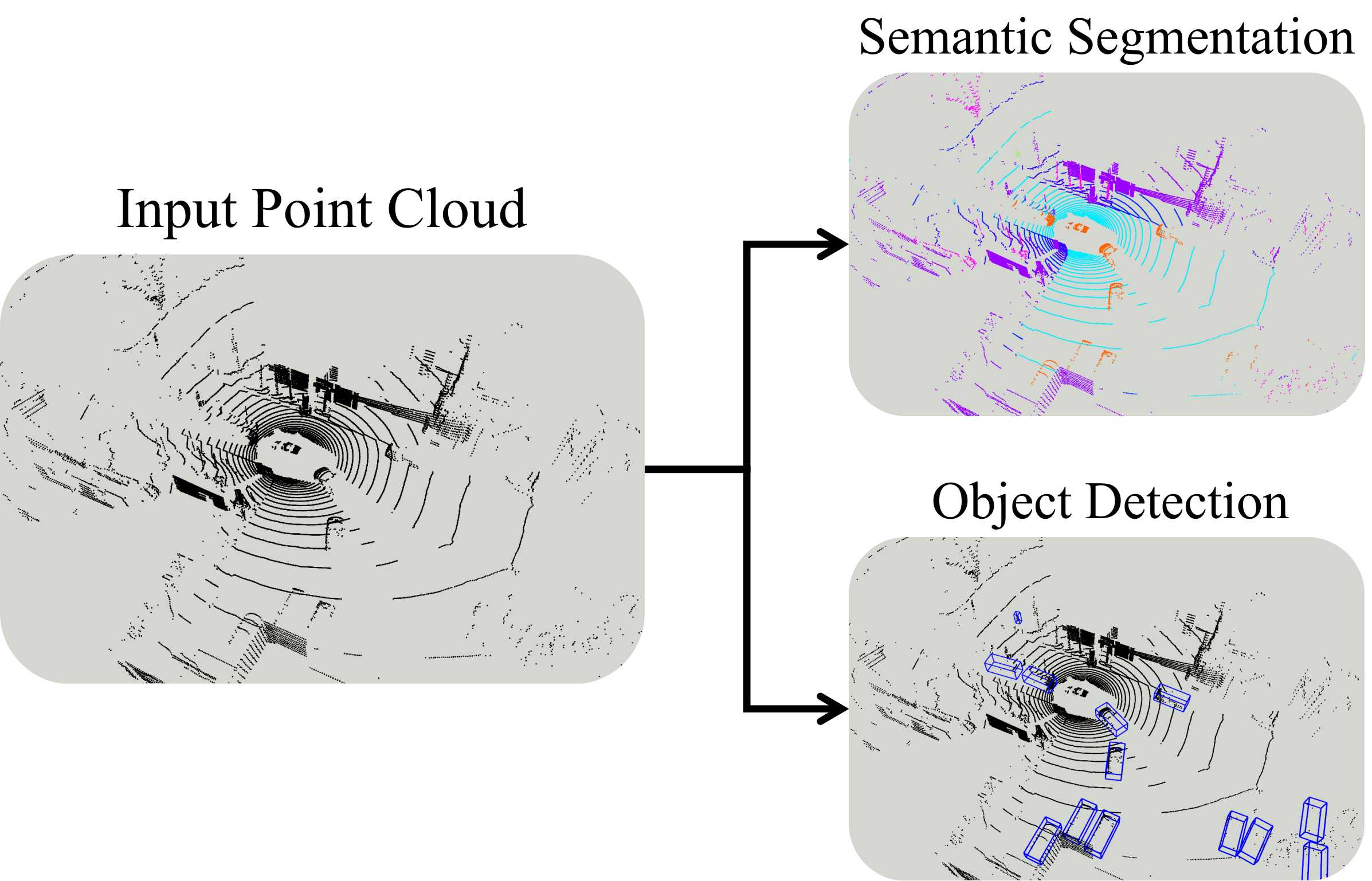
SegNet4D is a deep learning model that can analyze 4D LiDAR data, which includes 3D spatial information along with the temporal dimension of how the scene changes over time. This is useful for autonomous driving, where it's important to understand not just the static environment, but also the dynamic objects like other vehicles, pedestrians, and cyclists.
