Selective-Memory Meta-Learning with Environment Representations for Sound Event Localization and Detection

0

Sign in to get full access
Overview
- This paper presents a new meta-learning approach for sound event localization and detection (SELD) tasks.
- The key ideas are:
- Leveraging environment representations to adapt a model to new acoustic environments.
- Using a selective memory mechanism to retain relevant knowledge from past experiences.
- The proposed method achieves state-of-the-art performance on SELD benchmarks.
Plain English Explanation
The paper focuses on the problem of sound event localization and detection (SELD). SELD involves identifying where and when different sounds occur in an audio recording. This is a challenging task because sound events can vary significantly based on the environment they occur in.
To address this, the researchers developed a new meta-learning approach. Meta-learning allows a model to quickly adapt to new tasks or environments by learning how to learn. In this case, the model learns to adapt to new acoustic environments.
The key innovations are:
-
Environment Representations: The model learns to represent the characteristics of the acoustic environment, such as the room size, materials, and background noise. This allows the model to tailor its behavior to the specific environment.
-
Selective Memory: The model has a selective memory mechanism that helps it retain relevant knowledge from past environments, while forgetting less useful information. This allows the model to build up a useful knowledge base over time.
By combining these two ideas, the model is able to efficiently adapt to new sound environments and achieve state-of-the-art performance on SELD benchmarks. This could have important applications in areas like audio-visual information fusion for smart home assistants or distance estimation for autonomous vehicles.
Technical Explanation
The paper proposes a selective-memory meta-learning approach for SELD tasks. The key components are:
Environment Representation: The model learns to represent the acoustic environment of each task using a neural network. This environment representation captures features like room size, materials, and background noise that affect the characteristics of sound events.
Selective Memory: The model maintains a memory buffer that stores relevant knowledge from past tasks. A selective memory mechanism determines which experiences to retain or forget based on their relevance to the current task.
Meta-Learning: The model is trained using a meta-learning approach, where it learns to quickly adapt its parameters to new environments by leveraging the environment representation and selective memory.
During training, the model is exposed to a diverse set of acoustic environments. It learns to extract the relevant environmental features and selectively store useful knowledge in its memory. When faced with a new environment, the model can rapidly adapt by retrieving the most relevant information from its memory and adjusting its internal representation accordingly.
The experiments demonstrate that this selective-memory meta-learning approach outperforms previous state-of-the-art SELD methods on benchmark datasets. The model is able to more effectively leverage past experiences to handle the wide variability in acoustic environments.
Critical Analysis
The paper presents a compelling approach to SELD that addresses an important practical challenge - the ability to adapt to diverse acoustic environments. The use of environment representations and selective memory mechanisms are well-motivated and the experimental results are promising.
However, the paper could have explored some additional avenues:
-
Interpretability: The paper does not provide much insight into what specific environmental features the model is learning to represent and how these features influence the model's behavior. Increased interpretability could help users better understand the model's decision-making process.
-
Scalability: The experiments are conducted on relatively small-scale datasets. It would be valuable to see how the approach scales to larger, more diverse acoustic environments encountered in real-world applications.
-
Computational Efficiency: The additional components introduced by the meta-learning approach may incur additional computational overhead. The paper could have discussed the tradeoffs between performance gains and increased inference latency or model size.
-
Generalization: The paper focuses on adapting to new environments, but does not explore the model's ability to generalize to completely novel sound event types or scenarios not seen during training. This could be an interesting area for future research.
Overall, this paper presents an innovative approach that successfully leverages environment representations and selective memory to improve SELD performance. The ideas have the potential for broader applications in other domains that require rapid adaptation to changing conditions.
Conclusion
This paper introduces a selective-memory meta-learning approach for sound event localization and detection (SELD) that enables a model to effectively adapt to diverse acoustic environments. By learning environment representations and selectively retaining relevant past experiences, the model can quickly adjust to new settings and outperform previous state-of-the-art SELD methods.
The proposed techniques have the potential for significant real-world impact, as they could enable more robust and adaptive sound sensing systems for applications like smart home assistants, autonomous vehicles, and surveillance. Further research into the interpretability, scalability, and generalization capabilities of this approach could yield valuable insights and unlock even more applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Selective-Memory Meta-Learning with Environment Representations for Sound Event Localization and Detection
Jinbo Hu, Yin Cao, Ming Wu, Qiuqiang Kong, Feiran Yang, Mark D. Plumbley, Jun Yang
Environment shifts and conflicts present significant challenges for learning-based sound event localization and detection (SELD) methods. SELD systems, when trained in particular acoustic settings, often show restricted generalization capabilities for diverse acoustic environments. Furthermore, obtaining annotated samples for spatial sound events is notably costly. Deploying a SELD system in a new environment requires extensive time for re-training and fine-tuning. To overcome these challenges, we propose environment-adaptive Meta-SELD, designed for efficient adaptation to new environments using minimal data. Our method specifically utilizes computationally synthesized spatial data and employs Model-Agnostic Meta-Learning (MAML) on a pre-trained, environment-independent model. The method then utilizes fast adaptation to unseen real-world environments using limited samples from the respective environments. Inspired by the Learning-to-Forget approach, we introduce the concept of selective memory as a strategy for resolving conflicts across environments. This approach involves selectively memorizing target-environment-relevant information and adapting to the new environments through the selective attenuation of model parameters. In addition, we introduce environment representations to characterize different acoustic settings, enhancing the adaptability of our attenuation approach to various environments. We evaluate our proposed method on the development set of the Sony-TAu Realistic Spatial Soundscapes 2023 (STARSS23) dataset and computationally synthesized scenes. Experimental results demonstrate the superior performance of the proposed method compared to conventional supervised learning methods, particularly in localization.
