Selective Amnesia: On Efficient, High-Fidelity and Blind Suppression of Backdoor Effects in Trojaned Machine Learning Models

0
➖
Sign in to get full access
Overview
- The paper presents a technique called SEAM (Selective Amnesia) to remove backdoors in deep neural network models.
- SEAM leverages the problem of catastrophic forgetting (CF) in continual learning to induce sudden forgetting of both the primary and backdoor tasks.
- The authors analyze SEAM by modeling the unlearning process as continual learning and using the Neural Tangent Kernel to measure catastrophic forgetting.
- Experiments show SEAM vastly outperforms state-of-the-art unlearning techniques, achieving high fidelity (accuracy on primary task vs. backdoor) in a short time using little clean data.
Plain English Explanation
Backdoors in machine learning models are a serious security risk - they allow attackers to manipulate the model's behavior by triggering a specific input. <a href="https://aimodels.fyi/papers/arxiv/flatness-aware-sequential-learning-generates-resilient-backdoors">Backdoor attacks</a> can be difficult to detect and remove.
The researchers behind this paper developed a technique called SEAM (Selective Amnesia) to address this problem. The key idea is to "forget" the backdoor by exploiting a phenomenon called catastrophic forgetting (CF) in continual learning.
Catastrophic forgetting happens when a model learns a new task and completely forgets how to do a previous task. The researchers realized they could use this to their advantage - by retraining the model on randomly labeled data, they could induce catastrophic forgetting of both the primary task and the backdoor. Then, they could recover the primary task by retraining on the correct data.
<a href="https://aimodels.fyi/papers/arxiv/mitigating-backdoor-attacks-using-activation-guided-model">Their analysis</a> showed that this random-labeling approach maximizes the forgetting of the backdoor while preserving enough of the model's features to quickly revive the primary task. Experiments on image and natural language processing tasks demonstrated that SEAM outperforms other backdoor removal techniques, achieving high fidelity (primary task accuracy vs. backdoor) in a short time using very little clean data.
Technical Explanation
The authors model the SEAM unlearning process as a form of continual learning, where the model learns a series of tasks in sequence. They approximate the DNN using the Neural Tangent Kernel (NTK) to analyze the catastrophic forgetting dynamics.
Their analysis shows that randomly relabeling the training data maximizes the catastrophic forgetting of the backdoor task, while preserving enough of the model's feature extraction capabilities to enable a fast revival of the primary task through additional training on clean data.
The experiments evaluated SEAM on both image processing and natural language processing tasks, under both data contamination and training manipulation attacks. SEAM was tested on thousands of models, including those from the TrojAI competition. The results demonstrate that SEAM vastly outperforms state-of-the-art unlearning techniques, achieving high fidelity (small gap between primary task and backdoor accuracies) in a short time (about 30 times faster than training from scratch on MNIST) using only a small amount of clean data (0.1% of the original training data for TrojAI models).
Critical Analysis
The paper provides a thorough analysis of the SEAM technique and its performance, but there are a few potential limitations and areas for further research:
-
<a href="https://aimodels.fyi/papers/arxiv/backdoor-removal-generative-large-language-models">The reliance on clean data</a> - SEAM requires a small amount of clean data to revive the primary task after inducing catastrophic forgetting. In real-world scenarios, clean data may not always be available.
-
<a href="https://aimodels.fyi/papers/arxiv/backdoor-attack-prompt-based-continual-learning">Generalization to other types of backdoors</a> - The paper focuses on backdoors triggered by specific input patterns. More research is needed to understand SEAM's effectiveness against other backdoor attack vectors, such as <a href="https://aimodels.fyi/papers/arxiv/flatness-aware-sequential-learning-generates-resilient-backdoors">backdoors in the model parameters</a>.
-
<a href="https://aimodels.fyi/papers/arxiv/mitigating-backdoor-attacks-using-activation-guided-model">Potential for unintended consequences</a> - While SEAM appears effective at removing backdoors, the drastic forgetting of the primary task could lead to unintended consequences or performance degradation that should be carefully evaluated.
