SELD-Mamba: Selective State-Space Model for Sound Event Localization and Detection with Source Distance Estimation

0

Sign in to get full access
Overview
- SELD-Mamba is a model for Sound Event Localization and Detection (SELD) that incorporates source distance estimation
- It builds on the Mamba architecture, a selective state-space model for sound event detection
- The key contributions include a new state-space formulation, a distance estimation module, and a multi-task training approach
Plain English Explanation
SELD-Mamba: Selective State-Space Model for Sound Event Localization and Detection with Source Distance Estimation describes a system that can identify and locate sound events, as well as estimate the distance to the sound sources. This builds on the Mamba architecture, which uses a selective state-space model for sound event detection.
The key idea is to extend the Mamba model to also estimate the distance to the sound sources, in addition to detecting and locating them. This is done by introducing a new state-space formulation and a dedicated distance estimation module. The model is trained in a multi-task fashion, jointly optimizing for sound event detection, localization, and distance estimation.
By incorporating distance estimation, SELD-Mamba can provide more complete information about the sound events in a scene, which could be useful for applications like robot audition, smart home management, and acoustic surveillance.
Technical Explanation
SELD-Mamba builds on the Mamba architecture, which uses a selective state-space model for sound event detection. The key innovations in SELD-Mamba include:
-
New State-Space Formulation: The authors introduce a new state-space formulation that incorporates both the sound event detection and localization states, as well as a distance estimation state.
-
Distance Estimation Module: SELD-Mamba includes a dedicated module for estimating the distance to the sound sources. This module takes the localization output and produces a distance estimate.
-
Multi-Task Training: The model is trained in a multi-task fashion, jointly optimizing for sound event detection, localization, and distance estimation. This allows the model to leverage the synergies between these related tasks.
The authors evaluate SELD-Mamba on standard SELD benchmarks and show that it outperforms previous state-of-the-art methods, particularly in terms of distance estimation accuracy.
Critical Analysis
The SELD-Mamba paper makes a solid contribution by extending the Mamba architecture to include source distance estimation. This additional capability could be valuable for many real-world applications.
However, the paper does not discuss the potential limitations or challenges of the distance estimation module. It would be helpful to understand the factors that can affect distance estimation accuracy, such as reverberation, sound source characteristics, and sensor placement. Additionally, the authors could have explored the robustness of the distance estimates under different acoustic conditions.
Further research could also investigate the trade-offs between the additional complexity of the distance estimation module and the benefits it provides. It would be interesting to see how SELD-Mamba compares to simpler approaches that focus solely on sound event detection and localization.
Conclusion
SELD-Mamba presents a novel extension of the Mamba architecture that adds the capability to estimate the distance to sound sources, in addition to detecting and localizing sound events. This could be a valuable addition for applications that require a more comprehensive understanding of the acoustic scene.
The technical innovations, including the new state-space formulation and the dedicated distance estimation module, demonstrate the researchers' thoughtful approach to addressing this problem. While the paper does not fully explore the limitations of the distance estimation component, it provides a strong foundation for further research and development in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SELD-Mamba: Selective State-Space Model for Sound Event Localization and Detection with Source Distance Estimation
Da Mu, Zhicheng Zhang, Haobo Yue, Zehao Wang, Jin Tang, Jianqin Yin
In the Sound Event Localization and Detection (SELD) task, Transformer-based models have demonstrated impressive capabilities. However, the quadratic complexity of the Transformer's self-attention mechanism results in computational inefficiencies. In this paper, we propose a network architecture for SELD called SELD-Mamba, which utilizes Mamba, a selective state-space model. We adopt the Event-Independent Network V2 (EINV2) as the foundational framework and replace its Conformer blocks with bidirectional Mamba blocks to capture a broader range of contextual information while maintaining computational efficiency. Additionally, we implement a two-stage training method, with the first stage focusing on Sound Event Detection (SED) and Direction of Arrival (DoA) estimation losses, and the second stage reintroducing the Source Distance Estimation (SDE) loss. Our experimental results on the 2024 DCASE Challenge Task3 dataset demonstrate the effectiveness of the selective state-space model in SELD and highlight the benefits of the two-stage training approach in enhancing SELD performance.
