Self-distilled Dynamic Fusion Network for Language-based Fashion Retrieval

0
Sign in to get full access
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
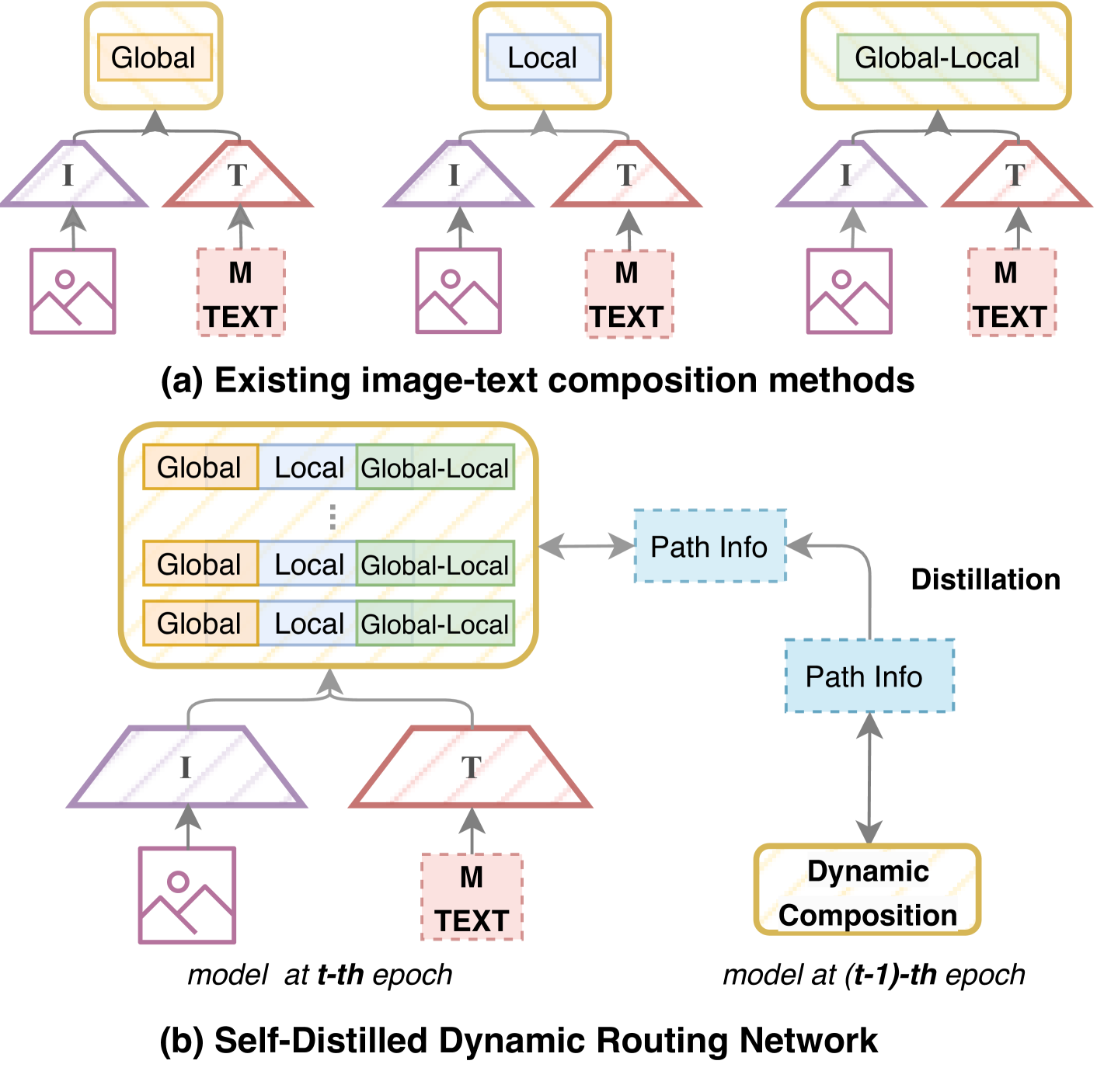
Self-distilled Dynamic Fusion Network for Language-based Fashion Retrieval
Yiming Wu, Hangfei Li, Fangfang Wang, Yilong Zhang, Ronghua Liang
In the domain of language-based fashion image retrieval, pinpointing the desired fashion item using both a reference image and its accompanying textual description is an intriguing challenge. Existing approaches lean heavily on static fusion techniques, intertwining image and text. Despite their commendable advancements, these approaches are still limited by a deficiency in flexibility. In response, we propose a Self-distilled Dynamic Fusion Network to compose the multi-granularity features dynamically by considering the consistency of routing path and modality-specific information simultaneously. Two new modules are included in our proposed method: (1) Dynamic Fusion Network with Modality Specific Routers. The dynamic network enables a flexible determination of the routing for each reference image and modification text, taking into account their distinct semantics and distributions. (2) Self Path Distillation Loss. A stable path decision for queries benefits the optimization of feature extraction as well as routing, and we approach this by progressively refine the path decision with previous path information. Extensive experiments demonstrate the effectiveness of our proposed model compared to existing methods.
Read more5/27/2024

