Generating Data with Text-to-Speech and Large-Language Models for Conversational Speech Recognition

0
Sign in to get full access
Overview
- This paper investigates using text-to-speech (TTS) and large language models to generate synthetic data for conversational speech recognition.
- The researchers explore how this generated data can improve the performance of speech recognition models, especially for conversational speech.
- They conduct experiments to evaluate the effectiveness of the synthetic data compared to real speech data.
Plain English Explanation
The researchers in this study wanted to find a way to improve speech recognition models, particularly for conversational speech. One challenge with speech recognition is that it requires a lot of training data, which can be time-consuming and expensive to collect.
To address this, the researchers explored using text-to-speech (TTS) technology and large language models to generate synthetic speech data. The idea was that this synthetic data could be used to supplement the real speech data and help the speech recognition models perform better.
The researchers conducted experiments to evaluate how effective this synthetic data was compared to using just the real speech data. They looked at various metrics to see if the synthetic data led to improved speech recognition accuracy and performance.
Technical Explanation
The researchers used a TTS system and a large language model to generate synthetic speech data. They trained the speech recognition model on a combination of the real and synthetic data, and compared the performance to a model trained only on the real data.
The experiment design involved several steps:
- Collecting a dataset of real conversational speech
- Using the TTS system and language model to generate synthetic speech data
- Training speech recognition models on the real data, synthetic data, and a combination of both
- Evaluating the performance of the different models on held-out test sets
The key insights from the experiments were that the models trained on the combined real and synthetic data outperformed the models trained only on the real data. This suggests that the synthetic data was able to effectively supplement the real data and improve the speech recognition capabilities.
Critical Analysis
The paper acknowledges some limitations of the synthetic data, such as it not capturing all the nuances and variability of real human speech. The researchers also note that further research is needed to optimize the TTS and language model components to generate even more realistic synthetic data.
Additionally, the paper does not explore the potential biases that could be introduced by the synthetic data, such as not representing diverse accents or speaking styles. This is an important consideration that should be investigated in future work.
Overall, the research presents a promising approach to leveraging synthetic data to enhance speech recognition, but there are still some open challenges that need to be addressed.
Conclusion
This paper demonstrates that using text-to-speech and large language models to generate synthetic speech data can be an effective strategy for improving conversational speech recognition. The synthetic data was able to supplement the real data and lead to performance gains for the speech recognition models.
While there are some limitations to the synthetic data, this work shows the potential of combining real and generated data to overcome the challenges of obtaining large, high-quality speech datasets. Further advancements in these techniques could have significant implications for the development of more robust and accessible speech recognition systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Generating Data with Text-to-Speech and Large-Language Models for Conversational Speech Recognition
