MMDRFuse: Distilled Mini-Model with Dynamic Refresh for Multi-Modality Image Fusion

0

Sign in to get full access
Overview
- Proposes a new multi-modality image fusion model called MMDRFuse with dynamic refresh and distillation
- Aims to address challenges in multi-modality fusion, such as balancing model complexity and performance
- Introduces feature-level distillation and dynamic refresh mechanisms to improve efficiency and robustness
Plain English Explanation
The paper presents a new approach called MMDRFuse for combining information from multiple types of images, such as visible light and infrared. This is known as multi-modality image fusion, and it can be useful for applications like surveillance, medical imaging, and autonomous vehicles.
One of the key challenges in multi-modality fusion is finding the right balance between model complexity and performance. MMDRFuse addresses this by using a "distilled mini-model" - a smaller, more efficient model that is trained to mimic the behavior of a larger, more complex model. This "feature-level distillation" helps to reduce the computational requirements of the fusion process.
Additionally, MMDRFuse incorporates a "dynamic refresh" mechanism, which allows the model to continuously update and adapt its internal representations as new data is encountered. This can help the model stay robust and accurate even as the input conditions change over time.
The researchers test MMDRFuse on several multi-modality fusion benchmarks and find that it outperforms other state-of-the-art methods in terms of both performance and efficiency.
Technical Explanation
The MMDRFuse model is designed to address the challenges of multi-modality image fusion, which involves combining information from different types of imaging sensors (e.g., visible light, infrared, depth) to create a more comprehensive and informative representation.
One of the key innovations in MMDRFuse is the use of feature-level distillation, where a smaller "mini-model" is trained to mimic the behavior of a larger, more complex fusion model. This helps to reduce the computational requirements of the fusion process without sacrificing too much performance.
The dynamic refresh mechanism in MMDRFuse allows the model to continuously update its internal representations as new data is encountered. This can help the model stay robust and accurate even as the input conditions change over time, which is important for real-world applications.
The researchers evaluate MMDRFuse on several multi-modality fusion benchmarks, including MambaFuse, Self-Distilled Dynamic Fusion Network, and Diffuser. They find that MMDRFuse outperforms other state-of-the-art methods in terms of both performance and efficiency.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the MMDRFuse model, including comparisons to several other state-of-the-art multi-modality fusion approaches. The researchers acknowledge some limitations, such as the potential for the dynamic refresh mechanism to introduce instability in certain scenarios.
Additionally, the paper does not explore the scalability of MMDRFuse to larger or more complex fusion tasks, nor does it delve into the potential ethical implications of deploying such models in sensitive applications like surveillance or medical imaging.
Further research could investigate the robustness of MMDRFuse to adversarial attacks, its performance on a wider range of fusion tasks, and the interpretability of its internal decision-making processes.
Conclusion
The MMDRFuse model presented in this paper represents an interesting and promising approach to the challenge of multi-modality image fusion. By leveraging feature-level distillation and dynamic refresh mechanisms, the researchers have developed a fusion model that is both efficient and robust, outperforming other state-of-the-art methods.
While the paper raises some interesting questions and avenues for future research, the core ideas behind MMDRFuse could have significant implications for a wide range of applications, from autonomous vehicles and medical imaging to surveillance and environmental monitoring.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MMDRFuse: Distilled Mini-Model with Dynamic Refresh for Multi-Modality Image Fusion
Yanglin Deng, Tianyang Xu, Chunyang Cheng, Xiao-Jun Wu, Josef Kittler
In recent years, Multi-Modality Image Fusion (MMIF) has been applied to many fields, which has attracted many scholars to endeavour to improve the fusion performance. However, the prevailing focus has predominantly been on the architecture design, rather than the training strategies. As a low-level vision task, image fusion is supposed to quickly deliver output images for observation and supporting downstream tasks. Thus, superfluous computational and storage overheads should be avoided. In this work, a lightweight Distilled Mini-Model with a Dynamic Refresh strategy (MMDRFuse) is proposed to achieve this objective. To pursue model parsimony, an extremely small convolutional network with a total of 113 trainable parameters (0.44 KB) is obtained by three carefully designed supervisions. First, digestible distillation is constructed by emphasising external spatial feature consistency, delivering soft supervision with balanced details and saliency for the target network. Second, we develop a comprehensive loss to balance the pixel, gradient, and perception clues from the source images. Third, an innovative dynamic refresh training strategy is used to collaborate history parameters and current supervision during training, together with an adaptive adjust function to optimise the fusion network. Extensive experiments on several public datasets demonstrate that our method exhibits promising advantages in terms of model efficiency and complexity, with superior performance in multiple image fusion tasks and downstream pedestrian detection application. The code of this work is publicly available at https://github.com/yanglinDeng/MMDRFuse.
