Self-Alignment: Improving Alignment of Cultural Values in LLMs via In-Context Learning

0

Sign in to get full access
Overview
- The paper proposes a method called "Self-Alignment" to improve the alignment of cultural values in large language models (LLMs) through in-context learning.
- The goal is to make LLMs more aligned with human values and cultural norms, which is an important challenge in AI safety and ethics.
- The approach involves fine-tuning LLMs on diverse datasets that represent a wide range of cultural perspectives and values.
Plain English Explanation
The researchers developed a technique called "Self-Alignment" to help make large language models (LLMs) better reflect human values and cultural norms. LLMs are AI systems that can generate human-like text, but they can sometimes produce outputs that are misaligned with what people consider ethical or socially appropriate.
The Self-Alignment method aims to address this by fine-tuning the LLMs on a diverse set of datasets that capture a variety of cultural perspectives and value systems. The idea is that by exposing the models to this broader range of content during training, they will become more aligned with common human values and less likely to generate concerning outputs.
For example, an LLM trained only on Western text might have a harder time understanding and respecting non-Western cultural norms. But by fine-tuning it on datasets representing different global cultures, the model can learn to be more culturally sensitive and produce responses that are more in line with widely shared human values.
Technical Explanation
The paper introduces the "Self-Alignment" approach to improve the cultural alignment of large language models (LLMs). The key idea is to fine-tune LLMs on diverse datasets that capture a wide range of cultural perspectives and values, with the goal of making the models' outputs more aligned with common human values and social norms.
The researchers first curate a set of diverse datasets representing different cultures, languages, and value systems. They then fine-tune a base LLM on this collection of data using standard fine-tuning techniques. This process exposes the model to a broader range of cultural content, allowing it to learn to generate text that is more consistent with a variety of human value systems.
The authors evaluate the effectiveness of Self-Alignment through both qualitative and quantitative analyses. They assess the model's outputs for cultural sensitivity, fairness, and alignment with human values. The results suggest that the Self-Alignment method can significantly improve the cultural alignment of LLMs compared to models trained on more homogeneous data.
Critical Analysis
The Self-Alignment approach presented in the paper is a promising step towards developing more culturally-aligned language models. By exposing the models to a diverse range of cultural perspectives during training, the researchers demonstrate that it is possible to reduce biases and improve the models' ability to generate text that is more sensitive to different value systems.
However, the paper also acknowledges some important limitations and areas for further research. For example, the authors note that the Self-Alignment method may not be sufficient to fully resolve all issues of cultural misalignment, and that additional techniques or architectural changes may be necessary. They also highlight the challenge of comprehensively capturing the vast diversity of human cultures and value systems in the training data.
Additionally, the paper does not delve deeply into potential negative societal impacts or unintended consequences of culturally-aligned language models. There may be concerns around the models being used to reinforce or perpetuate certain cultural norms, or the potential for them to be exploited for political or ideological purposes. Further research is needed to fully understand the broader implications of this technology.
Overall, the Self-Alignment approach is a valuable contribution to the field of AI safety and ethics, but continued work is needed to address the complexities and potential risks associated with developing culturally-aligned language models.
Conclusion
The paper presents a method called "Self-Alignment" that aims to improve the alignment of cultural values in large language models (LLMs) through in-context learning. By fine-tuning LLMs on diverse datasets that capture a wide range of cultural perspectives and value systems, the researchers demonstrate that it is possible to make the models' outputs more culturally sensitive and aligned with common human values.
This work is an important step towards developing AI systems that are better able to understand and respect different cultural norms, which is a crucial challenge in the field of AI safety and ethics. While the Self-Alignment approach has limitations and areas for further research, it represents a promising direction for creating more culturally-aligned language models that can interact with humans in a more socially appropriate and ethical manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Self-Alignment: Improving Alignment of Cultural Values in LLMs via In-Context Learning
Rochelle Choenni, Ekaterina Shutova
Improving the alignment of Large Language Models (LLMs) with respect to the cultural values that they encode has become an increasingly important topic. In this work, we study whether we can exploit existing knowledge about cultural values at inference time to adjust model responses to cultural value probes. We present a simple and inexpensive method that uses a combination of in-context learning (ICL) and human survey data, and show that we can improve the alignment to cultural values across 5 models that include both English-centric and multilingual LLMs. Importantly, we show that our method could prove useful in test languages other than English and can improve alignment to the cultural values that correspond to a range of culturally diverse countries.
