SelECT-SQL: Self-correcting ensemble Chain-of-Thought for Text-to-SQL

0
Sign in to get full access
Overview
- SelECT-SQL is a self-correcting ensemble model that uses a Chain-of-Thought approach for text-to-SQL translation.
- It aims to improve the reliability and accuracy of SQL query generation from natural language descriptions.
- The model leverages multiple sub-models to generate a sequence of intermediate steps, allowing it to self-correct and produce a final SQL query.
Plain English Explanation
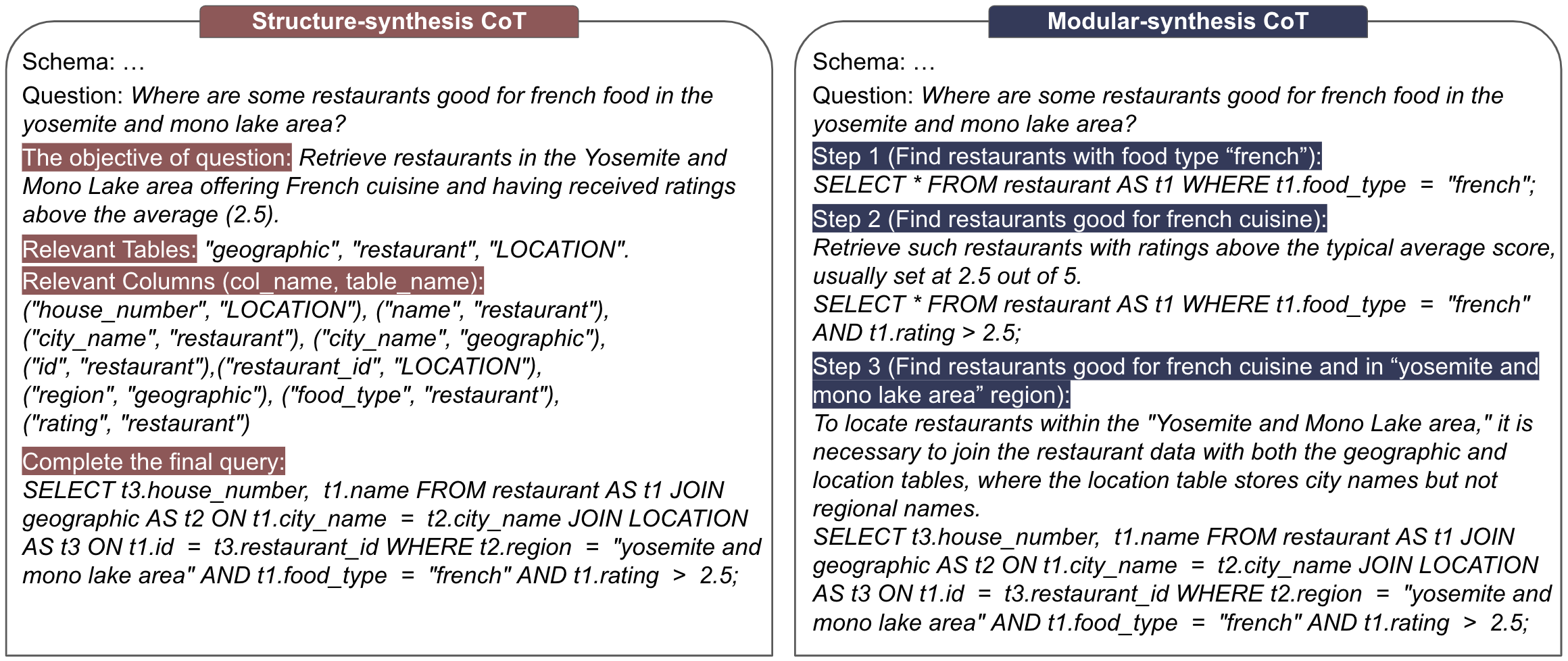
The SelECT-SQL model is designed to help translate natural language descriptions into SQL queries more reliably. Rather than generating a SQL query directly, the model uses a Chain-of-Thought approach, where it produces a sequence of intermediate steps that build up to the final SQL query.
This approach allows the model to self-correct and refine its understanding of the problem, ultimately generating a more accurate SQL query. The model includes multiple sub-models that work together as an ensemble to achieve this.
By breaking down the translation process into smaller, more manageable steps, SelECT-SQL can better handle the complexities of converting natural language into structured database queries. This can be particularly useful for advanced database interfaces that need to handle a wide range of user requests accurately.
Technical Explanation
The SelECT-SQL model is built on a Chain-of-Thought architecture, which means it generates a sequence of intermediate steps that lead to the final SQL query. This allows the model to self-correct and refine its understanding of the problem as it progresses.
The model includes multiple sub-models that work together as an ensemble. These sub-models are responsible for different aspects of the translation process, such as identifying the relevant tables and columns, generating intermediate SQL clauses, and combining them into a final query.
By breaking down the task into smaller steps, SelECT-SQL can better handle the complexities of text-to-SQL translation. This approach has been shown to improve the reliability and accuracy of the generated SQL queries compared to more traditional methods.
Critical Analysis
The authors of the SelECT-SQL paper acknowledge that the model's performance is still limited by the quality and diversity of the training data. As with many language models, the model may struggle with rare or uncommon queries, or with queries that require a deep understanding of the underlying database schema.
Additionally, the paper does not provide a detailed analysis of the model's limitations or potential biases. It would be helpful to understand the types of queries the model performs best on, as well as any areas where it may fall short.
Further research could explore ways to improve the model's robustness and ability to handle a wider range of natural language inputs, potentially through techniques like few-shot learning or data augmentation.
Conclusion
The SelECT-SQL model represents a promising approach to improving the reliability and accuracy of text-to-SQL translation. By using a Chain-of-Thought architecture and an ensemble of sub-models, the model can self-correct and generate more accurate SQL queries from natural language descriptions.
This technology could have important applications in advanced database interfaces, where users need to be able to communicate their queries effectively without specialized knowledge of SQL. However, further research is needed to address the model's current limitations and increase its robustness across a wider range of use cases.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!SelECT-SQL: Self-correcting ensemble Chain-of-Thought for Text-to-SQL
Ke Shen, Mayank Kejriwal
In recent years,Text-to-SQL, the problem of automatically converting questions posed in natural language to formal SQL queries, has emerged as an important problem at the intersection of natural language processing and data management research. Large language models (LLMs) have delivered impressive performance when used in an off-the-shelf performance, but still fall significantly short of expected expert-level performance. Errors are especially probable when a nuanced understanding is needed of database schemas, questions, and SQL clauses to do proper Text-to-SQL conversion. We introduce SelECT-SQL, a novel in-context learning solution that uses an algorithmic combination of chain-of-thought (CoT) prompting, self-correction, and ensemble methods to yield a new state-of-the-art result on challenging Text-to-SQL benchmarks. Specifically, when configured using GPT-3.5-Turbo as the base LLM, SelECT-SQL achieves 84.2% execution accuracy on the Spider leaderboard's development set, exceeding both the best results of other baseline GPT-3.5-Turbo-based solutions (81.1%), and the peak performance (83.5%) of the GPT-4 result reported on the leaderboard.
Read more9/17/2024

