Self-Modifying State Modeling for Simultaneous Machine Translation
2406.02237
0
0

Abstract
Simultaneous Machine Translation (SiMT) generates target outputs while receiving stream source inputs and requires a read/write policy to decide whether to wait for the next source token or generate a new target token, whose decisions form a textit{decision path}. Existing SiMT methods, which learn the policy by exploring various decision paths in training, face inherent limitations. These methods not only fail to precisely optimize the policy due to the inability to accurately assess the individual impact of each decision on SiMT performance, but also cannot sufficiently explore all potential paths because of their vast number. Besides, building decision paths requires unidirectional encoders to simulate streaming source inputs, which impairs the translation quality of SiMT models. To solve these issues, we propose textbf{S}elf-textbf{M}odifying textbf{S}tate textbf{M}odeling (SM$^2$), a novel training paradigm for SiMT task. Without building decision paths, SM$^2$ individually optimizes decisions at each state during training. To precisely optimize the policy, SM$^2$ introduces Self-Modifying process to independently assess and adjust decisions at each state. For sufficient exploration, SM$^2$ proposes Prefix Sampling to efficiently traverse all potential states. Moreover, SM$^2$ ensures compatibility with bidirectional encoders, thus achieving higher translation quality. Experiments show that SM$^2$ outperforms strong baselines. Furthermore, SM$^2$ allows offline machine translation models to acquire SiMT ability with fine-tuning.
Create account to get full access
Overview
- This paper presents a novel approach called "Self-Modifying State Modeling" for simultaneous machine translation, which aims to improve the translation quality and latency of existing models.
- The key idea is to allow the translation model to dynamically update its internal state as it processes the input sequence, enabling it to better adapt to the evolving context.
- The authors demonstrate the effectiveness of their approach through experiments on various language pairs, showing improvements over standard seq2seq models.
Plain English Explanation
In machine translation, the goal is to take text in one language and automatically convert it into another language. This is a challenging task, especially when trying to do it in real-time or "simultaneously" as the input text is being produced.
The authors of this paper have developed a new technique called "Self-Modifying State Modeling" to address this problem. The basic idea is to allow the translation model to continuously update its internal representation or "state" as it processes the incoming text. This enables the model to better adapt to the changing context and produce higher quality translations with lower latency.
Traditionally, machine translation models have operated in a more static manner, processing the full input sequence before generating the output. By allowing the model to dynamically update its state, the authors show that it can make more informed decisions and provide better translations, especially for long or complex input sequences.
The paper demonstrates the benefits of this approach through experiments on various language pairs, showing improvements over standard sequence-to-sequence models. This represents an important advance in the field of simultaneous machine translation, with potential applications in areas like real-time captioning, interpretation, and dialogue systems.
Technical Explanation
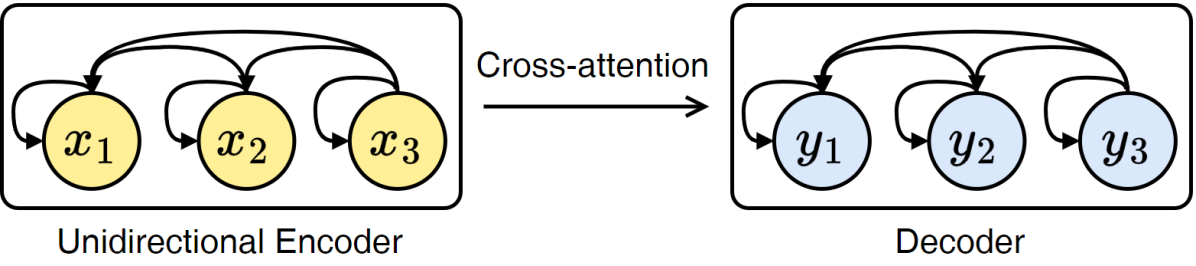
The key innovation in this paper is the "Self-Modifying State Modeling" approach, which allows the translation model to continuously update its internal representation or "state" as it processes the input sequence. This is in contrast to traditional seq2seq models, which generate the output based on a fixed encoding of the full input.
The authors achieve this by introducing a
The authors evaluate their approach on several language pairs, including Chinese-English and German-English translation tasks. They show that the Self-Modifying State Modeling technique outperforms standard seq2seq models in terms of both translation quality (as measured by BLEU scores) and latency (as measured by the average proportion of the input sequence required before generating the first output token).
The authors also provide an in-depth analysis of the self-modification mechanism, exploring how it allows the model to dynamically adjust its internal state and better adapt to the evolving context. They demonstrate that this leads to more coherent and fluent translations, particularly for longer input sequences.