Overall, the SEAM technique shows promise as a practical approach to mitigating backdoor attacks, but further research is needed to address its limitations and explore its broader applicability.
Conclusion
This paper presents a novel technique called SEAM (Selective Amnesia) that can effectively remove backdoors from deep neural network models. By exploiting the phenomenon of catastrophic forgetting in continual learning, SEAM is able to induce sudden forgetting of both the primary task and the backdoor, and then quickly revive the primary task using a small amount of clean data.
The authors' analysis and experimental results demonstrate that SEAM outperforms other state-of-the-art unlearning techniques, achieving high fidelity (primary task accuracy vs. backdoor) in a short time using minimal clean data. This makes SEAM a promising approach for securing deep learning models against backdoor attacks, which are a significant security risk in real-world applications.
While SEAM has some limitations, such as the reliance on clean data and the need for further evaluation against other types of backdoors, this research represents an important step forward in the ongoing effort to build more robust and trustworthy machine learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
➖
0
Selective Amnesia: On Efficient, High-Fidelity and Blind Suppression of Backdoor Effects in Trojaned Machine Learning Models
Rui Zhu, Di Tang, Siyuan Tang, XiaoFeng Wang, Haixu Tang
In this paper, we present a simple yet surprisingly effective technique to induce selective amnesia on a backdoored model. Our approach, called SEAM, has been inspired by the problem of catastrophic forgetting (CF), a long standing issue in continual learning. Our idea is to retrain a given DNN model on randomly labeled clean data, to induce a CF on the model, leading to a sudden forget on both primary and backdoor tasks; then we recover the primary task by retraining the randomized model on correctly labeled clean data. We analyzed SEAM by modeling the unlearning process as continual learning and further approximating a DNN using Neural Tangent Kernel for measuring CF. Our analysis shows that our random-labeling approach actually maximizes the CF on an unknown backdoor in the absence of triggered inputs, and also preserves some feature extraction in the network to enable a fast revival of the primary task. We further evaluated SEAM on both image processing and Natural Language Processing tasks, under both data contamination and training manipulation attacks, over thousands of models either trained on popular image datasets or provided by the TrojAI competition. Our experiments show that SEAM vastly outperforms the state-of-the-art unlearning techniques, achieving a high Fidelity (measuring the gap between the accuracy of the primary task and that of the backdoor) within a few minutes (about 30 times faster than training a model from scratch using the MNIST dataset), with only a small amount of clean data (0.1% of training data for TrojAI models).
Read more7/23/2024
0
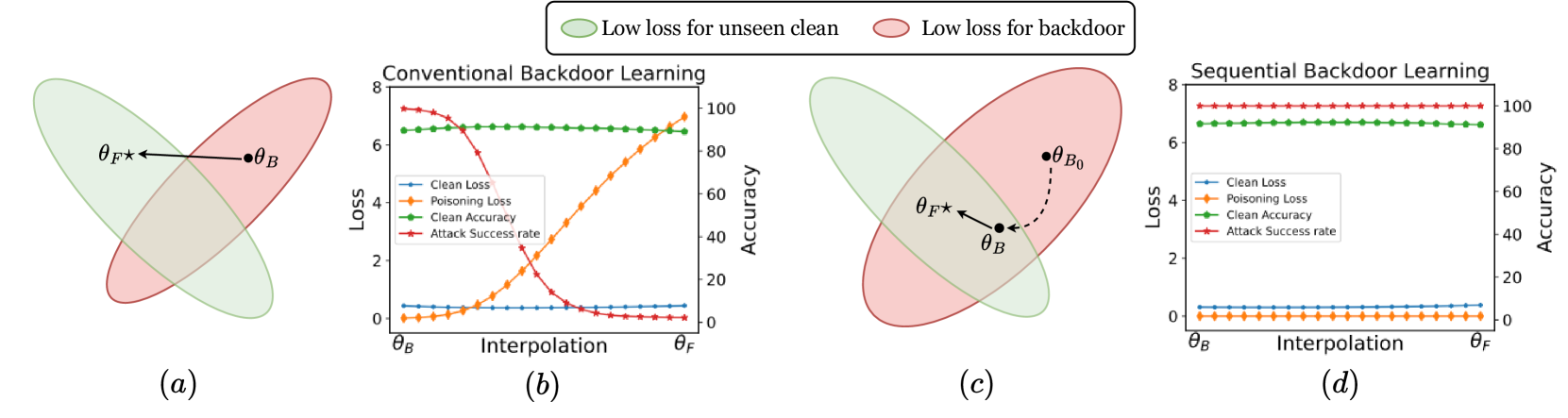
