SelectLLM: Query-Aware Efficient Selection Algorithm for Large Language Models

0

Sign in to get full access
Overview
- Presents a query-aware efficient selection algorithm called SelectLLM for large language models
- Aims to improve the efficiency and performance of large language models by selecting the most relevant segments for a given query
- Leverages query-specific information to identify the most relevant parts of the model, reducing computational cost
Plain English Explanation
The paper introduces an algorithm called SelectLLM that helps make large language models more efficient and useful. Large language models are powerful AI systems that can understand and generate human-like text, but they can also be computationally expensive to use.
SelectLLM tries to solve this problem by selecting only the most relevant parts of the language model for a given query or task. This means it can focus the model's attention on the most important information, rather than processing the entire model, which can be slow and resource-intensive.
The key idea behind SelectLLM is that different queries or tasks will require different parts of the language model. By understanding which parts of the model are most relevant for a specific query, the algorithm can selectively activate those parts and ignore the rest, making the overall process more efficient.
This can be especially useful in real-world applications where large language models are used, such as in chatbots, content generation, or language translation. By making the models more efficient, SelectLLM could help these applications run faster, use less computing power, and potentially be more accessible to a wider range of users and devices.
Technical Explanation
The paper presents SelectLLM, a query-aware efficient selection algorithm for large language models. The key idea is to leverage query-specific information to identify the most relevant parts of the language model for a given query, reducing the computational cost of using the model.
The authors first analyze the importance of different parts of the language model for different queries, using techniques like relevance-based feature selection and query-guided model selection. They then use this information to develop a selection algorithm that can efficiently activate only the most relevant parts of the model for a given query.
The SelectLLM algorithm works by first encoding the query using a separate neural network. It then uses this query encoding to select the most relevant tokens or segments from the language model, based on their relevance to the query. This selective activation of the model's parameters allows SelectLLM to achieve significant efficiency gains compared to using the full language model.
The authors evaluate SelectLLM on various benchmarks and find that it can achieve comparable performance to using the full language model, while being 2-4x more efficient in terms of computational cost and memory usage. They also show that SelectLLM is robust to different types of queries and can be easily integrated with different large language models.
Critical Analysis
The SelectLLM algorithm presented in the paper is a promising approach for improving the efficiency of large language models. By selectively activating only the most relevant parts of the model for a given query, the authors are able to achieve significant efficiency gains without sacrificing performance.
One potential limitation of the approach is that it relies on the ability to accurately identify the most relevant parts of the language model for each query. While the authors' techniques for relevance-based feature selection and query-guided model selection seem promising, there may be cases where the query-specific relevance of different model parts is more difficult to determine.
Additionally, the paper does not explore the potential impact of this selective activation on the model's overall robustness or generalization performance. It's possible that by ignoring certain parts of the language model, the model may become less capable of handling unexpected or edge cases.
Despite these potential limitations, the SelectLLM algorithm represents an important step towards making large language models more efficient and accessible in real-world applications. The authors' focus on query-aware optimization is particularly noteworthy, as it suggests a path towards more intelligent and adaptive language model usage.
Conclusion
The SelectLLM algorithm presented in this paper is a significant contribution to the field of large language model optimization. By leveraging query-specific information to selectively activate the most relevant parts of the model, the authors have demonstrated a way to significantly improve the efficiency of these powerful AI systems.
This work has important implications for a wide range of applications, from chatbots and content generation to language translation and beyond. By making large language models more efficient and accessible, SelectLLM could help unlock the full potential of these technologies and make them more widely available to users and developers.
Overall, the SelectLLM algorithm represents an important step forward in the ongoing effort to make large language models more practical and impactful. As the field of AI continues to evolve, research like this will be crucial in ensuring that these powerful tools can be used effectively and efficiently in real-world settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SelectLLM: Query-Aware Efficient Selection Algorithm for Large Language Models
Kaushal Kumar Maurya, KV Aditya Srivatsa, Ekaterina Kochmar
Large language models (LLMs) have gained increased popularity due to their remarkable success across various tasks, which has led to the active development of a large set of diverse LLMs. However, individual LLMs have limitations when applied to complex tasks because of such factors as training biases, model sizes, and the datasets used. A promising approach is to efficiently harness the diverse capabilities of LLMs to overcome these individual limitations. Towards this goal, we introduce a novel LLM selection algorithm called SelectLLM. This algorithm directs input queries to the most suitable subset of LLMs from a large pool, ensuring they collectively provide the correct response efficiently. SelectLLM uses a multi-label classifier, utilizing the classifier's predictions and confidence scores to design optimal policies for selecting an optimal, query-aware, and lightweight subset of LLMs. Our findings show that the proposed model outperforms individual LLMs and achieves competitive performance compared to similarly sized, computationally expensive top-performing LLM subsets. Specifically, with a similarly sized top-performing LLM subset, we achieve a significant reduction in latency on two standard reasoning benchmarks: 13% lower latency for GSM8K and 70% lower latency for MMLU. Additionally, we conduct comprehensive analyses and ablation studies, which validate the robustness of the proposed model.