Read more8/29/2024

0
MambaDFuse: A Mamba-based Dual-phase Model for Multi-modality Image Fusion
Zhe Li, Haiwei Pan, Kejia Zhang, Yuhua Wang, Fengming Yu
Multi-modality image fusion (MMIF) aims to integrate complementary information from different modalities into a single fused image to represent the imaging scene and facilitate downstream visual tasks comprehensively. In recent years, significant progress has been made in MMIF tasks due to advances in deep neural networks. However, existing methods cannot effectively and efficiently extract modality-specific and modality-fused features constrained by the inherent local reductive bias (CNN) or quadratic computational complexity (Transformers). To overcome this issue, we propose a Mamba-based Dual-phase Fusion (MambaDFuse) model. Firstly, a dual-level feature extractor is designed to capture long-range features from single-modality images by extracting low and high-level features from CNN and Mamba blocks. Then, a dual-phase feature fusion module is proposed to obtain fusion features that combine complementary information from different modalities. It uses the channel exchange method for shallow fusion and the enhanced Multi-modal Mamba (M3) blocks for deep fusion. Finally, the fused image reconstruction module utilizes the inverse transformation of the feature extraction to generate the fused result. Through extensive experiments, our approach achieves promising fusion results in infrared-visible image fusion and medical image fusion. Additionally, in a unified benchmark, MambaDFuse has also demonstrated improved performance in downstream tasks such as object detection. Code with checkpoints will be available after the peer-review process.
Read more4/15/2024
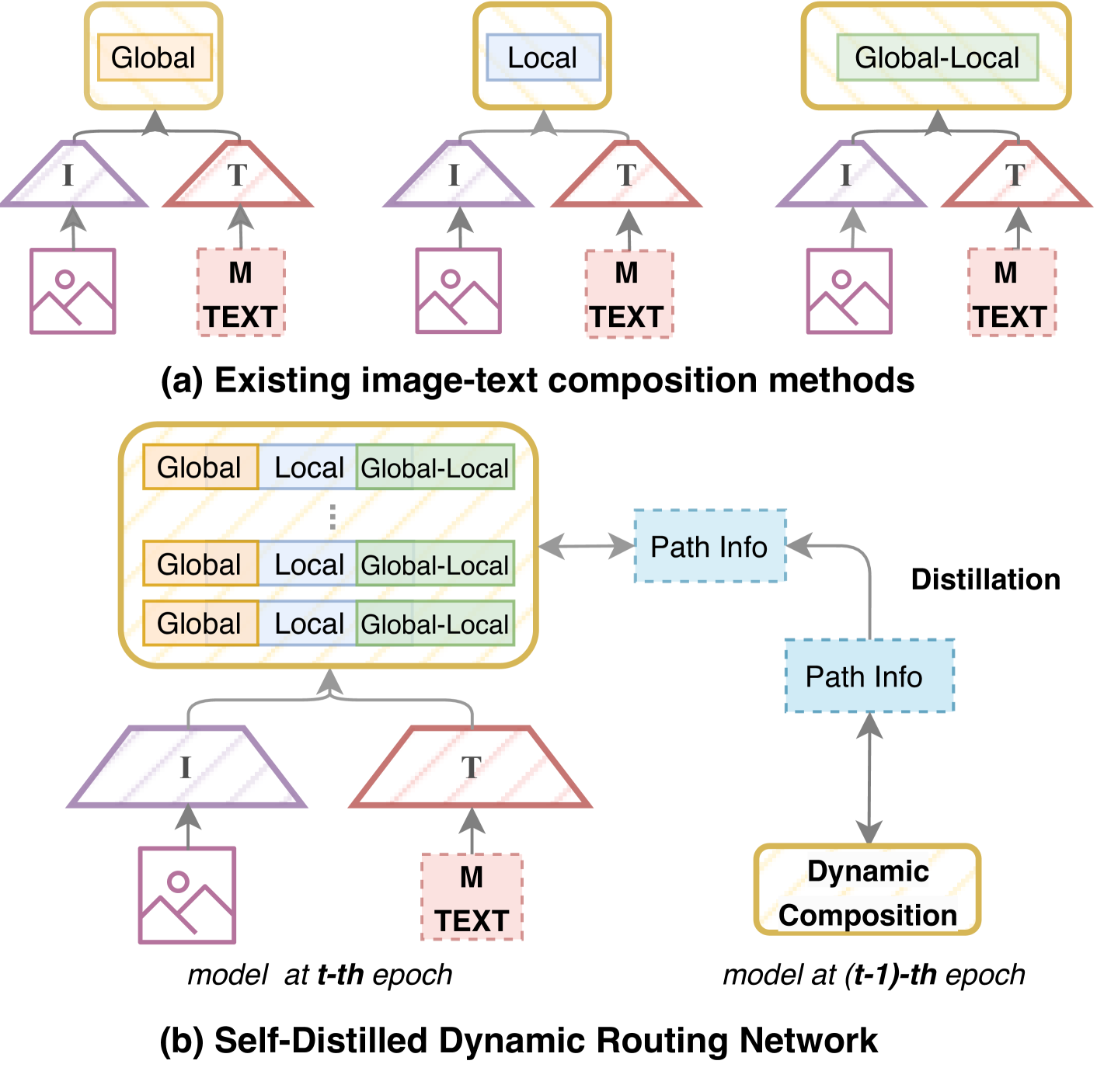
0
Self-distilled Dynamic Fusion Network for Language-based Fashion Retrieval
Yiming Wu, Hangfei Li, Fangfang Wang, Yilong Zhang, Ronghua Liang
In the domain of language-based fashion image retrieval, pinpointing the desired fashion item using both a reference image and its accompanying textual description is an intriguing challenge. Existing approaches lean heavily on static fusion techniques, intertwining image and text. Despite their commendable advancements, these approaches are still limited by a deficiency in flexibility. In