Self-Directed Synthetic Dialogues and Revisions Technical Report

0

Sign in to get full access
Overview
- The paper presents a novel approach for generating synthetic dialogues and revisions using self-directed techniques.
- It explores methods for creating more authentic and coherent multi-turn dialogues to support various downstream applications.
- The research aims to advance the state-of-the-art in conversational data generation, with potential implications for dialogue systems, task-oriented chatbots, and other language-based AI applications.
Plain English Explanation
The paper discusses a new way to generate synthetic dialogues and revisions, which are conversations and changes to those conversations that are computer-generated rather than human-written. The goal is to create more realistic and consistent multi-turn dialogues, which are conversations with multiple back-and-forth exchanges. This could be helpful for things like training conversational AI systems, chatbots, and other language-based AI applications. The researchers explored different techniques to make the generated dialogues feel more natural and coherent, which could lead to improvements in how these AI systems communicate with humans.
Technical Explanation
The paper introduces a self-directed approach for generating synthetic dialogues and revisions. The key elements of the proposed method include:
- Dialogue Generation: The researchers developed models to automatically generate multi-turn dialogues, drawing inspiration from techniques like state transition graphs and raw text generation.
- Dialogue Revision: The generated dialogues are then revised and refined through an iterative process, allowing the models to enhance the authenticity and coherence of the conversations.
- Self-Directed Learning: The models are trained in a self-supervised manner, using the generated and revised dialogues as training data to continuously improve their performance.
Through extensive experimentation, the researchers demonstrate the efficacy of their approach in producing more natural and coherent synthetic dialogues, which can benefit a variety of language-based AI applications.
Critical Analysis
The paper presents a promising approach for generating high-quality synthetic dialogues, but it also acknowledges several limitations and areas for further research:
- The self-directed nature of the dialogue generation and revision process may introduce biases or systematic errors that could limit the diversity and realism of the generated conversations.
- The paper does not provide a comprehensive evaluation of the generated dialogues' quality, and additional human-centered assessments may be necessary to fully understand the strengths and weaknesses of the approach.
- The researchers suggest exploring ways to incorporate external knowledge sources or task-specific constraints to further improve the relevance and coherence of the synthetic dialogues.
Conclusion
This research represents a significant advancement in the field of conversational data generation, with the potential to enhance the capabilities of various language-based AI applications. By developing a self-directed approach for generating and refining synthetic dialogues, the researchers have taken an important step towards creating more authentic and coherent multi-turn conversations. While the work has some limitations, the insights and techniques presented in the paper could inspire further research and lead to tangible improvements in the way AI systems communicate with humans.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Self-Directed Synthetic Dialogues and Revisions Technical Report
Nathan Lambert, Hailey Schoelkopf, Aaron Gokaslan, Luca Soldaini, Valentina Pyatkin, Louis Castricato
Synthetic data has become an important tool in the fine-tuning of language models to follow instructions and solve complex problems. Nevertheless, the majority of open data to date is often lacking multi-turn data and collected on closed models, limiting progress on advancing open fine-tuning methods. We introduce Self Directed Synthetic Dialogues (SDSD), an experimental dataset consisting of guided conversations of language models talking to themselves. The dataset consists of multi-turn conversations generated with DBRX, Llama 2 70B, and Mistral Large, all instructed to follow a conversation plan generated prior to the conversation. We also explore including principles from Constitutional AI and other related works to create synthetic preference data via revisions to the final conversation turn. We hope this work encourages further exploration in multi-turn data and the use of open models for expanding the impact of synthetic data.
Read more7/29/2024
📊
0
A Survey on Recent Advances in Conversational Data Generation
Heydar Soudani, Roxana Petcu, Evangelos Kanoulas, Faegheh Hasibi
Recent advancements in conversational systems have significantly enhanced human-machine interactions across various domains. However, training these systems is challenging due to the scarcity of specialized dialogue data. Traditionally, conversational datasets were created through crowdsourcing, but this method has proven costly, limited in scale, and labor-intensive. As a solution, the development of synthetic dialogue data has emerged, utilizing techniques to augment existing datasets or convert textual resources into conversational formats, providing a more efficient and scalable approach to dataset creation. In this survey, we offer a systematic and comprehensive review of multi-turn conversational data generation, focusing on three types of dialogue systems: open domain, task-oriented, and information-seeking. We categorize the existing research based on key components like seed data creation, utterance generation, and quality filtering methods, and introduce a general framework that outlines the main principles of conversation data generation systems. Additionally, we examine the evaluation metrics and methods for assessing synthetic conversational data, address current challenges in the field, and explore potential directions for future research. Our goal is to accelerate progress for researchers and practitioners by presenting an overview of state-of-the-art methods and highlighting opportunities to further research in this area.