Critical Analysis
The authors have presented a promising approach for improving simultaneous machine translation by allowing the model to dynamically update its internal state. This is a valuable contribution, as the ability to translate text in real-time has important applications in areas like simultaneous interpretation, speech-to-speech translation, and language learning.
That said, the authors acknowledge several limitations and areas for future work. For example, the self-modification mechanism adds computational overhead, which could impact the real-time performance of the system. Additionally, the authors only evaluate their approach on a limited set of language pairs, and it would be beneficial to see how it generalizes to a wider range of languages and domains.
Another potential area for improvement is the training process. The authors use a standard seq2seq training objective, but it may be possible to design a more targeted loss function that better encourages the desired self-modifying behavior.
Overall, the Self-Modifying State Modeling approach represents an important step forward in simultaneous machine translation. With further refinement and testing, it could lead to significant advances in the field and enable more seamless and effective cross-language communication.
Conclusion
This paper introduces a novel technique called "Self-Modifying State Modeling" for simultaneous machine translation, which allows the translation model to dynamically update its internal state as it processes the input sequence. By enabling the model to adaptively refine its understanding of the evolving context, the authors demonstrate improvements in both translation quality and latency compared to standard seq2seq models.
The key innovation is the self-modification mechanism, which modifies the model's state at each time step based on the current input, previous state, and previously generated output. This allows the model to better adapt to long or complex input sequences and produce more coherent and fluent translations.
While the authors acknowledge some limitations, such as the additional computational overhead, this work represents an important advance in the field of simultaneous machine translation. With further development and broader evaluation, the Self-Modifying State Modeling approach could have significant real-world impact, enabling more seamless and effective cross-language communication in a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
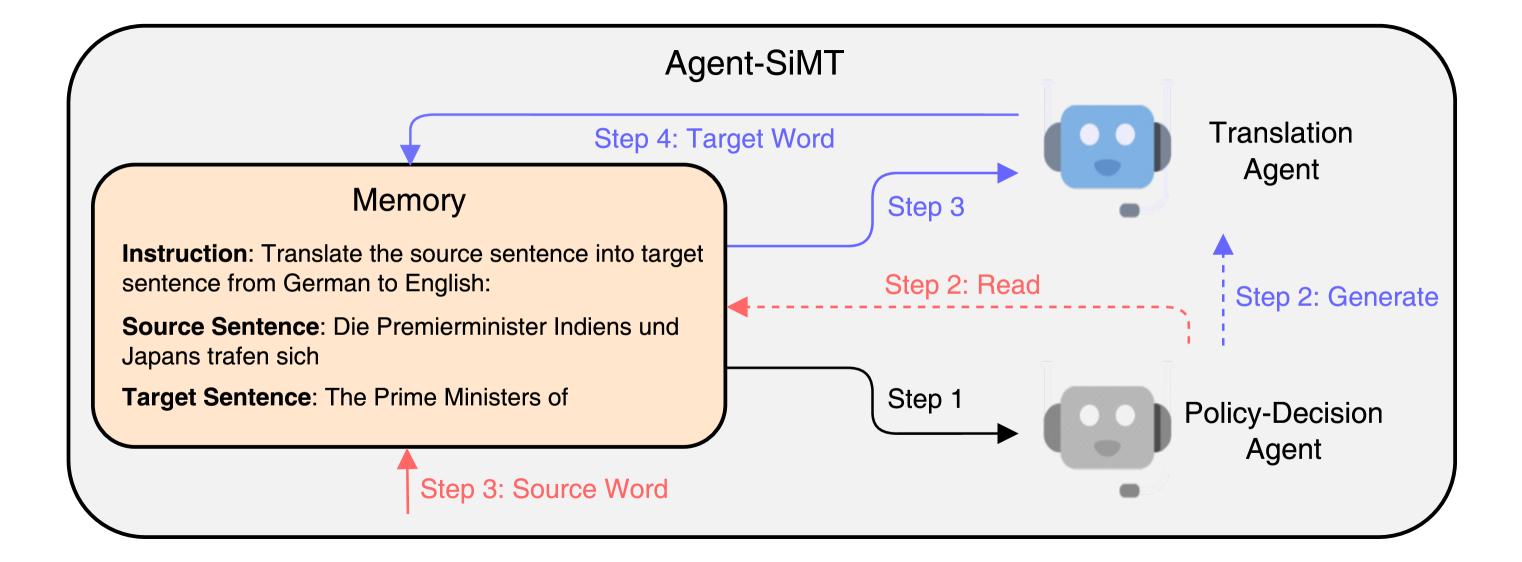
Agent-SiMT: Agent-assisted Simultaneous Machine Translation with Large Language Models
Shoutao Guo, Shaolei Zhang, Zhengrui Ma, Min Zhang, Yang Feng
0
0
Simultaneous Machine Translation (SiMT) generates target translations while reading the source sentence. It relies on a policy to determine the optimal timing for reading sentences and generating translations. Existing SiMT methods generally adopt the traditional Transformer architecture, which concurrently determines the policy and generates translations. While they excel at determining policies, their translation performance is suboptimal. Conversely, Large Language Models (LLMs), trained on extensive corpora, possess superior generation capabilities, but it is difficult for them to acquire translation policy through the training methods of SiMT. Therefore, we introduce Agent-SiMT, a framework combining the strengths of LLMs and traditional SiMT methods. Agent-SiMT contains the policy-decision agent and the translation agent. The policy-decision agent is managed by a SiMT model, which determines the translation policy using partial source sentence and translation. The translation agent, leveraging an LLM, generates translation based on the partial source sentence. The two agents collaborate to accomplish SiMT. Experiments demonstrate that Agent-SiMT attains state-of-the-art performance.