0
Image Captioning via Dynamic Path Customization
Yiwei Ma, Jiayi Ji, Xiaoshuai Sun, Yiyi Zhou, Xiaopeng Hong, Yongjian Wu, Rongrong Ji
This paper explores a novel dynamic network for vision and language tasks, where the inferring structure is customized on the fly for different inputs. Most previous state-of-the-art approaches are static and hand-crafted networks, which not only heavily rely on expert knowledge, but also ignore the semantic diversity of input samples, therefore resulting in suboptimal performance. To address these issues, we propose a novel Dynamic Transformer Network (DTNet) for image captioning, which dynamically assigns customized paths to different samples, leading to discriminative yet accurate captions. Specifically, to build a rich routing space and improve routing efficiency, we introduce five types of basic cells and group them into two separate routing spaces according to their operating domains, i.e., spatial and channel. Then, we design a Spatial-Channel Joint Router (SCJR), which endows the model with the capability of path customization based on both spatial and channel information of the input sample. To validate the effectiveness of our proposed DTNet, we conduct extensive experiments on the MS-COCO dataset and achieve new state-of-the-art performance on both the Karpathy split and the online test server.
Read more6/4/2024

0
UniFashion: A Unified Vision-Language Model for Multimodal Fashion Retrieval and Generation
Xiangyu Zhao, Yuehan Zhang, Wenlong Zhang, Xiao-Ming Wu
The fashion domain encompasses a variety of real-world multimodal tasks, including multimodal retrieval and multimodal generation. The rapid advancements in artificial intelligence generated content, particularly in technologies like large language models for text generation and diffusion models for visual generation, have sparked widespread research interest in applying these multimodal models in the fashion domain. However, tasks involving embeddings, such as image-to-text or text-to-image retrieval, have been largely overlooked from this perspective due to the diverse nature of the multimodal fashion domain. And current research on multi-task single models lack focus on image generation. In this work, we present UniFashion, a unified framework that simultaneously tackles the challenges of multimodal generation and retrieval tasks within the fashion domain, integrating image generation with retrieval tasks and text generation tasks. UniFashion unifies embedding and generative tasks by integrating a diffusion model and LLM, enabling controllable and high-fidelity generation. Our model significantly outperforms previous single-task state-of-the-art models across diverse fashion tasks, and can be readily adapted to manage complex vision-language tasks. This work demonstrates the potential learning synergy between multimodal generation and retrieval, offering a promising direction for future research in the fashion domain. The source code is available at https://github.com/xiangyu-mm/UniFashion.
Read more8/22/2024

0
MMDRFuse: Distilled Mini-Model with Dynamic Refresh for Multi-Modality Image Fusion
Yanglin Deng, Tianyang Xu, Chunyang Cheng, Xiao-Jun Wu, Josef Kittler
In recent years, Multi-Modality Image Fusion (MMIF) has been applied to many fields, which has attracted many scholars to endeavour to improve the fusion performance. However, the prevailing focus has predominantly been on the architecture design, rather than the training strategies. As a low-level vision task, image fusion is supposed to quickly deliver output images for observation and supporting downstream tasks. Thus, superfluous computational and storage overheads should be avoided. In this work, a lightweight Distilled Mini-Model with a Dynamic Refresh strategy (MMDRFuse) is proposed to achieve this objective. To pursue model parsimony, an extremely small convolutional network with a total of 113 trainable parameters (0.44 KB) is obtained by three carefully designed supervisions. First, digestible distillation is constructed by emphasising external spatial feature consistency, delivering soft supervision with balanced details and saliency for the target network. Second, we develop a comprehensive loss to balance the pixel, gradient, and perception clues from the source images. Third, an innovative dynamic refresh training strategy is used to collaborate history parameters and current supervision during training, together with an adaptive adjust function to optimise the fusion network. Extensive experiments on several public datasets demonstrate that our method exhibits promising advantages in terms of model efficiency and complexity, with superior performance in multiple image fusion tasks and downstream pedestrian detection application. The code of this work is publicly available at https://github.com/yanglinDeng/MMDRFuse.
Read more8/29/2024