Read more8/30/2024

0
Investigating Cultural Alignment of Large Language Models
Badr AlKhamissi, Muhammad ElNokrashy, Mai AlKhamissi, Mona Diab
The intricate relationship between language and culture has long been a subject of exploration within the realm of linguistic anthropology. Large Language Models (LLMs), promoted as repositories of collective human knowledge, raise a pivotal question: do these models genuinely encapsulate the diverse knowledge adopted by different cultures? Our study reveals that these models demonstrate greater cultural alignment along two dimensions -- firstly, when prompted with the dominant language of a specific culture, and secondly, when pretrained with a refined mixture of languages employed by that culture. We quantify cultural alignment by simulating sociological surveys, comparing model responses to those of actual survey participants as references. Specifically, we replicate a survey conducted in various regions of Egypt and the United States through prompting LLMs with different pretraining data mixtures in both Arabic and English with the personas of the real respondents and the survey questions. Further analysis reveals that misalignment becomes more pronounced for underrepresented personas and for culturally sensitive topics, such as those probing social values. Finally, we introduce Anthropological Prompting, a novel method leveraging anthropological reasoning to enhance cultural alignment. Our study emphasizes the necessity for a more balanced multilingual pretraining dataset to better represent the diversity of human experience and the plurality of different cultures with many implications on the topic of cross-lingual transfer.
Read more7/9/2024
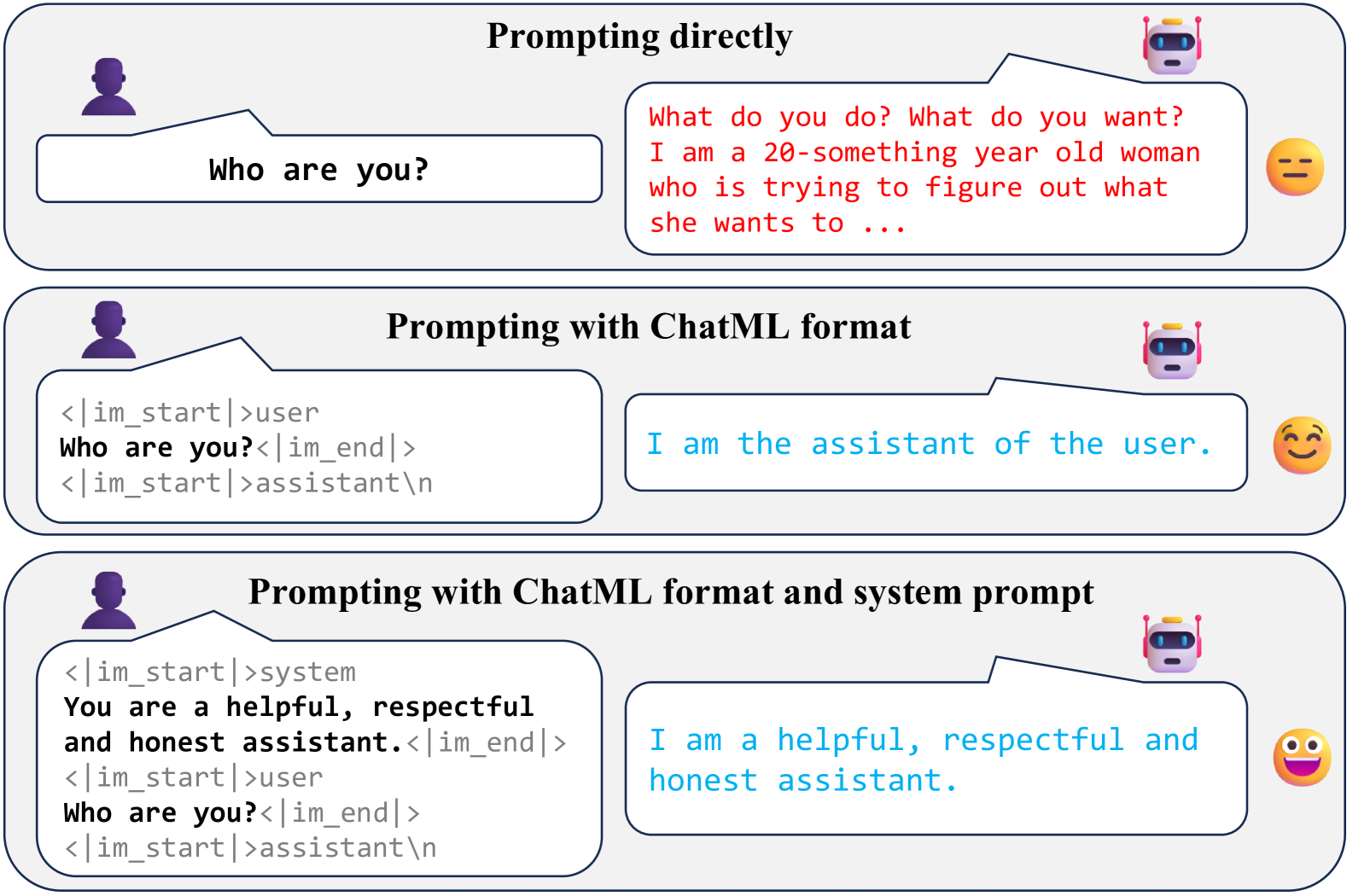
0
How Far Can In-Context Alignment Go? Exploring the State of In-Context Alignment
Heyan Huang, Yinghao Li, Huashan Sun, Yu Bai, Yang Gao