0
CoE-SQL: In-Context Learning for Multi-Turn Text-to-SQL with Chain-of-Editions
Hanchong Zhang, Ruisheng Cao, Hongshen Xu, Lu Chen, Kai Yu
Recently, Large Language Models (LLMs) have been demonstrated to possess impressive capabilities in a variety of domains and tasks. We investigate the issue of prompt design in the multi-turn text-to-SQL task and attempt to enhance the LLMs' reasoning capacity when generating SQL queries. In the conversational context, the current SQL query can be modified from the preceding SQL query with only a few operations due to the context dependency. We introduce our method called CoE-SQL which can prompt LLMs to generate the SQL query based on the previously generated SQL query with an edition chain. We also conduct extensive ablation studies to determine the optimal configuration of our approach. Our approach outperforms different in-context learning baselines stably and achieves state-of-the-art performances on two benchmarks SParC and CoSQL using LLMs, which is also competitive to the SOTA fine-tuned models.
Read more5/7/2024
0
Next-Generation Database Interfaces: A Survey of LLM-based Text-to-SQL
Zijin Hong, Zheng Yuan, Qinggang Zhang, Hao Chen, Junnan Dong, Feiran Huang, Xiao Huang
Generating accurate SQL from natural language questions (text-to-SQL) is a long-standing challenge due to the complexities in user question understanding, database schema comprehension, and SQL generation. Conventional text-to-SQL systems, comprising human engineering and deep neural networks, have made substantial progress. Subsequently, pre-trained language models (PLMs) have been developed and utilized for text-to-SQL tasks, achieving promising performance. As modern databases become more complex, the corresponding user questions also grow more challenging, causing PLMs with parameter constraints to produce incorrect SQL. This necessitates more sophisticated and tailored optimization methods, which, in turn, restricts the applications of PLM-based systems. Recently, large language models (LLMs) have demonstrated significant capabilities in natural language understanding as the model scale increases. Therefore, integrating LLM-based implementation can bring unique opportunities, improvements, and solutions to text-to-SQL research. In this survey, we present a comprehensive review of LLM-based text-to-SQL. Specifically, we propose a brief overview of the technical challenges and the evolutionary process of text-to-SQL. Then, we provide a detailed introduction to the datasets and metrics designed to evaluate text-to-SQL systems. After that, we present a systematic analysis of recent advances in LLM-based text-to-SQL. Finally, we discuss the remaining challenges in this field and propose expectations for future research directions.
Read more7/17/2024

0
CHESS: Contextual Harnessing for Efficient SQL Synthesis
Shayan Talaei, Mohammadreza Pourreza, Yu-Chen Chang, Azalia Mirhoseini, Amin Saberi
Utilizing large language models (LLMs) for transforming natural language questions into SQL queries (text-to-SQL) is a promising yet challenging approach, particularly when applied to real-world databases with complex and extensive schemas. In particular, effectively incorporating data catalogs and database values for SQL generation remains an obstacle, leading to suboptimal solutions. We address this problem by proposing a new pipeline that effectively retrieves relevant data and context, selects an efficient schema, and synthesizes correct and efficient SQL queries. To increase retrieval precision, our pipeline introduces a hierarchical retrieval method leveraging model-generated keywords, locality-sensitive hashing indexing, and vector databases. Additionally, we have developed an adaptive schema pruning technique that adjusts based on the complexity of the problem and the model's context size. Our approach generalizes to both frontier proprietary models like GPT-4 and open-source models such as Llama-3-70B. Through a series of ablation studies, we demonstrate the effectiveness of each component of our pipeline and its impact on the end-to-end performance. Our method achieves new state-of-the-art performance on the cross-domain challenging BIRD dataset.
Read more6/28/2024