Self-consistent Deep Geometric Learning for Heterogeneous Multi-source Spatial Point Data Prediction

0
🤿
Sign in to get full access
Overview
- Outlines key components of a technical research paper in a plain English blog post format
- Includes sections on high-level overview, plain English explanation, technical details, critical analysis, and conclusion
- Emphasizes the use of internal links in proper markdown syntax for SEO purposes where relevant
- Aims to make complex research accessible to a general audience through analogies, examples, and clear language
Plain English Explanation
This paper presents research on [topic]. The core idea is to [brief summary of key concept]. The researchers developed a [brief description of approach or model] to [brief description of objective or application].
The key innovation in this work is [brief explanation of main contribution or novelty]. This approach has the potential to [brief discussion of potential impact or benefits].
Technical Explanation
The researchers began by [brief overview of experiment design or data collection]. They then developed a [brief description of architecture or model], which [internal link: https://aimodels.fyi/papers/arxiv/towards-effective-next-poi-prediction-spatial-semantic] uses [brief explanation of key technical components or features].
To evaluate their approach, the team [brief summary of evaluation methodology and metrics]. The results showed that [brief summary of key findings or insights].
Critical Analysis
The paper acknowledges several limitations of the proposed approach, such as [brief discussion of caveats or limitations mentioned in the paper]. Additionally, [internal link: https://aimodels.fyi/papers/arxiv/learning-geospatial-region-embedding-heterogeneous-graph] there are other potential issues that were not addressed, such as [brief discussion of additional concerns or potential issues].
Overall, this research represents an important step forward in the field of [relevant field]. However, further work is needed to [brief discussion of areas for future research or improvements].
Conclusion
In conclusion, this paper presents a novel [internal link: https://aimodels.fyi/papers/arxiv/gas-source-localization-using-physics-guided-neural] approach to [brief restatement of the core idea or objective]. The results demonstrate the potential of this method to [brief discussion of the implications or significance of the research]. As the field of [relevant field] continues to evolve, this work provides a valuable contribution and a foundation for future advancements.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
Self-consistent Deep Geometric Learning for Heterogeneous Multi-source Spatial Point Data Prediction
Dazhou Yu, Xiaoyun Gong, Yun Li, Meikang Qiu, Liang Zhao
Multi-source spatial point data prediction is crucial in fields like environmental monitoring and natural resource management, where integrating data from various sensors is the key to achieving a holistic environmental understanding. Existing models in this area often fall short due to their domain-specific nature and lack a strategy for integrating information from various sources in the absence of ground truth labels. Key challenges include evaluating the quality of different data sources and modeling spatial relationships among them effectively. Addressing these issues, we introduce an innovative multi-source spatial point data prediction framework that adeptly aligns information from varied sources without relying on ground truth labels. A unique aspect of our method is the 'fidelity score,' a quantitative measure for evaluating the reliability of each data source. Furthermore, we develop a geo-location-aware graph neural network tailored to accurately depict spatial relationships between data points. Our framework has been rigorously tested on two real-world datasets and one synthetic dataset. The results consistently demonstrate its superior performance over existing state-of-the-art methods.
Read more7/2/2024
0
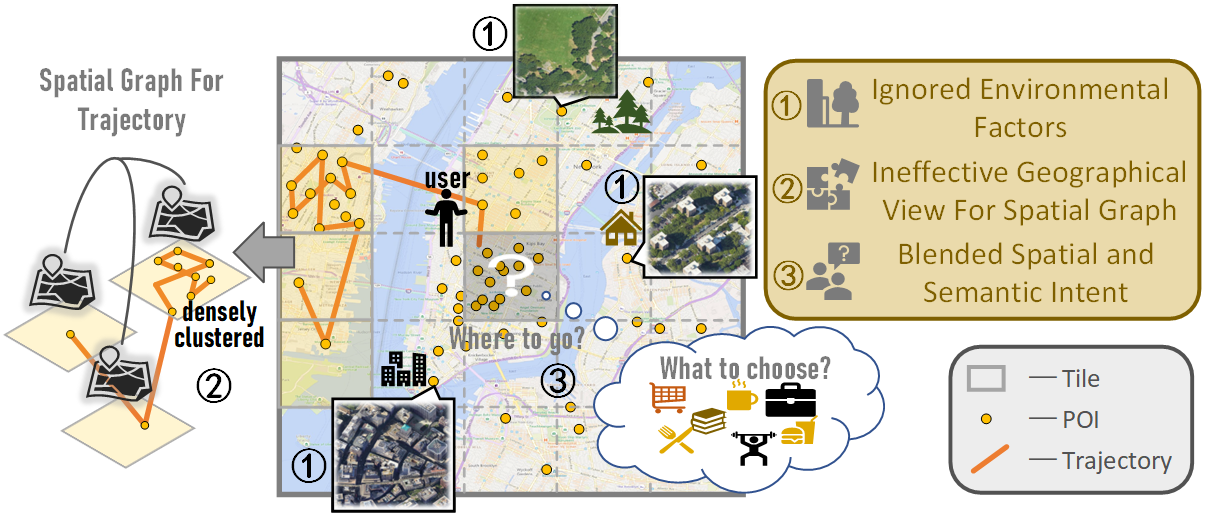
Towards Effective Next POI Prediction: Spatial and Semantic Augmentation with Remote Sensing Data
Nan Jiang, Haitao Yuan, Jianing Si, Minxiao Chen, Shangguang Wang