Read more8/19/2024
0
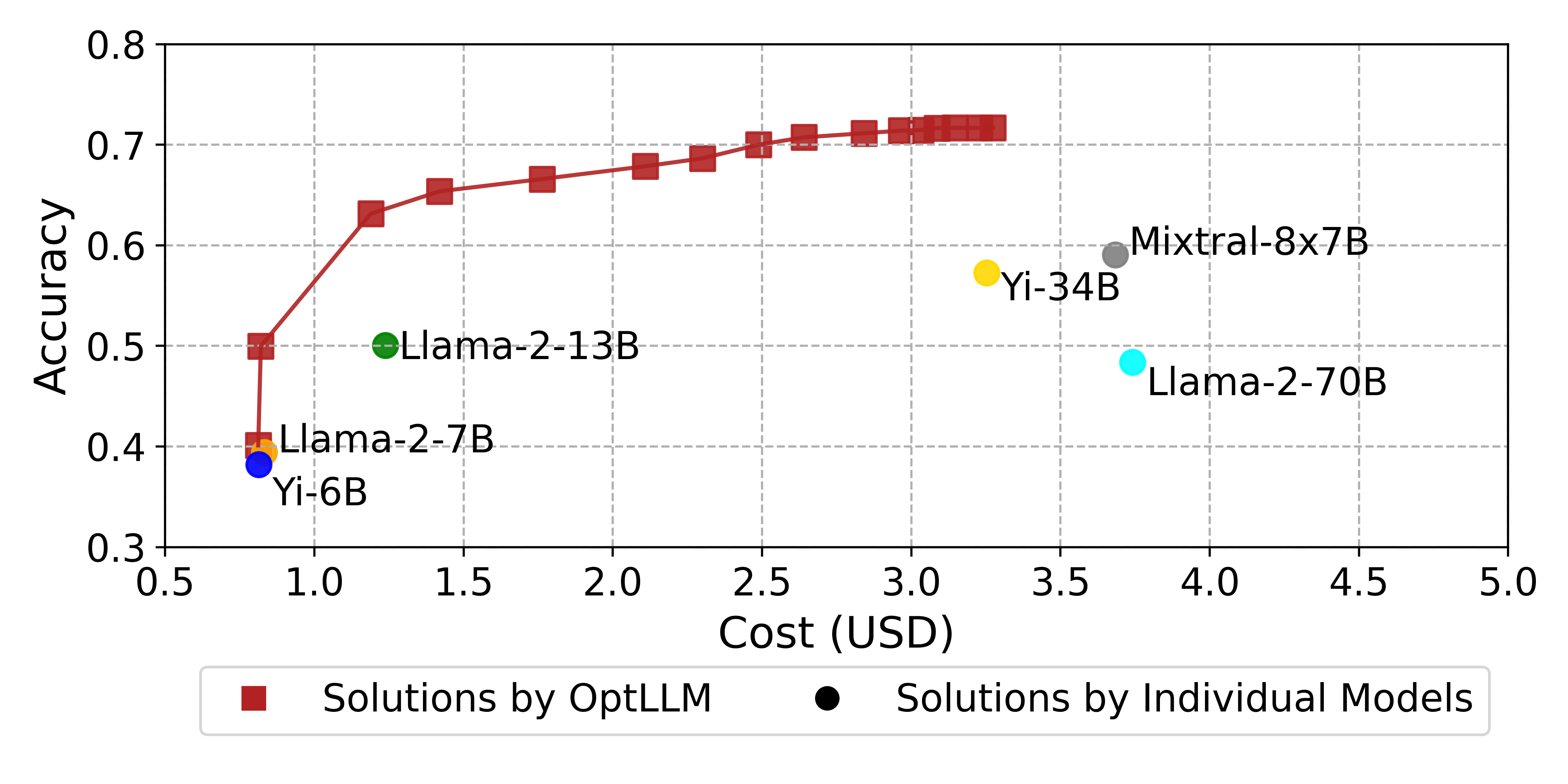
OptLLM: Optimal Assignment of Queries to Large Language Models
Yueyue Liu, Hongyu Zhang, Yuantian Miao, Van-Hoang Le, Zhiqiang Li
Large Language Models (LLMs) have garnered considerable attention owing to their remarkable capabilities, leading to an increasing number of companies offering LLMs as services. Different LLMs achieve different performance at different costs. A challenge for users lies in choosing the LLMs that best fit their needs, balancing cost and performance. In this paper, we propose a framework for addressing the cost-effective query allocation problem for LLMs. Given a set of input queries and candidate LLMs, our framework, named OptLLM, provides users with a range of optimal solutions to choose from, aligning with their budget constraints and performance preferences, including options for maximizing accuracy and minimizing cost. OptLLM predicts the performance of candidate LLMs on each query using a multi-label classification model with uncertainty estimation and then iteratively generates a set of non-dominated solutions by destructing and reconstructing the current solution. To evaluate the effectiveness of OptLLM, we conduct extensive experiments on various types of tasks, including text classification, question answering, sentiment analysis, reasoning, and log parsing. Our experimental results demonstrate that OptLLM substantially reduces costs by 2.40% to 49.18% while achieving the same accuracy as the best LLM. Compared to other multi-objective optimization algorithms, OptLLM improves accuracy by 2.94% to 69.05% at the same cost or saves costs by 8.79% and 95.87% while maintaining the highest attainable accuracy.