Samuele Cornell, Jordan Darefsky, Zhiyao Duan, Shinji Watanabe
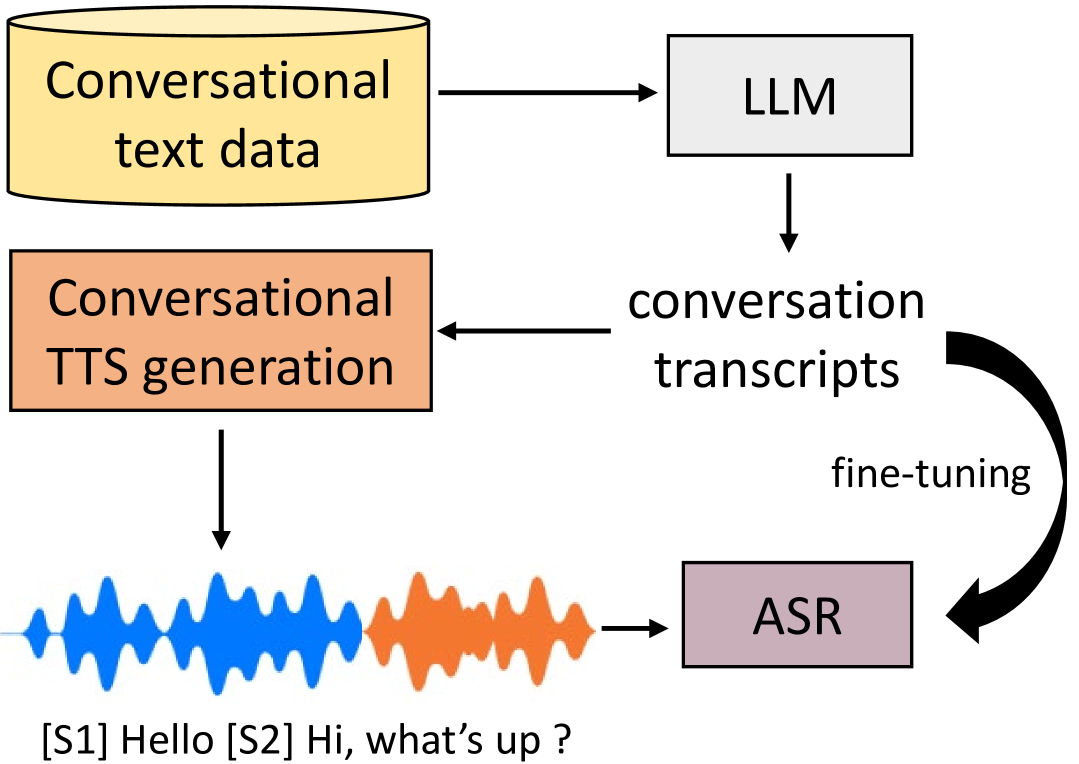
Currently, a common approach in many speech processing tasks is to leverage large scale pre-trained models by fine-tuning them on in-domain data for a particular application. Yet obtaining even a small amount of such data can be problematic, especially for sensitive domains and conversational speech scenarios, due to both privacy issues and annotation costs. To address this, synthetic data generation using single speaker datasets has been employed. Yet, for multi-speaker cases, such an approach often requires extensive manual effort and is prone to domain mismatches. In this work, we propose a synthetic data generation pipeline for multi-speaker conversational ASR, leveraging a large language model (LLM) for content creation and a conversational multi-speaker text-to-speech (TTS) model for speech synthesis. We conduct evaluation by fine-tuning the Whisper ASR model for telephone and distant conversational speech settings, using both in-domain data and generated synthetic data. Our results show that the proposed method is able to significantly outperform classical multi-speaker generation approaches that use external, non-conversational speech datasets.
Read more8/20/2024
📊
0
Instruction Data Generation and Unsupervised Adaptation for Speech Language Models
Vahid Noroozi, Zhehuai Chen, Somshubra Majumdar, Steve Huang, Jagadeesh Balam, Boris Ginsburg
In this paper, we propose three methods for generating synthetic samples to train and evaluate multimodal large language models capable of processing both text and speech inputs. Addressing the scarcity of samples containing both modalities, synthetic data generation emerges as a crucial strategy to enhance the performance of such systems and facilitate the modeling of cross-modal relationships between the speech and text domains. Our process employs large language models to generate textual components and text-to-speech systems to generate speech components. The proposed methods offer a practical and effective means to expand the training dataset for these models. Experimental results show progress in achieving an integrated understanding of text and speech. We also highlight the potential of using unlabeled speech data to generate synthetic samples comparable in quality to those with available transcriptions, enabling the expansion of these models to more languages.
Read more6/21/2024
0
A Framework for Synthetic Audio Conversations Generation using Large Language Models
Kaung Myat Kyaw, Jonathan Hoyin Chan
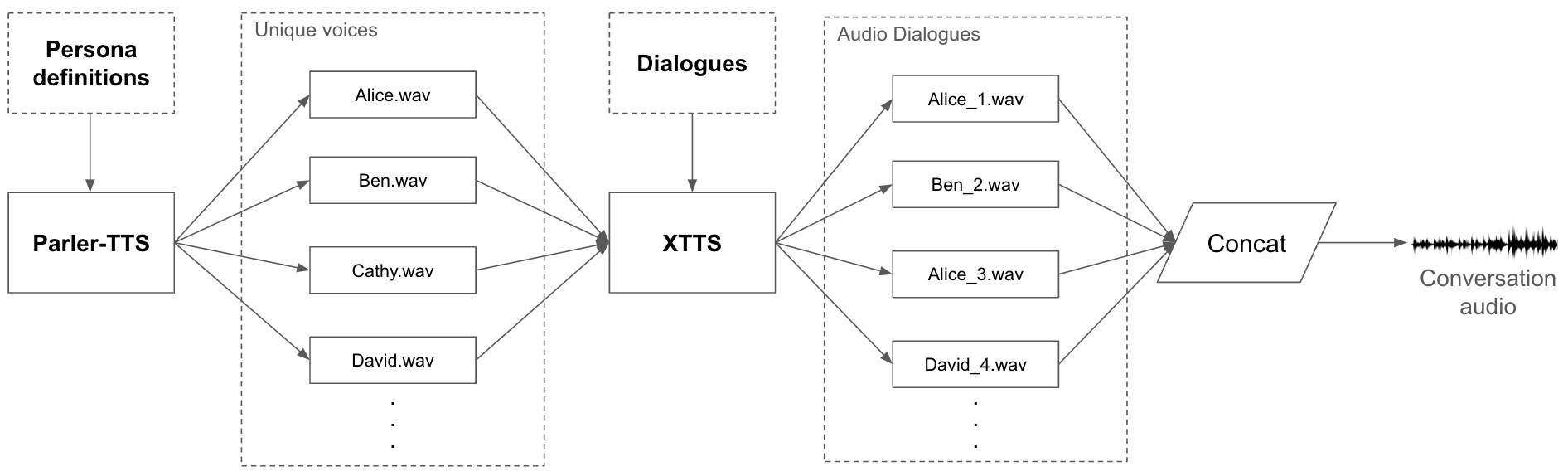
In this paper, we introduce ConversaSynth, a framework designed to generate synthetic conversation audio using large language models (LLMs) with multiple persona settings. The framework first creates diverse and coherent text-based dialogues across various topics, which are then converted into audio using text-to-speech (TTS) systems. Our experiments demonstrate that ConversaSynth effectively generates highquality synthetic audio datasets, which can significantly enhance the training and evaluation of models for audio tagging, audio classification, and multi-speaker speech recognition. The results indicate that the synthetic datasets generated by ConversaSynth exhibit substantial diversity and realism, making them suitable for developing robust, adaptable audio-based AI systems.