The 4D feature encoding module in SegNet4D takes the input LiDAR scans and encodes the spatial and temporal information into a compact representation. This allows the model to efficiently process the 4D data and segment both static and moving objects. The dynamic instance head further refines the segmentation by identifying individual instances of objects, which is crucial for applications like vehicle tracking.
The researchers also developed a lightweight backbone network for SegNet4D, making it computationally efficient and suitable for real-time deployment in autonomous vehicles. This is an important consideration, as self-driving cars need to process sensor data and make decisions quickly to navigate safely.
Overall, SegNet4D represents an advance in 4D LiDAR semantic segmentation that could significantly improve the perception capabilities of autonomous driving systems.
Technical Explanation
The SegNet4D model takes 4D LiDAR data as input, which consists of a sequence of 3D point cloud frames capturing the dynamic scene. The 4D feature encoding module uses a combination of 3D convolutions and recurrent neural networks to extract spatio-temporal features from the input. This allows the model to effectively capture both the static and moving elements of the scene.
The dynamic instance head is then applied to the encoded features to segment individual object instances, even if they are in motion. This is achieved by predicting instance-level masks and trajectories, which enables the model to track and differentiate between different dynamic objects.
To ensure efficiency, the researchers designed a lightweight backbone network for SegNet4D, which maintains high performance while requiring fewer parameters and computations than conventional architectures. This makes the model suitable for real-time inference on embedded systems found in autonomous vehicles.
The authors evaluate SegNet4D on several 4D LiDAR benchmarks, including the Semantic KITTI dataset, and demonstrate state-of-the-art results in both semantic segmentation and instance segmentation of dynamic scenes.
Critical Analysis
The paper provides a thorough evaluation of SegNet4D, including comparisons to other 4D LiDAR segmentation models. The results suggest that the proposed approach is effective at capturing spatio-temporal information and outperforms existing methods in terms of accuracy and computational efficiency.
However, the authors note that SegNet4D may struggle in scenarios with severe occlusions or highly dynamic environments, as the model relies on temporal consistency to some extent. Additionally, the training and evaluation were conducted on a limited number of datasets, so further testing on a broader range of autonomous driving scenarios would be beneficial to assess the model's generalization capabilities.
It would also be interesting to see how SegNet4D performs when integrated into a complete autonomous driving pipeline, including other perception and planning modules. This could help uncover any potential issues or bottlenecks that may arise in a real-world deployment.
Conclusion
The SegNet4D model represents an important advancement in 4D LiDAR semantic segmentation for autonomous driving applications. By effectively leveraging spatio-temporal information, the model can accurately segment both static and dynamic objects in real-time, a crucial capability for self-driving cars to navigate complex environments safely.
The researchers' innovative approach to feature encoding, dynamic instance segmentation, and lightweight network design makes SegNet4D a promising solution for deploying high-performance 4D perception systems in autonomous vehicles. As the field of autonomous driving continues to evolve, advancements like SegNet4D will play a crucial role in enhancing the perception and decision-making capabilities of self-driving systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SegNet4D: Effective and Efficient 4D LiDAR Semantic Segmentation in Autonomous Driving Environments
Neng Wang, Ruibin Guo, Chenghao Shi, Hui Zhang, Huimin Lu, Zhiqiang Zheng, Xieyuanli Chen
4D LiDAR semantic segmentation, also referred to as multi-scan semantic segmentation, plays a crucial role in enhancing the environmental understanding capabilities of autonomous vehicles. It entails identifying the semantic category of each point in the LiDAR scan and distinguishing whether it is dynamic, a critical aspect in downstream tasks such as path planning and autonomous navigation. Existing methods for 4D semantic segmentation often rely on computationally intensive 4D convolutions for multi-scan input, resulting in poor real-time performance. In this article, we introduce SegNet4D, a novel real-time multi-scan semantic segmentation method leveraging a projection-based approach for fast motion feature encoding, showcasing outstanding performance. SegNet4D treats 4D semantic segmentation as two distinct tasks: single-scan semantic segmentation and moving object segmentation, each addressed by dedicated head. These results are then fused in the proposed motion-semantic fusion module to achieve comprehensive multi-scan semantic segmentation. Besides, we propose extracting instance information from the current scan and incorporating it into the network for instance-aware segmentation. Our approach exhibits state-of-the-art performance across multiple datasets and stands out as a real-time multi-scan semantic segmentation method. The implementation of SegNet4D will be made available at url{https://github.com/nubot-nudt/SegNet4D}.