Read more5/27/2024

0
LLM-Select: Feature Selection with Large Language Models
Daniel P. Jeong, Zachary C. Lipton, Pradeep Ravikumar
In this paper, we demonstrate a surprising capability of large language models (LLMs): given only input feature names and a description of a prediction task, they are capable of selecting the most predictive features, with performance rivaling the standard tools of data science. Remarkably, these models exhibit this capacity across various query mechanisms. For example, we zero-shot prompt an LLM to output a numerical importance score for a feature (e.g., blood pressure) in predicting an outcome of interest (e.g., heart failure), with no additional context. In particular, we find that the latest models, such as GPT-4, can consistently identify the most predictive features regardless of the query mechanism and across various prompting strategies. We illustrate these findings through extensive experiments on real-world data, where we show that LLM-based feature selection consistently achieves strong performance competitive with data-driven methods such as the LASSO, despite never having looked at the downstream training data. Our findings suggest that LLMs may be useful not only for selecting the best features for training but also for deciding which features to collect in the first place. This could potentially benefit practitioners in domains like healthcare, where collecting high-quality data comes at a high cost.
Read more7/4/2024
0
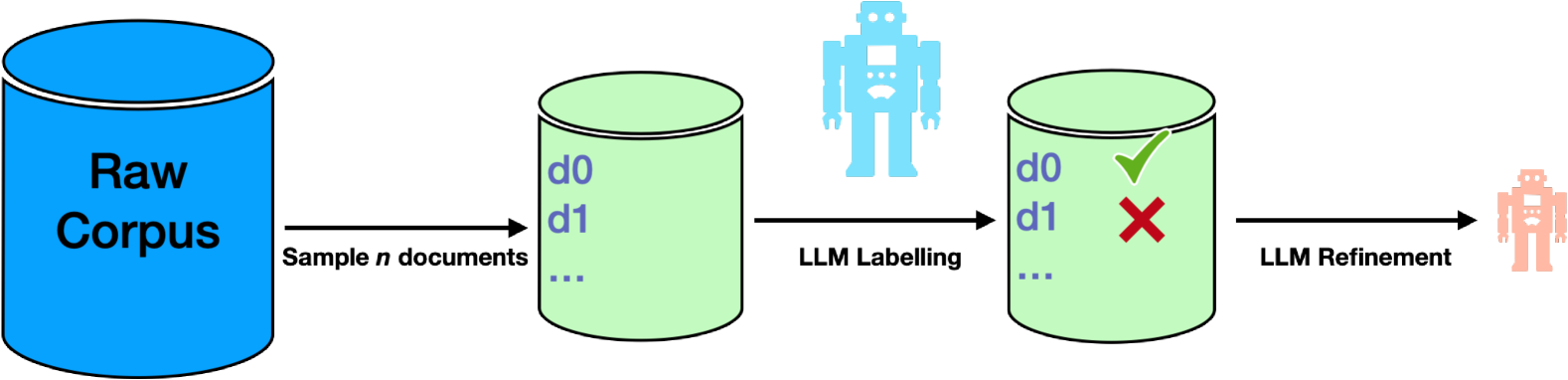
Large Language Model-guided Document Selection
Xiang Kong, Tom Gunter, Ruoming Pang
Large Language Model (LLM) pre-training exhausts an ever growing compute budget, yet recent research has demonstrated that careful document selection enables comparable model quality with only a fraction of the FLOPs. Inspired by efforts suggesting that domain-specific training document selection is in fact an interpretable process [Gunasekar et al., 2023], as well as research showing that instruction-finetuned LLMs are adept zero-shot data labelers [Gilardi et al.,2023], we explore a promising direction for scalable general-domain document selection; employing a prompted LLM as a document grader, we distill quality labels into a classifier model, which is applied at scale to a large, and already heavily-filtered, web-crawl-derived corpus autonomously. Following the guidance of this classifier, we drop 75% of the corpus and train LLMs on the remaining data. Results across multiple benchmarks show that: 1. Filtering allows us to quality-match a model trained on the full corpus across diverse benchmarks with at most 70% of the FLOPs, 2. More capable LLM labelers and classifier models lead to better results that are less sensitive to the labeler's prompt, 3. In-context learning helps to boost the performance of less-capable labeling models. In all cases we use open-source datasets, models, recipes, and evaluation frameworks, so that results can be reproduced by the community.
Read more6/10/2024