Read more8/23/2024

0
SELD-Mamba: Selective State-Space Model for Sound Event Localization and Detection with Source Distance Estimation
Da Mu, Zhicheng Zhang, Haobo Yue, Zehao Wang, Jin Tang, Jianqin Yin
In the Sound Event Localization and Detection (SELD) task, Transformer-based models have demonstrated impressive capabilities. However, the quadratic complexity of the Transformer's self-attention mechanism results in computational inefficiencies. In this paper, we propose a network architecture for SELD called SELD-Mamba, which utilizes Mamba, a selective state-space model. We adopt the Event-Independent Network V2 (EINV2) as the foundational framework and replace its Conformer blocks with bidirectional Mamba blocks to capture a broader range of contextual information while maintaining computational efficiency. Additionally, we implement a two-stage training method, with the first stage focusing on Sound Event Detection (SED) and Direction of Arrival (DoA) estimation losses, and the second stage reintroducing the Source Distance Estimation (SDE) loss. Our experimental results on the 2024 DCASE Challenge Task3 dataset demonstrate the effectiveness of the selective state-space model in SELD and highlight the benefits of the two-stage training approach in enhancing SELD performance.
Read more8/12/2024
0
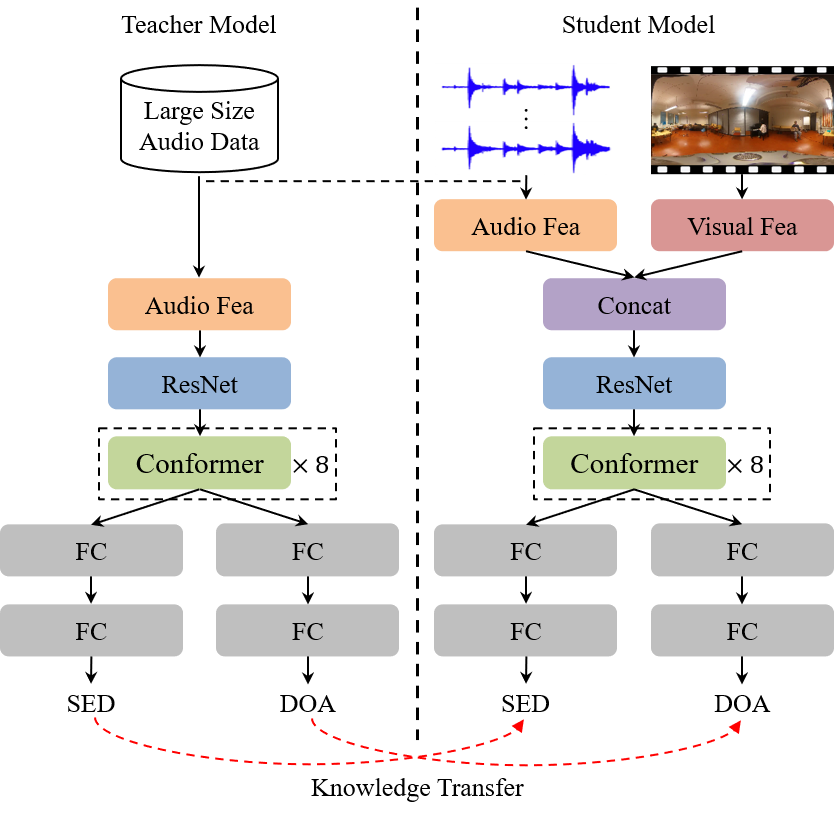
Exploring Audio-Visual Information Fusion for Sound Event Localization and Detection In Low-Resource Realistic Scenarios
Ya Jiang, Qing Wang, Jun Du, Maocheng Hu, Pengfei Hu, Zeyan Liu, Shi Cheng, Zhaoxu Nian, Yuxuan Dong, Mingqi Cai, Xin Fang, Chin-Hui Lee
This study presents an audio-visual information fusion approach to sound event localization and detection (SELD) in low-resource scenarios. We aim at utilizing audio and video modality information through cross-modal learning and multi-modal fusion. First, we propose a cross-modal teacher-student learning (TSL) framework to transfer information from an audio-only teacher model, trained on a rich collection of audio data with multiple data augmentation techniques, to an audio-visual student model trained with only a limited set of multi-modal data. Next, we propose a two-stage audio-visual fusion strategy, consisting of an early feature fusion and a late video-guided decision fusion to exploit synergies between audio and video modalities. Finally, we introduce an innovative video pixel swapping (VPS) technique to extend an audio channel swapping (ACS) method to an audio-visual joint augmentation. Evaluation results on the Detection and Classification of Acoustic Scenes and Events (DCASE) 2023 Challenge data set demonstrate significant improvements in SELD performances. Furthermore, our submission to the SELD task of the DCASE 2023 Challenge ranks first place by effectively integrating the proposed techniques into a model ensemble.