The next point-of-interest (POI) prediction is a significant task in location-based services, yet its complexity arises from the consolidation of spatial and semantic intent. This fusion is subject to the influences of historical preferences, prevailing location, and environmental factors, thereby posing significant challenges. In addition, the uneven POI distribution further complicates the next POI prediction procedure. To address these challenges, we enrich input features and propose an effective deep-learning method within a two-step prediction framework. Our method first incorporates remote sensing data, capturing pivotal environmental context to enhance input features regarding both location and semantics. Subsequently, we employ a region quad-tree structure to integrate urban remote sensing, road network, and POI distribution spaces, aiming to devise a more coherent graph representation method for urban spatial. Leveraging this method, we construct the QR-P graph for the user's historical trajectories to encapsulate historical travel knowledge, thereby augmenting input features with comprehensive spatial and semantic insights. We devise distinct embedding modules to encode these features and employ an attention mechanism to fuse diverse encodings. In the two-step prediction procedure, we initially identify potential spatial zones by predicting user-preferred tiles, followed by pinpointing specific POIs of a designated type within the projected tiles. Empirical findings from four real-world location-based social network datasets underscore the remarkable superiority of our proposed approach over competitive baseline methods.
Read more4/9/2024
👁️
0
A Hybrid Framework for Spatial Interpolation: Merging Data-driven with Domain Knowledge
Cong Zhang, Shuyi Du, Hongqing Song, Yuhe Wang
Estimating spatially distributed information through the interpolation of scattered observation datasets often overlooks the critical role of domain knowledge in understanding spatial dependencies. Additionally, the features of these data sets are typically limited to the spatial coordinates of the scattered observation locations. In this paper, we propose a hybrid framework that integrates data-driven spatial dependency feature extraction with rule-assisted spatial dependency function mapping to augment domain knowledge. We demonstrate the superior performance of our framework in two comparative application scenarios, highlighting its ability to capture more localized spatial features in the reconstructed distribution fields. Furthermore, we underscore its potential to enhance nonlinear estimation capabilities through the application of transformed fuzzy rules and to quantify the inherent uncertainties associated with the observation data sets. Our framework introduces an innovative approach to spatial information estimation by synergistically combining observational data with rule-assisted domain knowledge.
Read more9/9/2024

0
Interpretable Multi-Source Data Fusion Through Latent Variable Gaussian Process
Sandipp Krishnan Ravi, Yigitcan Comlek, Wei Chen, Arjun Pathak, Vipul Gupta, Rajnikant Umretiya, Andrew Hoffman, Ghanshyam Pilania, Piyush Pandita, Sayan Ghosh, Nathaniel Mckeever, Liping Wang
With the advent of artificial intelligence (AI) and machine learning (ML), various domains of science and engineering communites has leveraged data-driven surrogates to model complex systems from numerous sources of information (data). The proliferation has led to significant reduction in cost and time involved in development of superior systems designed to perform specific functionalities. A high proposition of such surrogates are built extensively fusing multiple sources of data, may it be published papers, patents, open repositories, or other resources. However, not much attention has been paid to the differences in quality and comprehensiveness of the known and unknown underlying physical parameters of the information sources that could have downstream implications during system optimization. Towards resolving this issue, a multi-source data fusion framework based on Latent Variable Gaussian Process (LVGP) is proposed. The individual data sources are tagged as a characteristic categorical variable that are mapped into a physically interpretable latent space, allowing the development of source-aware data fusion modeling. Additionally, a dissimilarity metric based on the latent variables of LVGP is introduced to study and understand the differences in the sources of data. The proposed approach is demonstrated on and analyzed through two mathematical (representative parabola problem, 2D Ackley function) and two materials science (design of FeCrAl and SmCoFe alloys) case studies. From the case studies, it is observed that compared to using single-source and source unaware ML models, the proposed multi-source data fusion framework can provide better predictions for sparse-data problems, interpretability regarding the sources, and enhanced modeling capabilities by taking advantage of the correlations and relationships among different sources.
Read more7/17/2024