LLM-Select: Feature Selection with Large Language Models

0

Sign in to get full access
Overview
- This paper presents a novel feature selection method called LLM-Select that leverages large language models (LLMs) to automatically engineer and select relevant features for machine learning tasks.
- The authors demonstrate that LLM-Select outperforms traditional feature selection techniques on a variety of benchmark datasets, showcasing the potential of LLMs to enhance the feature engineering process.
- The paper also discusses how LLM-Select can be combined with other LLM-based techniques, such as large language model enhanced algorithm selection and large language model guided document selection, to create powerful machine learning pipelines.
Plain English Explanation
Machine learning models often rely on carefully selected features, or characteristics, of the data to make accurate predictions. Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. The authors of this paper discovered that LLMs can also be used to automatically identify the most important features for a machine learning task, a process called feature selection.
Their new method, called LLM-Select, uses an LLM to analyze the input data and determine which features are the most relevant and informative. This can save a lot of time and effort compared to traditional feature selection techniques, which often require domain expertise and manual experimentation.
The researchers found that LLM-Select outperformed other feature selection methods on a variety of benchmark datasets, demonstrating the power of leveraging LLMs for this task. They also showed how LLM-Select can be combined with other LLM-based techniques, like algorithm selection and document selection, to create even more effective machine learning pipelines.
Technical Explanation
The LLM-Select method proposed in this paper uses a large language model, such as GPT-3, to automatically engineer and select the most relevant features for a given machine learning task. The process involves several steps:
- Feature Extraction: The LLM is used to extract semantic and contextual features from the input data, generating a rich representation of the information.
- Feature Scoring: The LLM then scores each feature based on its relevance and importance to the target task, using techniques like large language model enhanced machine learning estimators.
- Feature Selection: The highest-scoring features are selected, and a machine learning model is trained using only these important features.
The authors evaluated LLM-Select on a variety of benchmark datasets and compared its performance to traditional feature selection techniques, such as Bayesian statistical modeling of predictors from LLMs. The results showed that LLM-Select consistently outperformed the other methods, demonstrating the power of leveraging LLMs for this task.
Critical Analysis
The authors acknowledge that the performance of LLM-Select may be influenced by the specific LLM used, its pre-training data, and the hyperparameters of the feature scoring and selection processes. They suggest that further research is needed to better understand the optimal LLM architecture and training regime for different types of feature engineering tasks.
Additionally, the paper does not address the computational and memory requirements of LLM-Select, which could be a significant limitation for large-scale or real-time applications. The authors also do not discuss the interpretability and explainability of the features selected by the LLM, which is an important consideration for many machine learning use cases.
Overall, the LLM-Select method presents a promising approach to leveraging the power of large language models for feature engineering and selection. However, the practical deployment of this technique may require further refinements and careful consideration of its limitations and potential biases.
Conclusion
This paper introduces LLM-Select, a novel feature selection method that uses large language models to automatically engineer and select the most relevant features for machine learning tasks. The authors demonstrate that LLM-Select outperforms traditional feature selection techniques, highlighting the potential of LLMs to enhance the feature engineering process.
The integration of LLM-Select with other LLM-based techniques, such as algorithm selection and document selection, suggests that these powerful AI systems can be combined to create highly effective machine learning pipelines. As the field of large language models continues to evolve, the insights and methods presented in this paper may pave the way for further advancements in automated feature engineering and selection, with far-reaching applications across a variety of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LLM-Select: Feature Selection with Large Language Models
Daniel P. Jeong, Zachary C. Lipton, Pradeep Ravikumar
In this paper, we demonstrate a surprising capability of large language models (LLMs): given only input feature names and a description of a prediction task, they are capable of selecting the most predictive features, with performance rivaling the standard tools of data science. Remarkably, these models exhibit this capacity across various query mechanisms. For example, we zero-shot prompt an LLM to output a numerical importance score for a feature (e.g., blood pressure) in predicting an outcome of interest (e.g., heart failure), with no additional context. In particular, we find that the latest models, such as GPT-4, can consistently identify the most predictive features regardless of the query mechanism and across various prompting strategies. We illustrate these findings through extensive experiments on real-world data, where we show that LLM-based feature selection consistently achieves strong performance competitive with data-driven methods such as the LASSO, despite never having looked at the downstream training data. Our findings suggest that LLMs may be useful not only for selecting the best features for training but also for deciding which features to collect in the first place. This could potentially benefit practitioners in domains like healthcare, where collecting high-quality data comes at a high cost.
Read more7/4/2024

0
Exploring Large Language Models for Feature Selection: A Data-centric Perspective
Dawei Li, Zhen Tan, Huan Liu
The rapid advancement of Large Language Models (LLMs) has significantly influenced various domains, leveraging their exceptional few-shot and zero-shot learning capabilities. In this work, we aim to explore and understand the LLMs-based feature selection methods from a data-centric perspective. We begin by categorizing existing feature selection methods with LLMs into two groups: data-driven feature selection which requires samples values to do statistical inference and text-based feature selection which utilizes prior knowledge of LLMs to do semantical associations using descriptive context. We conduct extensive experiments in both classification and regression tasks with LLMs in various sizes (e.g., GPT-4, ChatGPT and LLaMA-2). Our findings emphasize the effectiveness and robustness of text-based feature selection methods and showcase their potentials using a real-world medical application. We also discuss the challenges and future opportunities in employing LLMs for feature selection, offering insights for further research and development in this emerging field.
Read more8/23/2024