Flatness-aware Sequential Learning Generates Resilient Backdoors
Hoang Pham, The-Anh Ta, Anh Tran, Khoa D. Doan
Recently, backdoor attacks have become an emerging threat to the security of machine learning models. From the adversary's perspective, the implanted backdoors should be resistant to defensive algorithms, but some recently proposed fine-tuning defenses can remove these backdoors with notable efficacy. This is mainly due to the catastrophic forgetting (CF) property of deep neural networks. This paper counters CF of backdoors by leveraging continual learning (CL) techniques. We begin by investigating the connectivity between a backdoored and fine-tuned model in the loss landscape. Our analysis confirms that fine-tuning defenses, especially the more advanced ones, can easily push a poisoned model out of the backdoor regions, making it forget all about the backdoors. Based on this finding, we re-formulate backdoor training through the lens of CL and propose a novel framework, named Sequential Backdoor Learning (SBL), that can generate resilient backdoors. This framework separates the backdoor poisoning process into two tasks: the first task learns a backdoored model, while the second task, based on the CL principles, moves it to a backdoored region resistant to fine-tuning. We additionally propose to seek flatter backdoor regions via a sharpness-aware minimizer in the framework, further strengthening the durability of the implanted backdoor. Finally, we demonstrate the effectiveness of our method through extensive empirical experiments on several benchmark datasets in the backdoor domain. The source code is available at https://github.com/mail-research/SBL-resilient-backdoors
Read more7/23/2024

0
Persistent Backdoor Attacks in Continual Learning
Zhen Guo, Abhinav Kumar, Reza Tourani
Backdoor attacks pose a significant threat to neural networks, enabling adversaries to manipulate model outputs on specific inputs, often with devastating consequences, especially in critical applications. While backdoor attacks have been studied in various contexts, little attention has been given to their practicality and persistence in continual learning, particularly in understanding how the continual updates to model parameters, as new data distributions are learned and integrated, impact the effectiveness of these attacks over time. To address this gap, we introduce two persistent backdoor attacks-Blind Task Backdoor and Latent Task Backdoor-each leveraging minimal adversarial influence. Our blind task backdoor subtly alters the loss computation without direct control over the training process, while the latent task backdoor influences only a single task's training, with all other tasks trained benignly. We evaluate these attacks under various configurations, demonstrating their efficacy with static, dynamic, physical, and semantic triggers. Our results show that both attacks consistently achieve high success rates across different continual learning algorithms, while effectively evading state-of-the-art defenses, such as SentiNet and I-BAU.