Read more9/4/2024
0
New!Large Language Model Can Transcribe Speech in Multi-Talker Scenarios with Versatile Instructions
Lingwei Meng, Shujie Hu, Jiawen Kang, Zhaoqing Li, Yuejiao Wang, Wenxuan Wu, Xixin Wu, Xunying Liu, Helen Meng
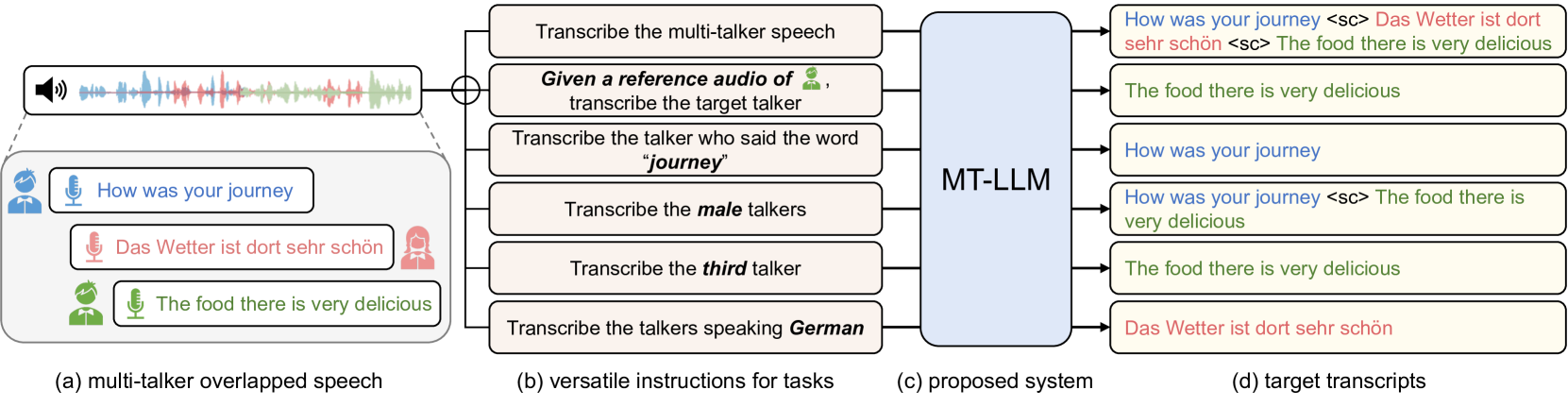
Recent advancements in large language models (LLMs) have revolutionized various domains, bringing significant progress and new opportunities. Despite progress in speech-related tasks, LLMs have not been sufficiently explored in multi-talker scenarios. In this work, we present a pioneering effort to investigate the capability of LLMs in transcribing speech in multi-talker environments, following versatile instructions related to multi-talker automatic speech recognition (ASR), target talker ASR, and ASR based on specific talker attributes such as sex, occurrence order, language, and keyword spoken. Our approach utilizes WavLM and Whisper encoder to extract multi-faceted speech representations that are sensitive to speaker characteristics and semantic context. These representations are then fed into an LLM fine-tuned using LoRA, enabling the capabilities for speech comprehension and transcription. Comprehensive experiments reveal the promising performance of our proposed system, MT-LLM, in cocktail party scenarios, highlighting the potential of LLM to handle speech-related tasks based on user instructions in such complex settings.
Read more9/16/2024