Read more6/24/2024
0
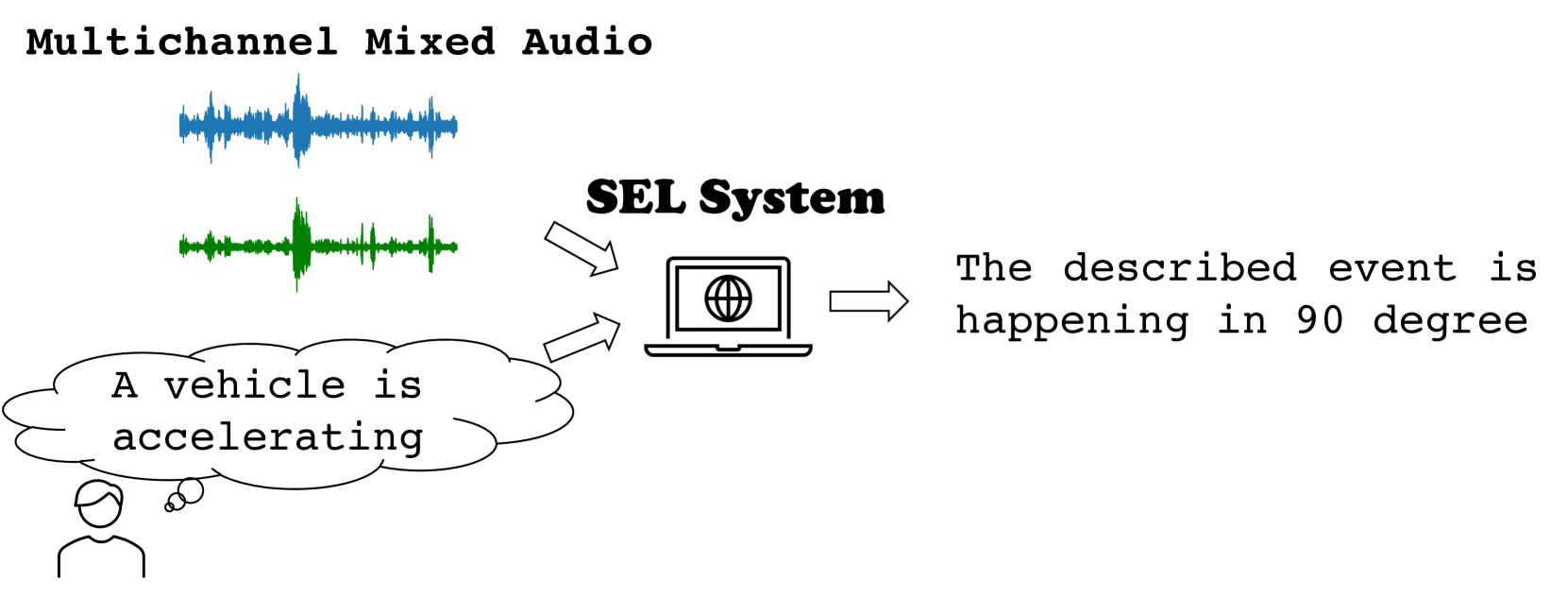
Text-Queried Target Sound Event Localization
Jinzheng Zhao, Xinyuan Qian, Yong Xu, Haohe Liu, Yin Cao, Davide Berghi, Wenwu Wang
Sound event localization and detection (SELD) aims to determine the appearance of sound classes, together with their Direction of Arrival (DOA). However, current SELD systems can only predict the activities of specific classes, for example, 13 classes in DCASE challenges. In this paper, we propose text-queried target sound event localization (SEL), a new paradigm that allows the user to input the text to describe the sound event, and the SEL model can predict the location of the related sound event. The proposed task presents a more user-friendly way for human-computer interaction. We provide a benchmark study for the proposed task and perform experiments on datasets created by simulated room impulse response (RIR) and real RIR to validate the effectiveness of the proposed methods. We hope that our benchmark will inspire the interest and additional research for text-queried sound source localization.
Read more6/25/2024