0
SelectLLM: Query-Aware Efficient Selection Algorithm for Large Language Models
Kaushal Kumar Maurya, KV Aditya Srivatsa, Ekaterina Kochmar
Large language models (LLMs) have gained increased popularity due to their remarkable success across various tasks, which has led to the active development of a large set of diverse LLMs. However, individual LLMs have limitations when applied to complex tasks because of such factors as training biases, model sizes, and the datasets used. A promising approach is to efficiently harness the diverse capabilities of LLMs to overcome these individual limitations. Towards this goal, we introduce a novel LLM selection algorithm called SelectLLM. This algorithm directs input queries to the most suitable subset of LLMs from a large pool, ensuring they collectively provide the correct response efficiently. SelectLLM uses a multi-label classifier, utilizing the classifier's predictions and confidence scores to design optimal policies for selecting an optimal, query-aware, and lightweight subset of LLMs. Our findings show that the proposed model outperforms individual LLMs and achieves competitive performance compared to similarly sized, computationally expensive top-performing LLM subsets. Specifically, with a similarly sized top-performing LLM subset, we achieve a significant reduction in latency on two standard reasoning benchmarks: 13% lower latency for GSM8K and 70% lower latency for MMLU. Additionally, we conduct comprehensive analyses and ablation studies, which validate the robustness of the proposed model.
Read more8/19/2024
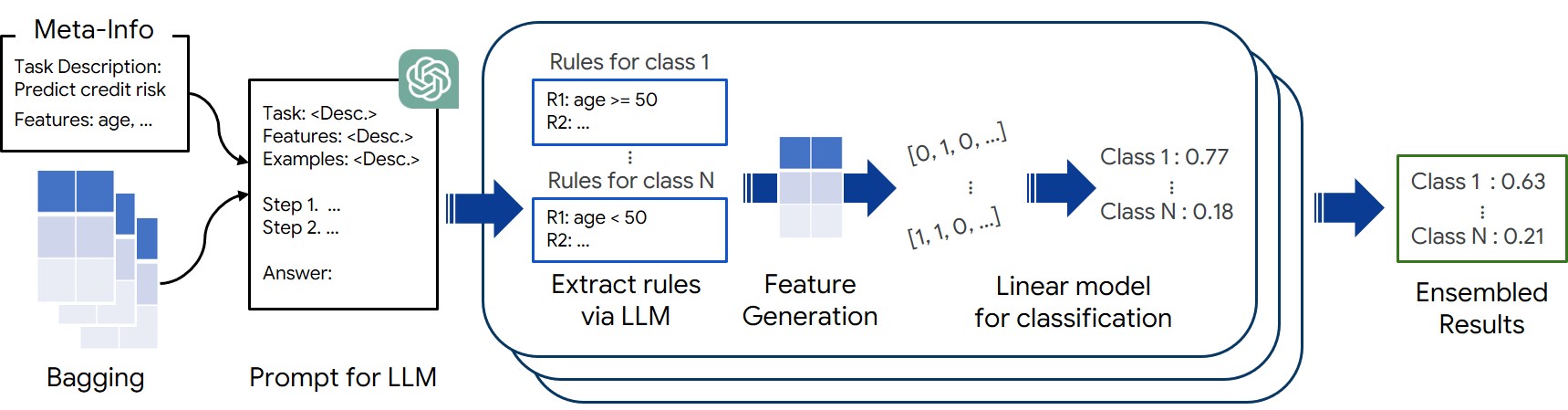
0
Large Language Models Can Automatically Engineer Features for Few-Shot Tabular Learning
Sungwon Han, Jinsung Yoon, Sercan O Arik, Tomas Pfister
Large Language Models (LLMs), with their remarkable ability to tackle challenging and unseen reasoning problems, hold immense potential for tabular learning, that is vital for many real-world applications. In this paper, we propose a novel in-context learning framework, FeatLLM, which employs LLMs as feature engineers to produce an input data set that is optimally suited for tabular predictions. The generated features are used to infer class likelihood with a simple downstream machine learning model, such as linear regression and yields high performance few-shot learning. The proposed FeatLLM framework only uses this simple predictive model with the discovered features at inference time. Compared to existing LLM-based approaches, FeatLLM eliminates the need to send queries to the LLM for each sample at inference time. Moreover, it merely requires API-level access to LLMs, and overcomes prompt size limitations. As demonstrated across numerous tabular datasets from a wide range of domains, FeatLLM generates high-quality rules, significantly (10% on average) outperforming alternatives such as TabLLM and STUNT.
Read more5/7/2024