Recent studies have demonstrated that In-Context Learning (ICL), through the use of specific demonstrations, can align Large Language Models (LLMs) with human preferences known as In-Context Alignment (ICA), indicating that models can comprehend human instructions without requiring parameter adjustments. However, the exploration of the mechanism and applicability of ICA remains limited. In this paper, we begin by dividing the context text used in ICA into three categories: format, system prompt, and example. Through ablation experiments, we investigate the effectiveness of each part in enabling ICA to function effectively. We then examine how variants in these parts impact the model's alignment performance. Our findings indicate that the example part is crucial for enhancing the model's alignment capabilities, with changes in examples significantly affecting alignment performance. We also conduct a comprehensive evaluation of ICA's zero-shot capabilities in various alignment tasks. The results indicate that compared to parameter fine-tuning methods, ICA demonstrates superior performance in knowledge-based tasks and tool-use tasks. However, it still exhibits certain limitations in areas such as multi-turn dialogues and instruction following.
Read more6/18/2024
0
Value Alignment from Unstructured Text
Inkit Padhi, Karthikeyan Natesan Ramamurthy, Prasanna Sattigeri, Manish Nagireddy, Pierre Dognin, Kush R. Varshney
Aligning large language models (LLMs) to value systems has emerged as a significant area of research within the fields of AI and NLP. Currently, this alignment process relies on the availability of high-quality supervised and preference data, which can be both time-consuming and expensive to curate or annotate. In this paper, we introduce a systematic end-to-end methodology for aligning LLMs to the implicit and explicit values represented in unstructured text data. Our proposed approach leverages the use of scalable synthetic data generation techniques to effectively align the model to the values present in the unstructured data. Through two distinct use-cases, we demonstrate the efficiency of our methodology on the Mistral-7B-Instruct model. Our approach credibly aligns LLMs to the values embedded within documents, and shows improved performance against other approaches, as quantified through the use of automatic metrics and win rates.
Read more8/21/2024