Read more6/26/2024
0
LiSD: An Efficient Multi-Task Learning Framework for LiDAR Segmentation and Detection
Jiahua Xu, Si Zuo, Chenfeng Wei, Wei Zhou
With the rapid proliferation of autonomous driving, there has been a heightened focus on the research of lidar-based 3D semantic segmentation and object detection methodologies, aiming to ensure the safety of traffic participants. In recent decades, learning-based approaches have emerged, demonstrating remarkable performance gains in comparison to conventional algorithms. However, the segmentation and detection tasks have traditionally been examined in isolation to achieve the best precision. To this end, we propose an efficient multi-task learning framework named LiSD which can address both segmentation and detection tasks, aiming to optimize the overall performance. Our proposed LiSD is a voxel-based encoder-decoder framework that contains a hierarchical feature collaboration module and a holistic information aggregation module. Different integration methods are adopted to keep sparsity in segmentation while densifying features for query initialization in detection. Besides, cross-task information is utilized in an instance-aware refinement module to obtain more accurate predictions. Experimental results on the nuScenes dataset and Waymo Open Dataset demonstrate the effectiveness of our proposed model. It is worth noting that LiSD achieves the state-of-the-art performance of 83.3% mIoU on the nuScenes segmentation benchmark for lidar-only methods.
Read more6/13/2024
🧠
0
3D LiDAR Mapping in Dynamic Environments Using a 4D Implicit Neural Representation
Xingguang Zhong, Yue Pan, Cyrill Stachniss, Jens Behley
Building accurate maps is a key building block to enable reliable localization, planning, and navigation of autonomous vehicles. We propose a novel approach for building accurate maps of dynamic environments utilizing a sequence of LiDAR scans. To this end, we propose encoding the 4D scene into a novel spatio-temporal implicit neural map representation by fitting a time-dependent truncated signed distance function to each point. Using our representation, we extract the static map by filtering the dynamic parts. Our neural representation is based on sparse feature grids, a globally shared decoder, and time-dependent basis functions, which we jointly optimize in an unsupervised fashion. To learn this representation from a sequence of LiDAR scans, we design a simple yet efficient loss function to supervise the map optimization in a piecewise way. We evaluate our approach on various scenes containing moving objects in terms of the reconstruction quality of static maps and the segmentation of dynamic point clouds. The experimental results demonstrate that our method is capable of removing the dynamic part of the input point clouds while reconstructing accurate and complete 3D maps, outperforming several state-of-the-art methods. Codes are available at: https://github.com/PRBonn/4dNDF
Read more5/7/2024

0
Flow4D: Leveraging 4D Voxel Network for LiDAR Scene Flow Estimation
Jaeyeul Kim, Jungwan Woo, Ukcheol Shin, Jean Oh, Sunghoon Im
Understanding the motion states of the surrounding environment is critical for safe autonomous driving. These motion states can be accurately derived from scene flow, which captures the three-dimensional motion field of points. Existing LiDAR scene flow methods extract spatial features from each point cloud and then fuse them channel-wise, resulting in the implicit extraction of spatio-temporal features. Furthermore, they utilize 2D Bird's Eye View and process only two frames, missing crucial spatial information along the Z-axis and the broader temporal context, leading to suboptimal performance. To address these limitations, we propose Flow4D, which temporally fuses multiple point clouds after the 3D intra-voxel feature encoder, enabling more explicit extraction of spatio-temporal features through a 4D voxel network. However, while using 4D convolution improves performance, it significantly increases the computational load. For further efficiency, we introduce the Spatio-Temporal Decomposition Block (STDB), which combines 3D and 1D convolutions instead of using heavy 4D convolution. In addition, Flow4D further improves performance by using five frames to take advantage of richer temporal information. As a result, the proposed method achieves a 45.9% higher performance compared to the state-of-the-art while running in real-time, and won 1st place in the 2024 Argoverse 2 Scene Flow Challenge. The code is available at https://github.com/dgist-cvlab/Flow4D.
Read more7/12/2024