Read more8/12/2024
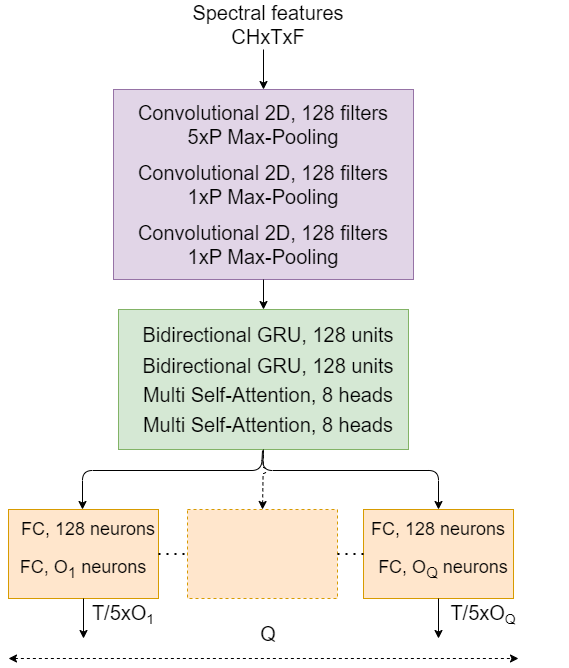
0
Sound Event Detection and Localization with Distance Estimation
Daniel Aleksander Krause, Archontis Politis, Annamaria Mesaros
Sound Event Detection and Localization (SELD) is a combined task of identifying sound events and their corresponding direction-of-arrival (DOA). While this task has numerous applications and has been extensively researched in recent years, it fails to provide full information about the sound source position. In this paper, we overcome this problem by extending the task to Sound Event Detection, Localization with Distance Estimation (3D SELD). We study two ways of integrating distance estimation within the SELD core - a multi-task approach, in which the problem is tackled by a separate model output, and a single-task approach obtained by extending the multi-ACCDOA method to include distance information. We investigate both methods for the Ambisonic and binaural versions of STARSS23: Sony-TAU Realistic Spatial Soundscapes 2023. Moreover, our study involves experiments on the loss function related to the distance estimation part. Our results show that it is possible to perform 3D SELD without any degradation of performance in sound event detection and DOA estimation.
Read more6/13/2024
0
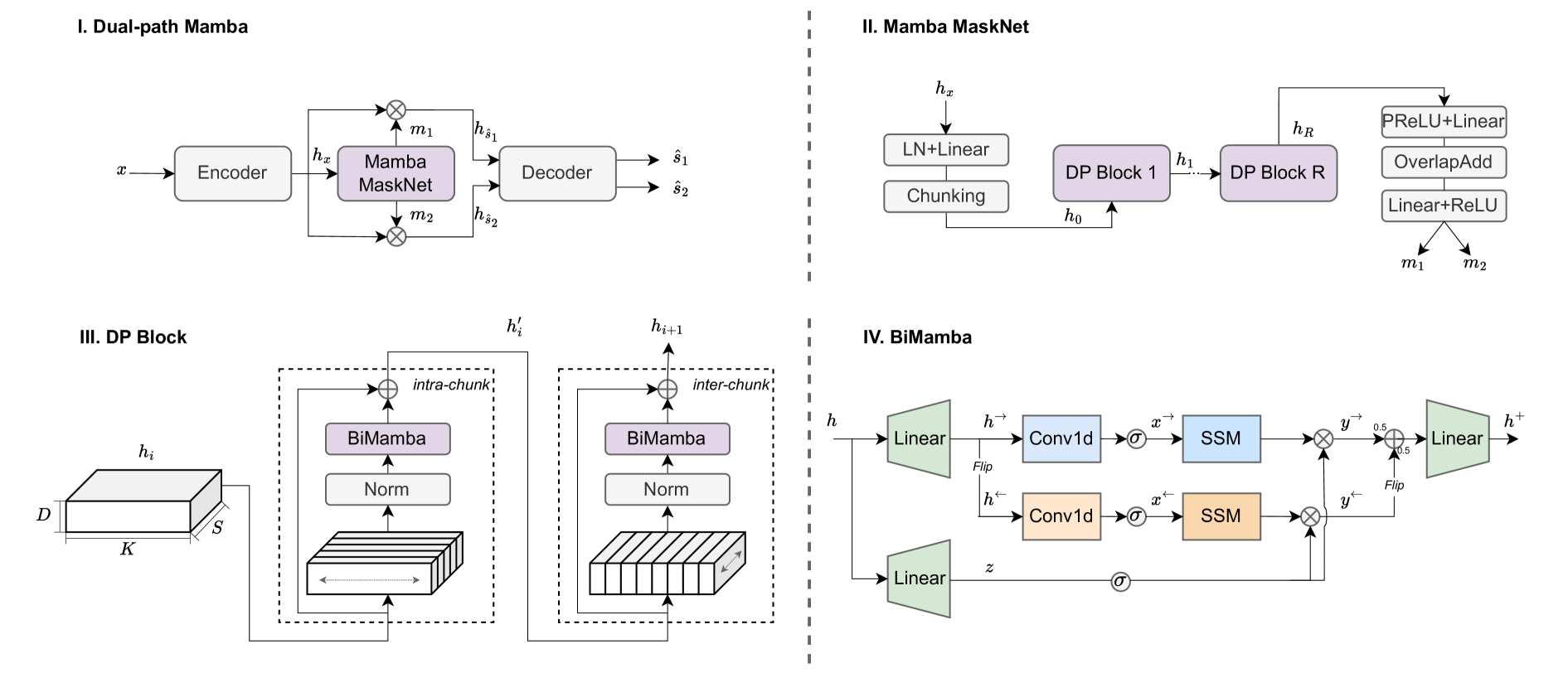
Dual-path Mamba: Short and Long-term Bidirectional Selective Structured State Space Models for Speech Separation
Xilin Jiang, Cong Han, Nima Mesgarani
Transformers have been the most successful architecture for various speech modeling tasks, including speech separation. However, the self-attention mechanism in transformers with quadratic complexity is inefficient in computation and memory. Recent models incorporate new layers and modules along with transformers for better performance but also introduce extra model complexity. In this work, we replace transformers with Mamba, a selective state space model, for speech separation. We propose