6/13/2024
Decoder-only Streaming Transformer for Simultaneous Translation
Shoutao Guo, Shaolei Zhang, Yang Feng
0
0
Simultaneous Machine Translation (SiMT) generates translation while reading source tokens, essentially producing the target prefix based on the source prefix. To achieve good performance, it leverages the relationship between source and target prefixes to exact a policy to guide the generation of translations. Although existing SiMT methods primarily focus on the Encoder-Decoder architecture, we explore the potential of Decoder-only architecture, owing to its superior performance in various tasks and its inherent compatibility with SiMT. However, directly applying the Decoder-only architecture to SiMT poses challenges in terms of training and inference. To alleviate the above problems, we propose the first Decoder-only SiMT model, named Decoder-only Streaming Transformer (DST). Specifically, DST separately encodes the positions of the source and target prefixes, ensuring that the position of the target prefix remains unaffected by the expansion of the source prefix. Furthermore, we propose a Streaming Self-Attention (SSA) mechanism tailored for the Decoder-only architecture. It is capable of obtaining translation policy by assessing the sufficiency of input source information and integrating with the soft-attention mechanism to generate translations. Experiments demonstrate that our approach achieves state-of-the-art performance on three translation tasks.
6/7/2024

Simul-LLM: A Framework for Exploring High-Quality Simultaneous Translation with Large Language Models
Victor Agostinelli, Max Wild, Matthew Raffel, Kazi Ahmed Asif Fuad, Lizhong Chen
0
0
Large language models (LLMs) with billions of parameters and pretrained on massive amounts of data are now capable of near or better than state-of-the-art performance in a variety of downstream natural language processing tasks. Neural machine translation (NMT) is one such task that LLMs have been applied to with great success. However, little research has focused on applying LLMs to the more difficult subset of NMT called simultaneous translation (SimulMT), where translation begins before the entire source context is available to the model. In this paper, we address key challenges facing LLMs fine-tuned for SimulMT, validate classical SimulMT concepts and practices in the context of LLMs, explore adapting LLMs that are fine-tuned for NMT to the task of SimulMT, and introduce Simul-LLM, the first open-source fine-tuning and evaluation pipeline development framework for LLMs focused on SimulMT.
6/6/2024

StreamSpeech: Simultaneous Speech-to-Speech Translation with Multi-task Learning
Shaolei Zhang, Qingkai Fang, Shoutao Guo, Zhengrui Ma, Min Zhang, Yang Feng
0
0
Simultaneous speech-to-speech translation (Simul-S2ST, a.k.a streaming speech translation) outputs target speech while receiving streaming speech inputs, which is critical for real-time communication. Beyond accomplishing translation between speech, Simul-S2ST requires a policy to control the model to generate corresponding target speech at the opportune moment within speech inputs, thereby posing a double challenge of translation and policy. In this paper, we propose StreamSpeech, a direct Simul-S2ST model that jointly learns translation and simultaneous policy in a unified framework of multi-task learning. Adhering to a multi-task learning approach, StreamSpeech can perform offline and simultaneous speech recognition, speech translation and speech synthesis via an All-in-One seamless model. Experiments on CVSS benchmark demonstrate that StreamSpeech achieves state-of-the-art performance in both offline S2ST and Simul-S2ST tasks. Besides, StreamSpeech is able to present high-quality intermediate results (i.e., ASR or translation results) during simultaneous translation process, offering a more comprehensive real-time communication experience.
6/6/2024