Read more9/24/2024
0
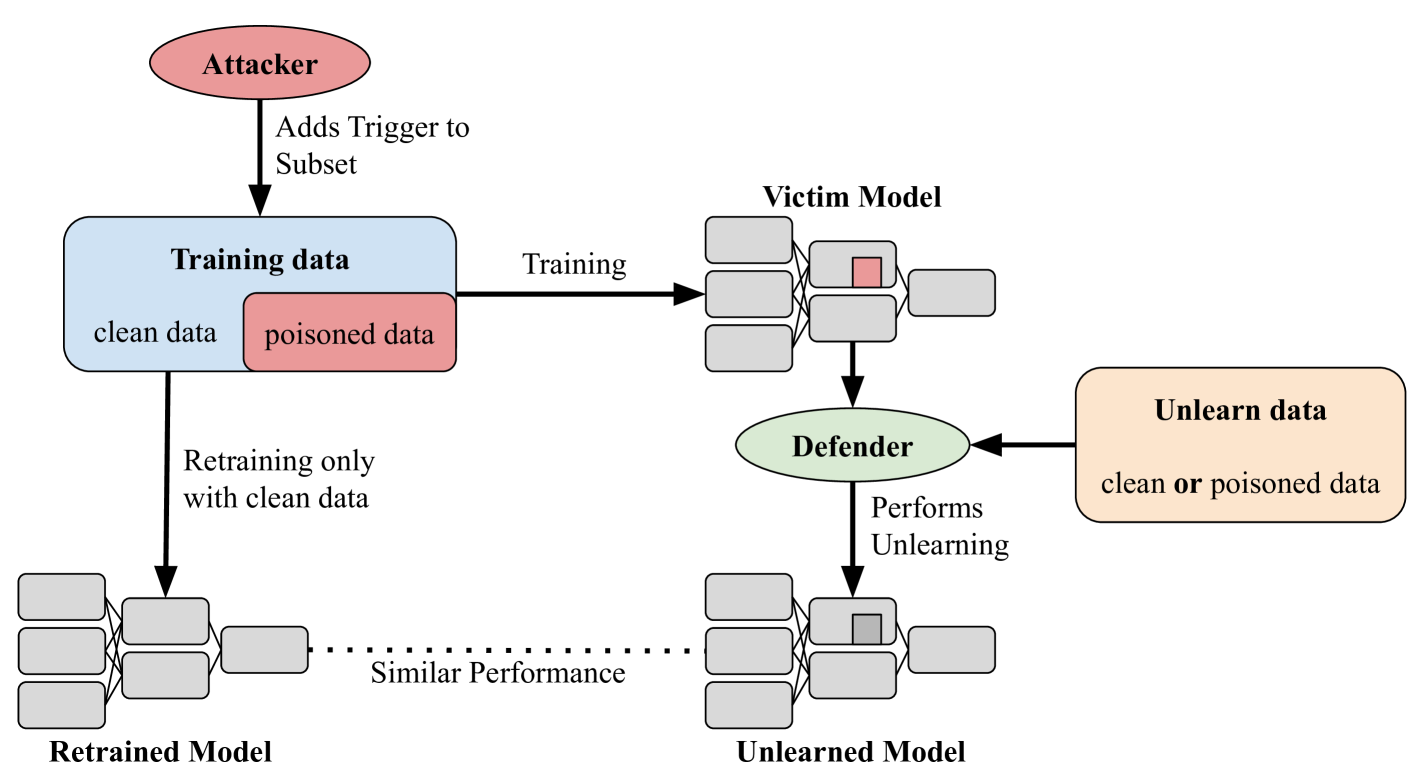
Mitigating Backdoor Attacks using Activation-Guided Model Editing
Felix Hsieh, Huy H. Nguyen, AprilPyone MaungMaung, Dmitrii Usynin, Isao Echizen
Backdoor attacks compromise the integrity and reliability of machine learning models by embedding a hidden trigger during the training process, which can later be activated to cause unintended misbehavior. We propose a novel backdoor mitigation approach via machine unlearning to counter such backdoor attacks. The proposed method utilizes model activation of domain-equivalent unseen data to guide the editing of the model's weights. Unlike the previous unlearning-based mitigation methods, ours is computationally inexpensive and achieves state-of-the-art performance while only requiring a handful of unseen samples for unlearning. In addition, we also point out that unlearning the backdoor may cause the whole targeted class to be unlearned, thus introducing an additional repair step to preserve the model's utility after editing the model. Experiment results show that the proposed method is effective in unlearning the backdoor on different datasets and trigger patterns.
Read more7/11/2024