dual-path Mamba, which models short-term and long-term forward and backward dependency of speech signals using selective state spaces. Our experimental results on the WSJ0-2mix data show that our dual-path Mamba models of comparably smaller sizes outperform state-of-the-art RNN model DPRNN, CNN model WaveSplit, and transformer model Sepformer. Code: https://github.com/xi-j/Mamba-TasNet
Read more5/2/2024
0
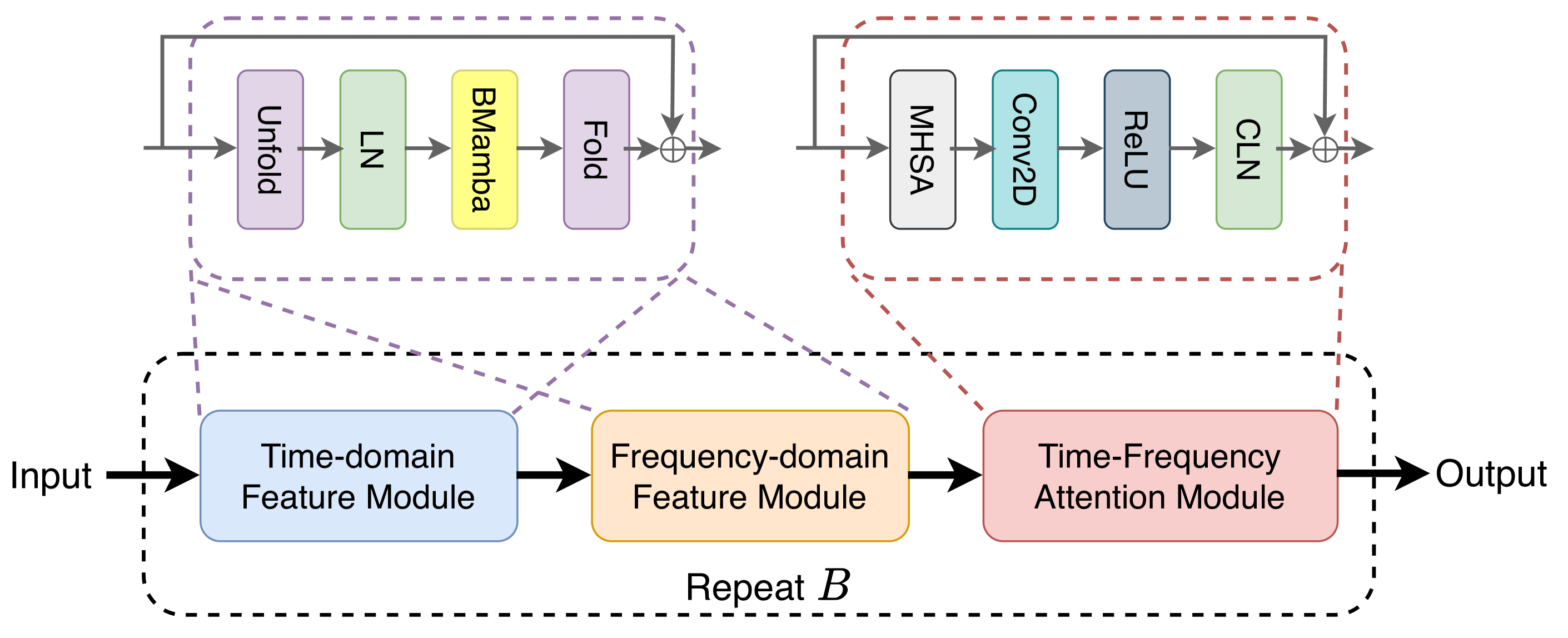
SPMamba: State-space model is all you need in speech separation
Kai Li, Guo Chen, Runxuan Yang, Xiaolin Hu
Existing CNN-based speech separation models face local receptive field limitations and cannot effectively capture long time dependencies. Although LSTM and Transformer-based speech separation models can avoid this problem, their high complexity makes them face the challenge of computational resources and inference efficiency when dealing with long audio. To address this challenge, we introduce an innovative speech separation method called SPMamba. This model builds upon the robust TF-GridNet architecture, replacing its traditional BLSTM modules with bidirectional Mamba modules. These modules effectively model the spatiotemporal relationships between the time and frequency dimensions, allowing SPMamba to capture long-range dependencies with linear computational complexity. Specifically, the bidirectional processing within the Mamba modules enables the model to utilize both past and future contextual information, thereby enhancing separation performance. Extensive experiments conducted on public datasets, including WSJ0-2Mix, WHAM!, and Libri2Mix, as well as the newly constructed Echo2Mix dataset, demonstrated that SPMamba significantly outperformed existing state-of-the-art models, achieving superior results while also reducing computational complexity. These findings highlighted the effectiveness of SPMamba in tackling the intricate challenges of speech separation in complex environments.
Read more9/11/2024