response, we propose a Self-distilled Dynamic Fusion Network to compose the multi-granularity features dynamically by considering the consistency of routing path and modality-specific information simultaneously. Two new modules are included in our proposed method: (1) Dynamic Fusion Network with Modality Specific Routers. The dynamic network enables a flexible determination of the routing for each reference image and modification text, taking into account their distinct semantics and distributions. (2) Self Path Distillation Loss. A stable path decision for queries benefits the optimization of feature extraction as well as routing, and we approach this by progressively refine the path decision with previous path information. Extensive experiments demonstrate the effectiveness of our proposed model compared to existing methods.
Read more5/27/2024

0
DifFUSER: Diffusion Model for Robust Multi-Sensor Fusion in 3D Object Detection and BEV Segmentation
Duy-Tho Le, Hengcan Shi, Jianfei Cai, Hamid Rezatofighi
Diffusion models have recently gained prominence as powerful deep generative models, demonstrating unmatched performance across various domains. However, their potential in multi-sensor fusion remains largely unexplored. In this work, we introduce DifFUSER, a novel approach that leverages diffusion models for multi-modal fusion in 3D object detection and BEV map segmentation. Benefiting from the inherent denoising property of diffusion, DifFUSER is able to refine or even synthesize sensor features in case of sensor malfunction, thereby improving the quality of the fused output. In terms of architecture, our DifFUSER blocks are chained together in a hierarchical BiFPN fashion, termed cMini-BiFPN, offering an alternative architecture for latent diffusion. We further introduce a Gated Self-conditioned Modulated (GSM) latent diffusion module together with a Progressive Sensor Dropout Training (PSDT) paradigm, designed to add stronger conditioning to the diffusion process and robustness to sensor failures. Our extensive evaluations on the Nuscenes dataset reveal that DifFUSER not only achieves state-of-the-art performance with a 69.1% mIOU in BEV map segmentation tasks but also competes effectively with leading transformer-based fusion techniques in 3D object detection.
Read more4/9/2024