Read more5/24/2024
🛸
0
Multi-Document Grounded Multi-Turn Synthetic Dialog Generation
Young-Suk Lee, Chulaka Gunasekara, Danish Contractor, Ram'on Fernandez Astudillo, Radu Florian
We introduce a technique for multi-document grounded multi-turn synthetic dialog generation that incorporates three main ideas. First, we control the overall dialog flow using taxonomy-driven user queries that are generated with Chain-of-Thought (CoT) prompting. Second, we support the generation of multi-document grounded dialogs by mimicking real-world use of retrievers to update the grounding documents after every user-turn in the dialog. Third, we apply LLM-as-a-Judge to filter out queries with incorrect answers. Human evaluation of the synthetic dialog data suggests that the data is diverse, coherent, and includes mostly correct answers. Both human and automatic evaluations of answerable queries indicate that models fine-tuned on synthetic dialogs consistently out-perform those fine-tuned on existing human generated training data across four publicly available multi-turn document grounded benchmark test sets.
Read more9/19/2024
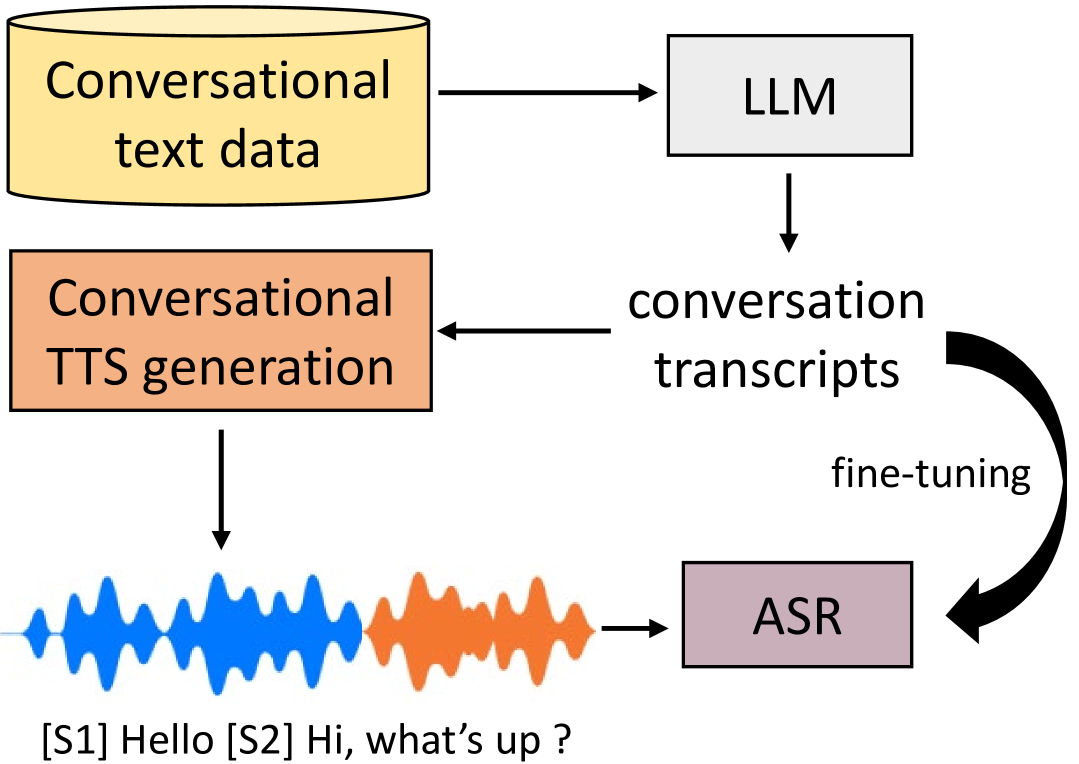
0
Generating Data with Text-to-Speech and Large-Language Models for Conversational Speech Recognition
Samuele Cornell, Jordan Darefsky, Zhiyao Duan, Shinji Watanabe
Currently, a common approach in many speech processing tasks is to leverage large scale pre-trained models by fine-tuning them on in-domain data for a particular application. Yet obtaining even a small amount of such data can be problematic, especially for sensitive domains and conversational speech scenarios, due to both privacy issues and annotation costs. To address this, synthetic data generation using single speaker datasets has been employed. Yet, for multi-speaker cases, such an approach often requires extensive manual effort and is prone to domain mismatches. In this work, we propose a synthetic data generation pipeline for multi-speaker conversational ASR, leveraging a large language model (LLM) for content creation and a conversational multi-speaker text-to-speech (TTS) model for speech synthesis. We conduct evaluation by fine-tuning the Whisper ASR model for telephone and distant conversational speech settings, using both in-domain data and generated synthetic data. Our results show that the proposed method is able to significantly outperform classical multi-speaker generation approaches that use external, non-conversational speech datasets.
Read more8/20/2024